🎉 #StableDiffusion can be fine-tuned to generate medical images, and the outputs can be controlled using natural language text prompts!
In our latest work, we use SD to create synthetic chest xrays and insert pathologies like pleural effusions.
🧵 #Radiology #AI #StanfordAIMI
In our latest work, we use SD to create synthetic chest xrays and insert pathologies like pleural effusions.
🧵 #Radiology #AI #StanfordAIMI

#stablediffusion is a #LatentDiffusionModel and performs its generative tasks efficiently on low-dimensional representations of high-dimensional training inputs. SD's VAE latent space preserves relevant information contained in CXR; they can be reconstructed with high fidelity.

#StableDiffusion’s output can be controlled at inference time by using text prompts, but it is unclear how much medical imaging concepts SD incorporates. Simple text prompts show how hard it can be to get realistic-looking medical images out-of-the-box without specific training.

If SD’s frozen #CLIP text encoder does not include enough medical concepts to work with radiology prompts, how about switching it with a domain-specific one like PubmedBERT and projecting the embeddings? The results did not resemble CXR visually or quantitatively. Yikes!

How about teaching the model new concepts? Using #TextualInversion (@RinonGal et al.,2022), we introduce new tokens like <lungxray> and a small set of CXR. The results are visually and quantitatively better, but still far from the medical reality. ("a photo of a <lungxray>")

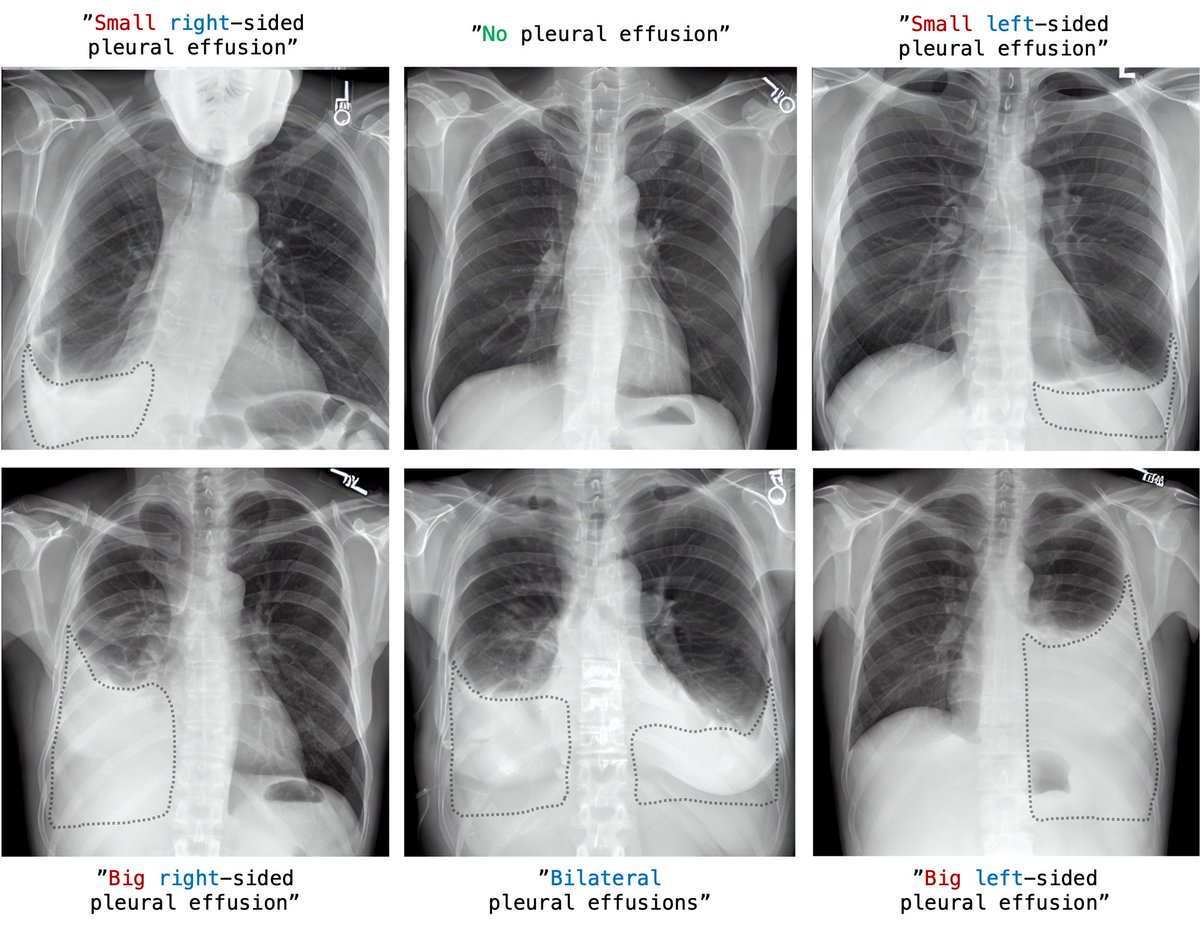
Fine-tuning the U-Net of the #StableDiffusion pipeline with a semantic prior as proposed by @natanielruizg et al. 2022 finally resulted in visually convincing chest x-rays with visible lack or presence of pleural effusion, depending on the text prompt.

Eventually we wanted to see how well a pretrained classification model trained on real CXR can do on generated data: DenseNet-121 was able to predict pleural effusions with an accuracy of 95% in the synthetic samples created with our best-looking approach.

Our work highlights the power of pretrained large multi-modal models like #StableDiffusion and gives a glimpse of how much there is to explore for the medical imaging domain! Can’t wait to test this on other modalities and pathologies to increase the diversity of the output.
This work results from working with the brillant @PierreChambon6, @Dr_ASChaudhari and @curtlanglotz at @StanfordAIMI.
It builds on the work of @robrombach, @RinonGal and @natanielruizg (and many others) and great resources @huggingface, @EMostaque and @StabilityAI are providing.
It builds on the work of @robrombach, @RinonGal and @natanielruizg (and many others) and great resources @huggingface, @EMostaque and @StabilityAI are providing.
🎉 That's it! 🎉
To read more about the project:
📝 Full preprint (arXiv): arxiv.org/abs/2210.04133
🖼️ Website with sample gallery: bit.ly/3T1MD1g
To read more about the project:
📝 Full preprint (arXiv): arxiv.org/abs/2210.04133
🖼️ Website with sample gallery: bit.ly/3T1MD1g
• • •
Missing some Tweet in this thread? You can try to
force a refresh