
We trained a transformer called VIMA that ingests *multimodal* prompt and outputs controls for a robot arm. A single agent is able to solve visual goal, one-shot imitation from video, novel concept grounding, visual constraint, etc. Strong scaling with model capacity and data!🧵
We envision that a generalist robot agent should have an intuitive and expressive interface for task specification, but text alone is not enough. We introduce a novel multimodal prompting framework that converts a wide spectrum of robotic tasks into one sequence modeling problem. 

Our VIMA model (reads “v-eye-ma”) consists of a pre-trained T5 to encode multimodal prompts, and a transformer decoder to predict robot arm commands autoregressively. The decoder has alternating self- and cross-attention layers conditioned on the prompt.

We introduce a new benchmark, VIMA-Bench, that features 17 meta-tasks with multimodal prompt templates, which can procedurally generate 1000s of tasks. We design a protocol of 4 generalization levels to systematically evaluate the zero-shot capabilities of the robot agents.
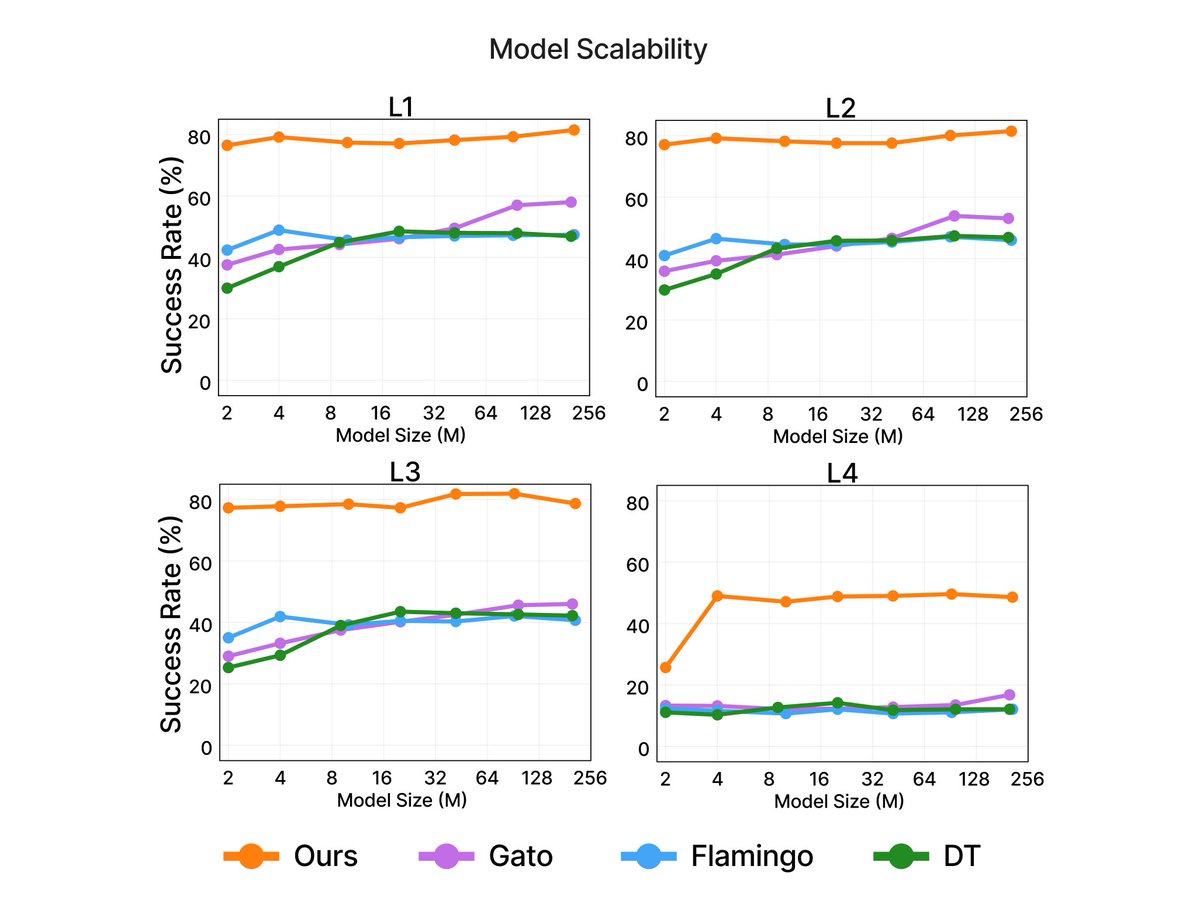
VIMA achieves strong scalability in model capacity. Across 4 generalization levels, VIMA consistently outperforms all prior methods (Gato, Flamingo, DT) ranging from 2M to 200M parameters. On the hardest novel task generalization test, it obtains up to 2.9x better performance.
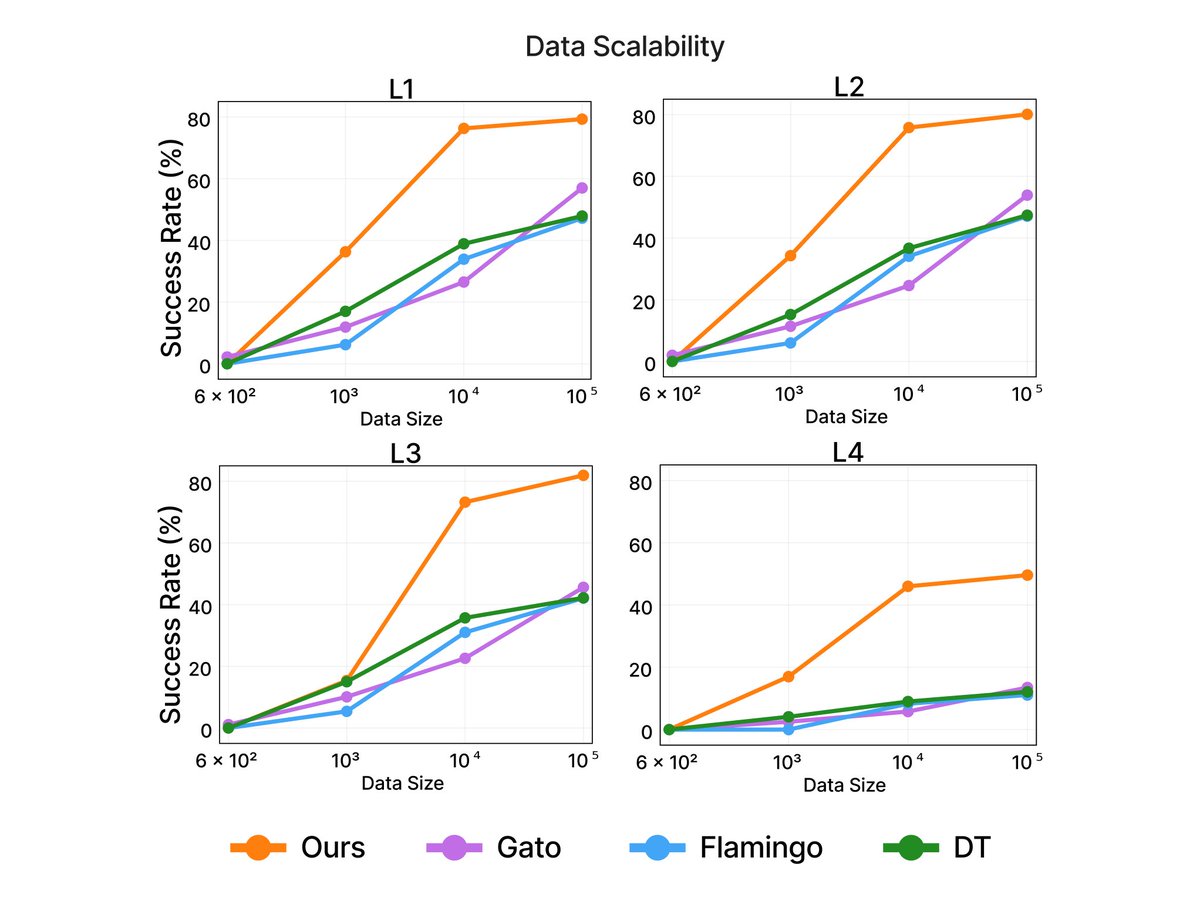
VIMA is highly sample efficient as well. With 10x less training data, it is able to attain similar performance as prior methods on average. On the hardest generalization setting, VIMA outperforms all baselines with 100x less data.
We open-source *everything*: code, pretrained models, dataset, and simulation benchmark!
🌐 Project site: vimalabs.github.io
📄 Arxiv: arxiv.org/abs/2210.03094
📄 PDF: vimalabs.github.io/assets/vima_pa…
💻 Codebases: github.com/vimalabs
🌐 Project site: vimalabs.github.io
📄 Arxiv: arxiv.org/abs/2210.03094
📄 PDF: vimalabs.github.io/assets/vima_pa…
💻 Codebases: github.com/vimalabs
Please follow our team members for project updates!
@YunfanJiang, @agrimgupta92, @zcczhang, @guanzhi_wang, @yongqiangdou, Yanjun Chen
Advisors: @drfeifei, @AnimaAnandkumar, @yukez, @DrJimFan. [END/🧵]
@YunfanJiang, @agrimgupta92, @zcczhang, @guanzhi_wang, @yongqiangdou, Yanjun Chen
Advisors: @drfeifei, @AnimaAnandkumar, @yukez, @DrJimFan. [END/🧵]

• • •
Missing some Tweet in this thread? You can try to
force a refresh



