 GR00T N1 kickstarted our open-source initiative to provide a frontier foundation for the entire robotics ecosystem to build on:
GR00T N1 kickstarted our open-source initiative to provide a frontier foundation for the entire robotics ecosystem to build on: Here's a highlight thread on the exciting research that we spearheaded!
Here's a highlight thread on the exciting research that we spearheaded!  Sharing appetizers with my distinguished guests: here are my team's research highlights!
Sharing appetizers with my distinguished guests: here are my team's research highlights!
 "An adorable minion holding a sign that says "It's over, MidJourney", spelled exactly, 3d render, typography"
"An adorable minion holding a sign that says "It's over, MidJourney", spelled exactly, 3d render, typography"

 Noam Brown's announcement @polynoamial:
Noam Brown's announcement @polynoamial:


 No-gradient architecture is the future for decision-making agents. LLM acts as a "prefrontal cortex" that orchestrates lower-level control APIs via code generation. Voyager takes the first step in Minecraft. @karpathy says it best, as always:
No-gradient architecture is the future for decision-making agents. LLM acts as a "prefrontal cortex" that orchestrates lower-level control APIs via code generation. Voyager takes the first step in Minecraft. @karpathy says it best, as always:
 NVIDIA AI Foundation, a new initiative that Jensen announced in March:
NVIDIA AI Foundation, a new initiative that Jensen announced in March: MEGABYTE from Meta AI, a multi-resolution Transformer that operates directly on raw bytes. This signals the beginning of the end of tokenization.
MEGABYTE from Meta AI, a multi-resolution Transformer that operates directly on raw bytes. This signals the beginning of the end of tokenization.
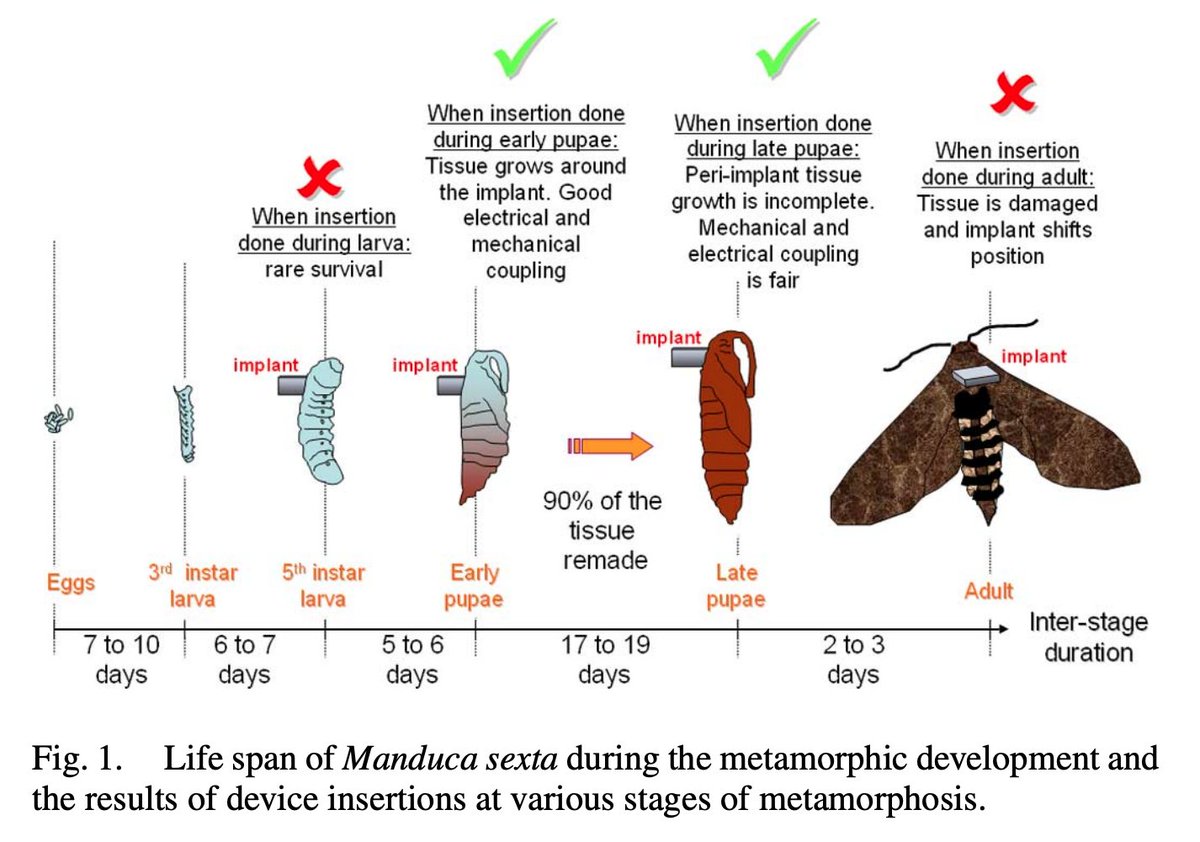 Paper: Insect–Machine Interface Based Neurocybernetics.
Paper: Insect–Machine Interface Based Neurocybernetics.
 If you only have 1 seat to follow in AI Twitter, don't give that seat to me. Give it to @karpathy.
If you only have 1 seat to follow in AI Twitter, don't give that seat to me. Give it to @karpathy. 