🐲 Ghidra Tips🐲For Beginner/Intermediate analysts interested in RE.
These tips are aimed at making Ghidra more approachable and usable for beginners and intermediate analysts 😄
[1/9] 🧵
#Malware #RE #Ghidra
These tips are aimed at making Ghidra more approachable and usable for beginners and intermediate analysts 😄
[1/9] 🧵
#Malware #RE #Ghidra




2/ The sample I'm using can be found here if you'd like to follow along. It is a cobalt strike DLL often found in Gootloader campaigns.
bazaar.abuse.ch/sample/a2513cc…
bazaar.abuse.ch/sample/a2513cc…
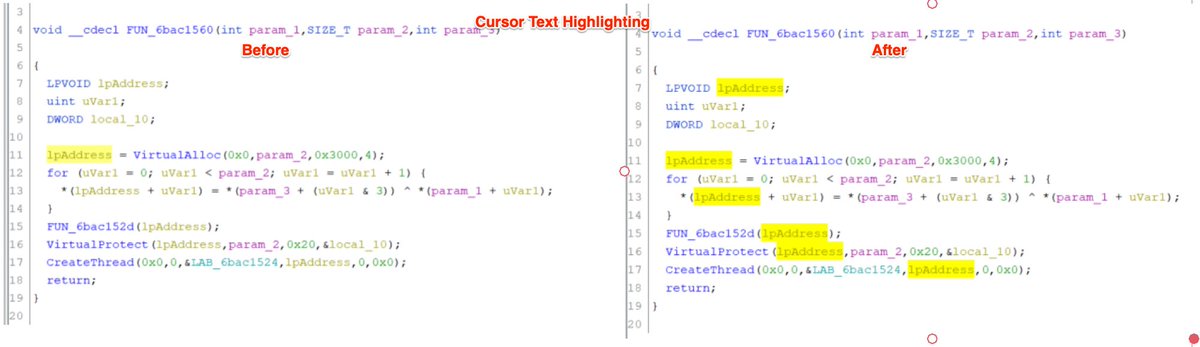
3/ Enable "Cursor Text Highlighting". 🖱️
This will automatically highlight areas of interest when using the Ghidra decompiler.
This is useful for quickly identifying where a value has or will be used.
This will automatically highlight areas of interest when using the Ghidra decompiler.
This is useful for quickly identifying where a value has or will be used.

4/ Disable print type casting. 🖨️
This removes the (VOID *) (Byte *) etc from the decompiler.
I think this results in a much more readable and python-like experience for new analysts.
(These should eventually be re-enabled when you're more comfortable with Ghidra/C)
This removes the (VOID *) (Byte *) etc from the decompiler.
I think this results in a much more readable and python-like experience for new analysts.
(These should eventually be re-enabled when you're more comfortable with Ghidra/C)



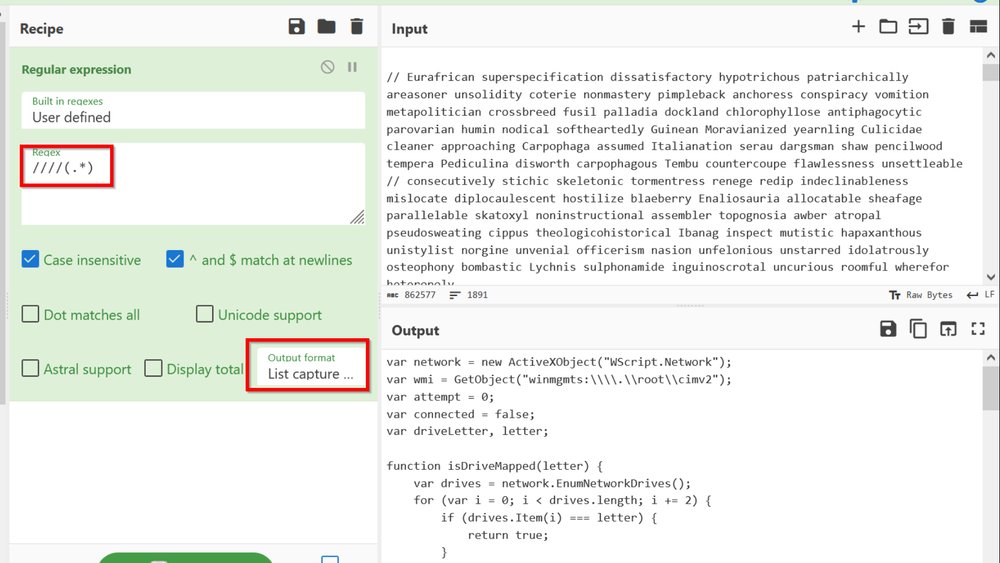
5/ Enable the entropy view 🟥
Ghidra has a not-so-obvious feature to display high entropy areas within code.
This can be used to identify sections of data that are encrypted, compressed, or otherwise obfuscated.
Ghidra has a not-so-obvious feature to display high entropy areas within code.
This can be used to identify sections of data that are encrypted, compressed, or otherwise obfuscated.



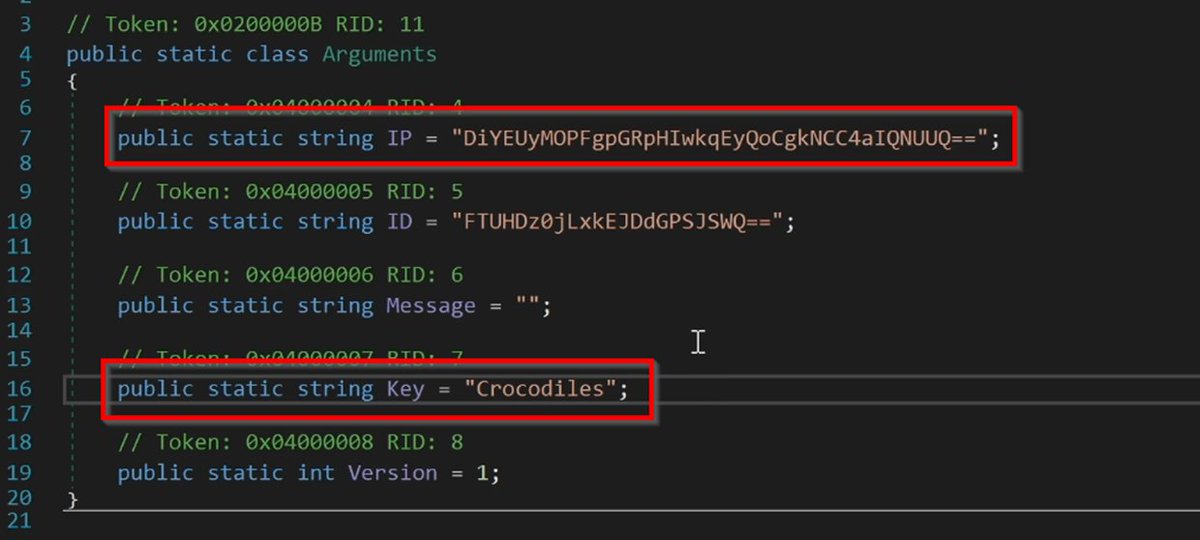
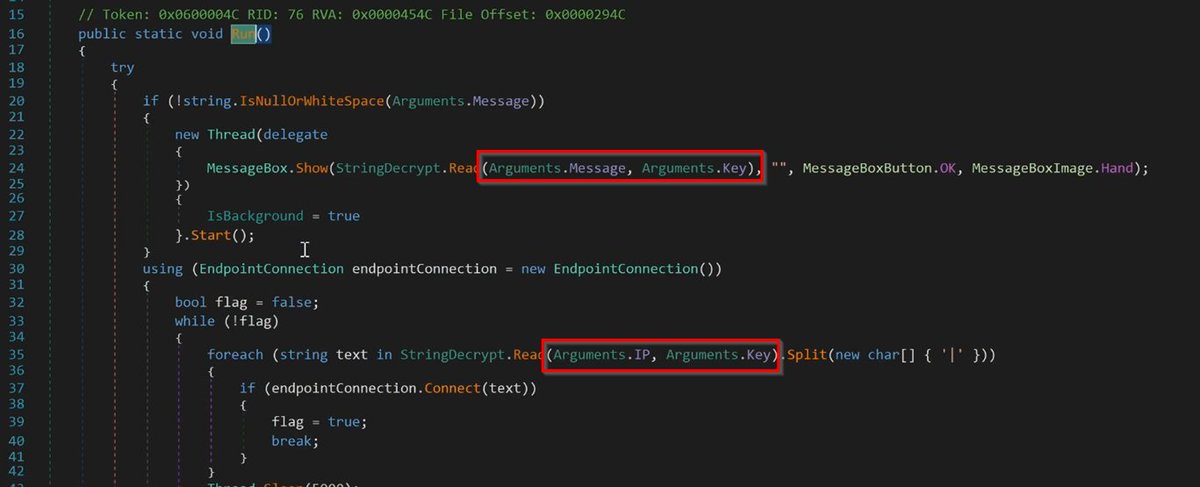
6/ Utilise Labels and X-refs. 🏷️
Once you've identified a suspicious area, make sure to check where that area starts, and where it is used.
Using the example above, you can use the entropy view (combined with labels and x-refs) to identify the associated decryption code.
Once you've identified a suspicious area, make sure to check where that area starts, and where it is used.
Using the example above, you can use the entropy view (combined with labels and x-refs) to identify the associated decryption code.



7/ Ignore the data type manager. 🤛
This is a complex feature that is largely irrelevant for those new to Ghidra/RE.
If you're a beginner, I think you can safely ignore it until you're at least comfortable with the Decompiler and other features.
This is a complex feature that is largely irrelevant for those new to Ghidra/RE.
If you're a beginner, I think you can safely ignore it until you're at least comfortable with the Decompiler and other features.

8/ Utilise X-refs from imported Functions/API's. 🕵️♂️
Check where suspicious API's are being used!
Once you've identified suspicious imports.
Make sure you utilise the x-refs (show references to) feature to see where that API is used within the code.
Check where suspicious API's are being used!
Once you've identified suspicious imports.
Make sure you utilise the x-refs (show references to) feature to see where that API is used within the code.




9/ Read the Docs! 📖
When you encounter a windows API, it's useful to read the MSDN docs.
You can then use this information to rename variables and significantly clean up the Ghidra code.
This is a short example to explain the concept.
When you encounter a windows API, it's useful to read the MSDN docs.
You can then use this information to rename variables and significantly clean up the Ghidra code.
This is a short example to explain the concept.



• • •
Missing some Tweet in this thread? You can try to
force a refresh