
Lead the Data Provenance Initiative. PhD @MIT. 🇨🇦 Prev: @Google Brain, Apple, Stanford. AI/ML/NLP

 Q1: Can we build a scaling law that generalizes to unseen model sizes (N), data amounts (D), AND language mixtures (M)?
Q1: Can we build a scaling law that generalizes to unseen model sizes (N), data amounts (D), AND language mixtures (M)?
 📚 Drawn from 30 diverse, permissively licensed sources (science, code, books, gov docs, news, audio transcripts & more).
📚 Drawn from 30 diverse, permissively licensed sources (science, code, books, gov docs, news, audio transcripts & more).
 🌟Motivation🌟
🌟Motivation🌟
 1️⃣ The International AI Safety Report 2025 — @Yoshua_Bengio, @privitera_, et al. — This report spans 100s of carefully curated citations from independent experts.
1️⃣ The International AI Safety Report 2025 — @Yoshua_Bengio, @privitera_, et al. — This report spans 100s of carefully curated citations from independent experts.  Crawlers are essential to our online ecosystem: they power search, price comparisons, news aggregation, security, accessibility, journalism, and research.
Crawlers are essential to our online ecosystem: they power search, price comparisons, news aggregation, security, accessibility, journalism, and research. General-purpose AI relies on massive data collected by web crawlers.
General-purpose AI relies on massive data collected by web crawlers. 
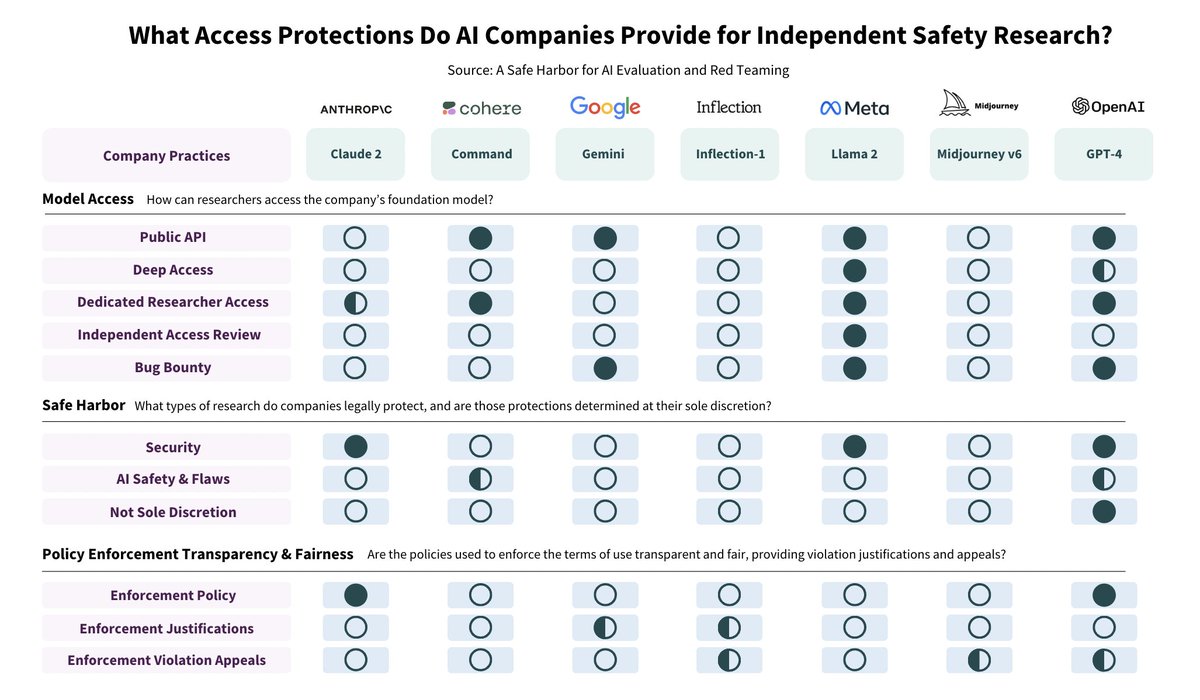 Researchers & companies agree:
Researchers & companies agree:


 It was a 🎢wild journey to teach in the midst of GPT-4 + Bard launches, moratorium letters, and raging online controversies every d*mn day.
It was a 🎢wild journey to teach in the midst of GPT-4 + Bard launches, moratorium letters, and raging online controversies every d*mn day.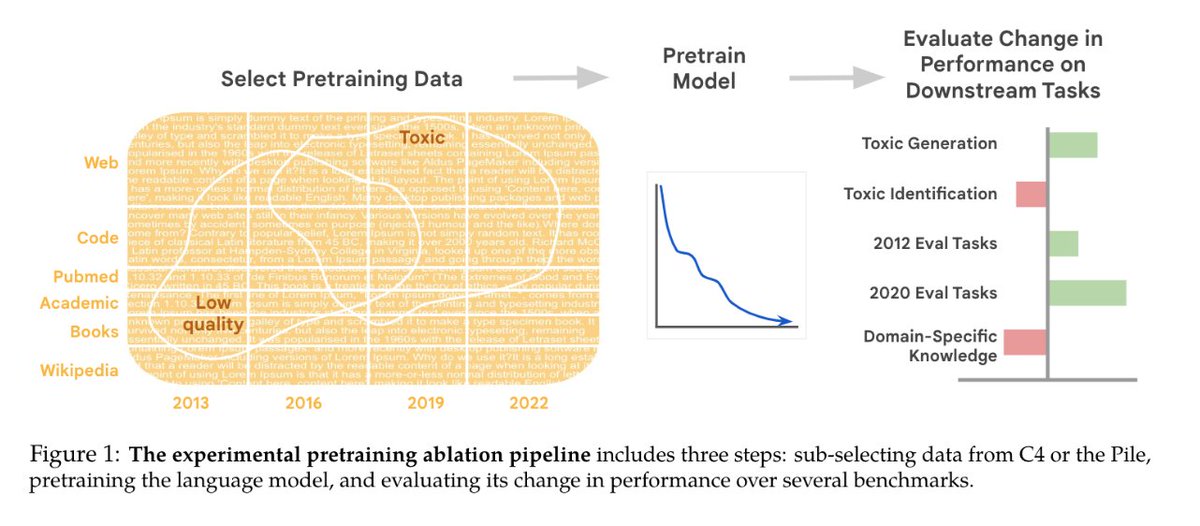 First, PT data selection is mired in mysticism.
First, PT data selection is mired in mysticism.
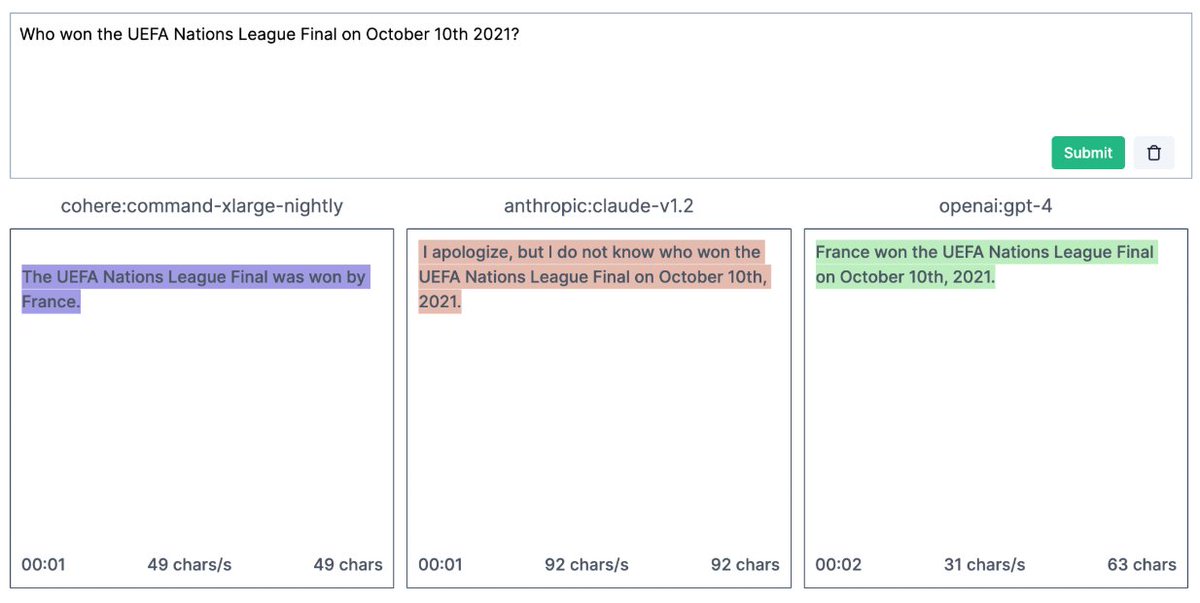 GPT4 says it is trained up to Sept 2021.
GPT4 says it is trained up to Sept 2021.



 Component 1⃣:
Component 1⃣:

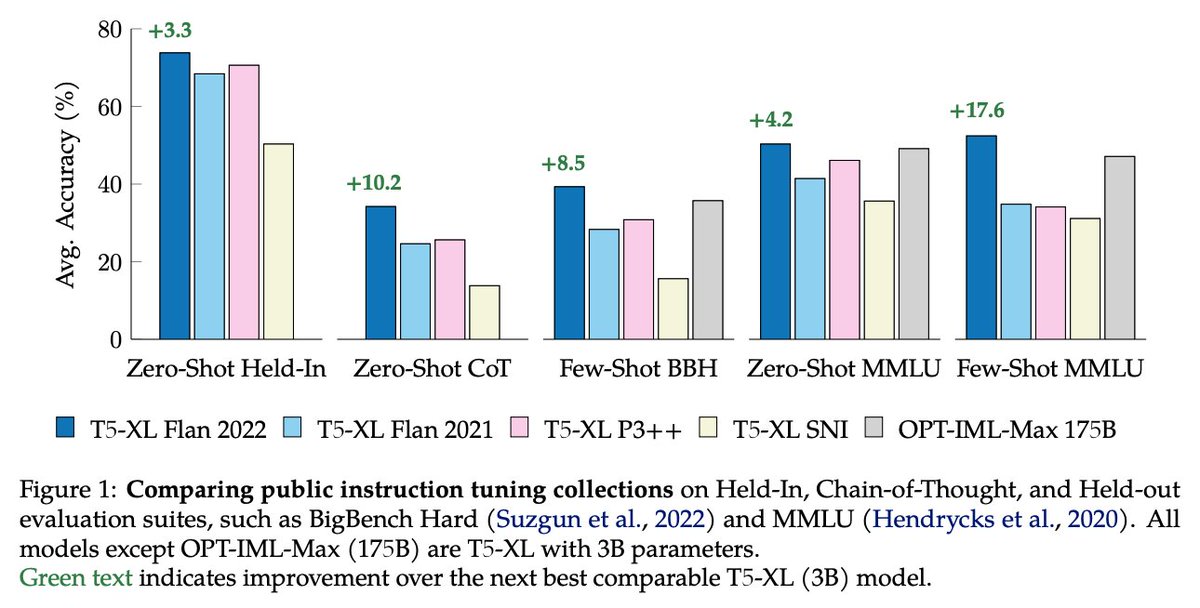 The 🌟Flan Collection🌟 (1st used in Flan-PaLM bit.ly/3Zu7bU2):
The 🌟Flan Collection🌟 (1st used in Flan-PaLM bit.ly/3Zu7bU2):
 What started as a trickle became an explosion of NLP datasets over the last few years.
What started as a trickle became an explosion of NLP datasets over the last few years. 
 🌟Task-specific finetuning 🌟
🌟Task-specific finetuning 🌟
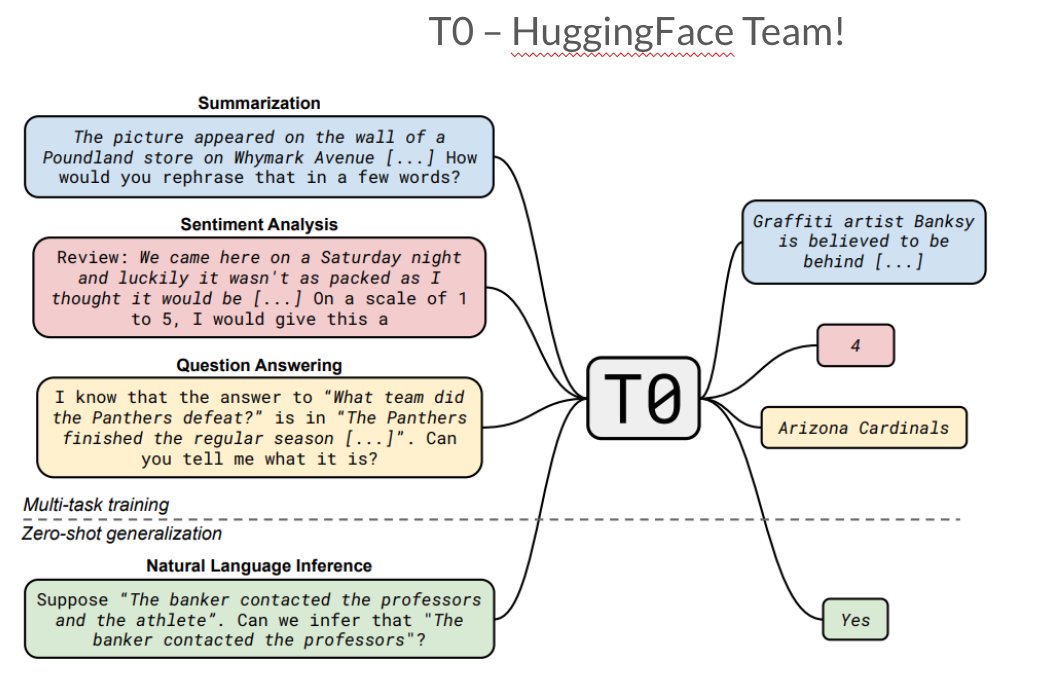 1st paper we discuss multi-task fine-tuning in FLAN by @_jasonwei, @MaartenBosma, et al.
1st paper we discuss multi-task fine-tuning in FLAN by @_jasonwei, @MaartenBosma, et al. 