
Today we're excited to announce that we're partnering with @CarperAI of Stability on bringing the first RLHF-trained GPT-3 like model to the open source community.
This will be huge. Let us explain
This will be huge. Let us explain

RLHF – Reinforcement Learning from Human Preferences.
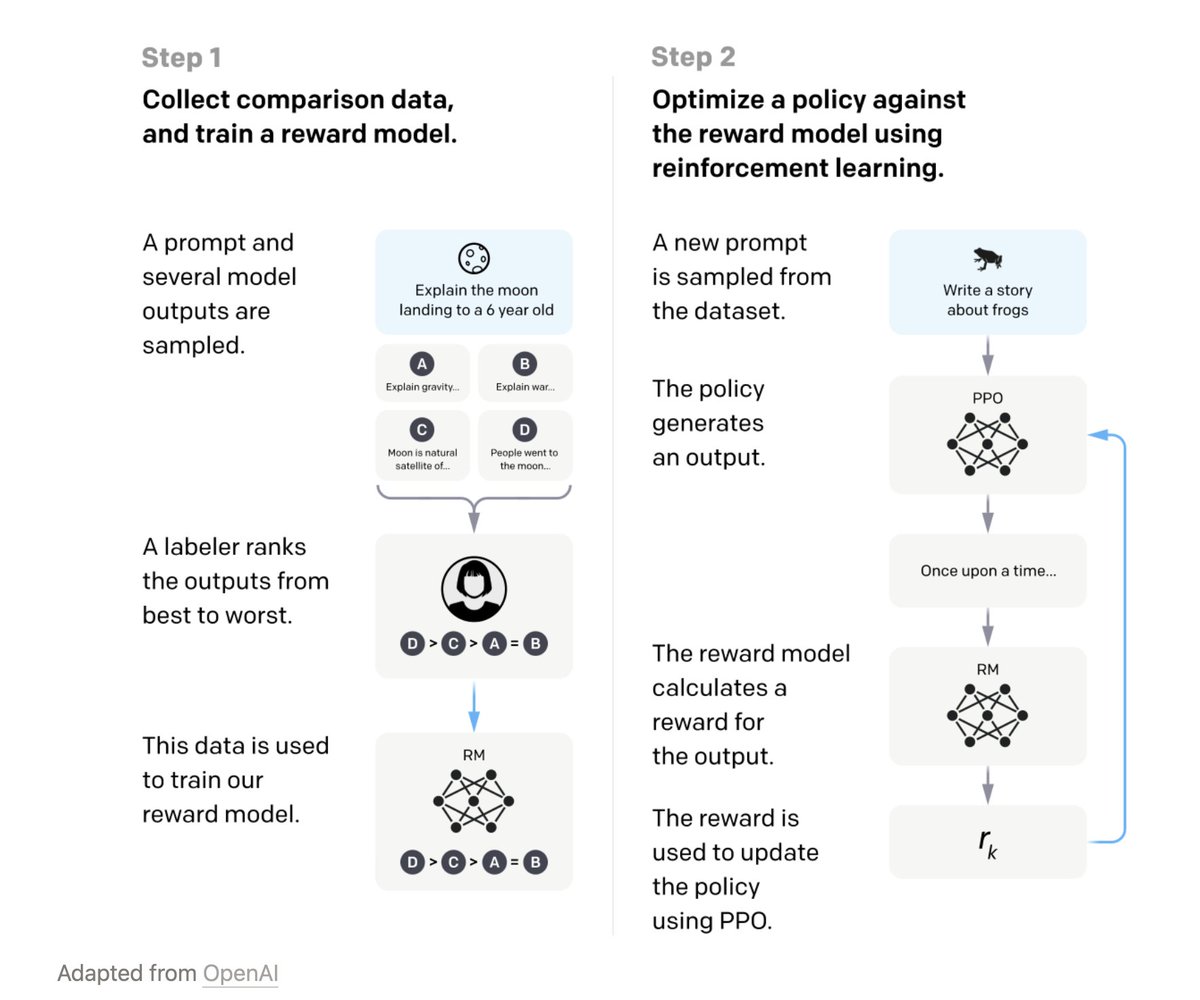
Models are fine tuned using RL from human feedback. They become more helpful, less harmful and they show a huge leap in performance. An RLHF model was preferred over a 100x larger base GPT-3 model.
Models are fine tuned using RL from human feedback. They become more helpful, less harmful and they show a huge leap in performance. An RLHF model was preferred over a 100x larger base GPT-3 model.
These models show far greater ability to take instruction, which has massively increased their usability.
We think RLHF-tuned models will ultimately be applied to every domain and task, and these systems will unlock incredible amounts of value in the real world.
We think RLHF-tuned models will ultimately be applied to every domain and task, and these systems will unlock incredible amounts of value in the real world.
Human feedback is critical to aligning these models to do as you want.
We've built the specialised tools needed for this crucial component and are delighted to be contributing to this open-source effort.
We've built the specialised tools needed for this crucial component and are delighted to be contributing to this open-source effort.
CarperAI will be building in public, and will be releasing the data, code and weights over the coming months. Follow along in their discord.
Like what happened to Stable Diffusion, we can't wait to see the innovation that happens once these models become available for all
Like what happened to Stable Diffusion, we can't wait to see the innovation that happens once these models become available for all
Follow us here for our progress along the way

Join the Carper discord to follow (or get involved!) discord.com/invite/canadag…
Full details of the announcement here humanloop.com/blog/stability…
Full details of the announcement here humanloop.com/blog/stability…
• • •
Missing some Tweet in this thread? You can try to
force a refresh



