Humanloop is the LLM evals platform for enterprises. Trusted by Gusto, Vanta and Duolingo to ship reliable AI products.
 When we started, ChatGPT didn't exist. GPT-3 was cutting-edge and there was no developer tooling.
When we started, ChatGPT didn't exist. GPT-3 was cutting-edge and there was no developer tooling.

 Prompt templates
Prompt templates
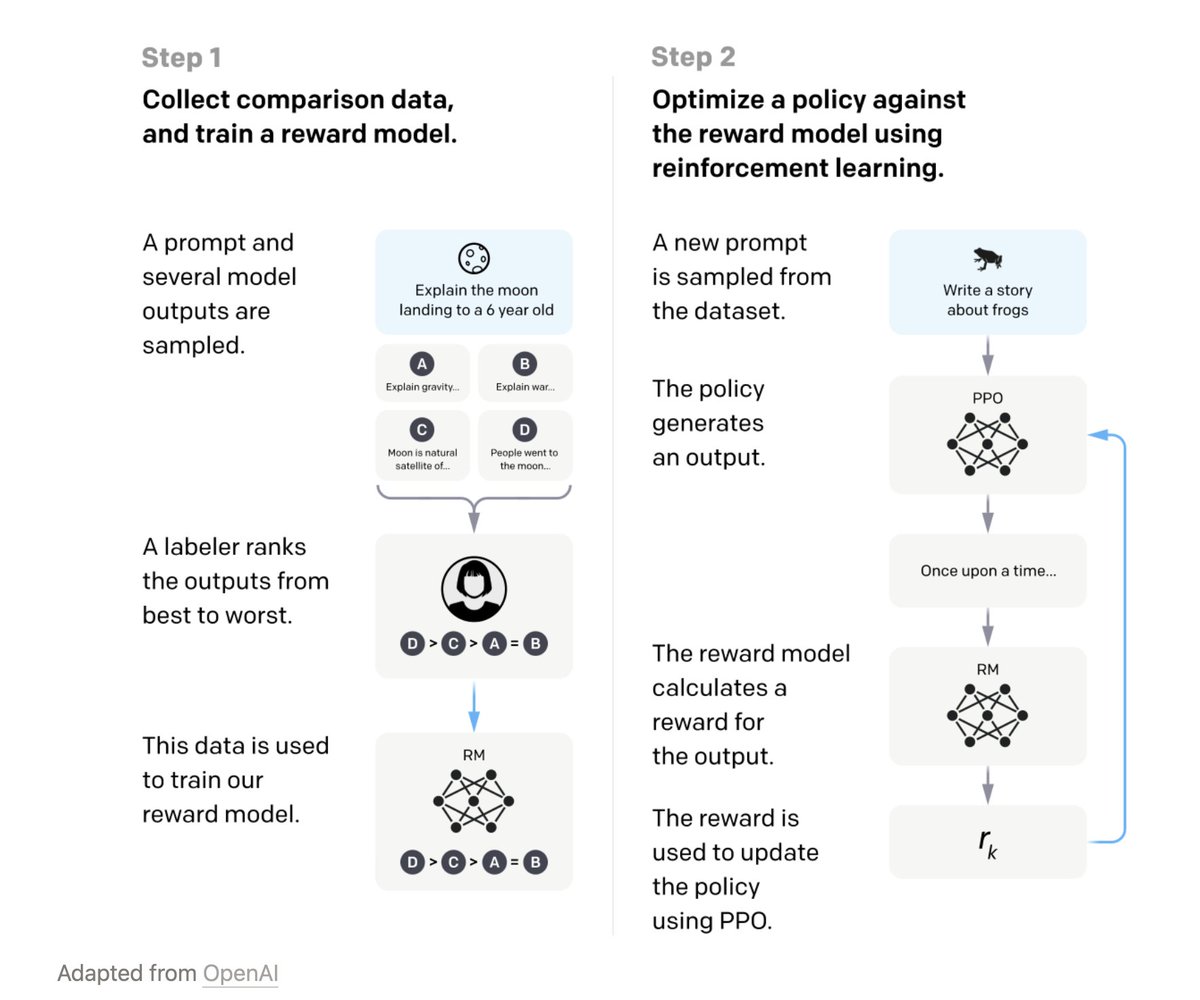
 RLHF – Reinforcement Learning from Human Preferences.
RLHF – Reinforcement Learning from Human Preferences.