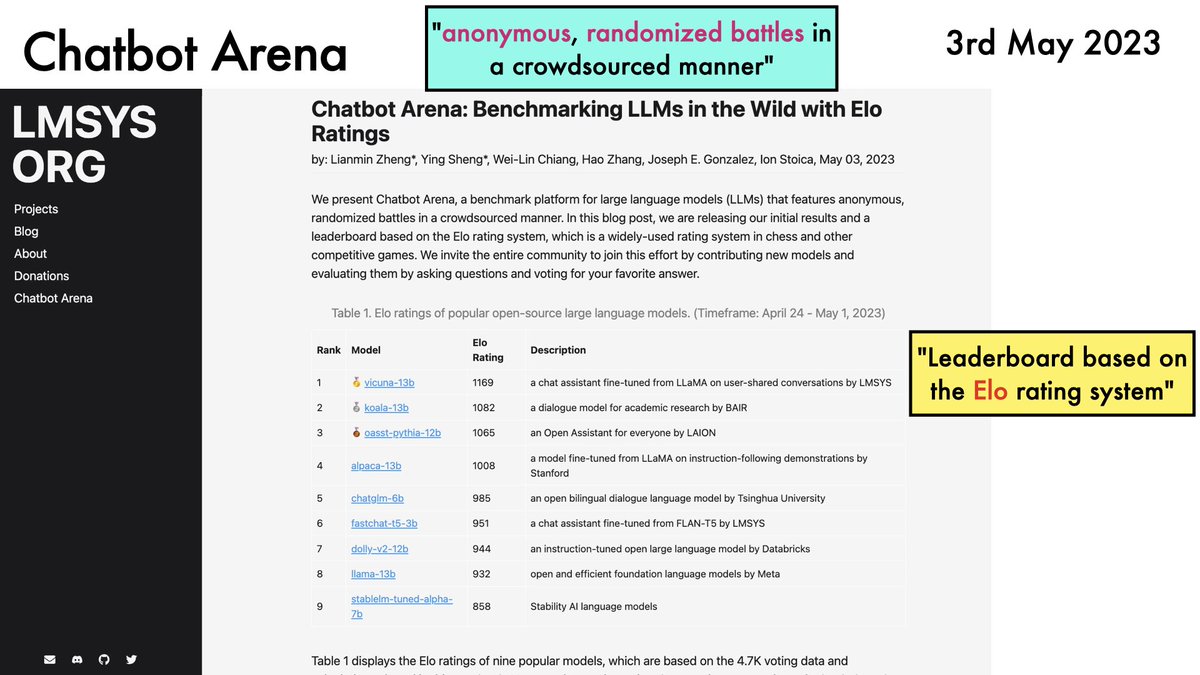
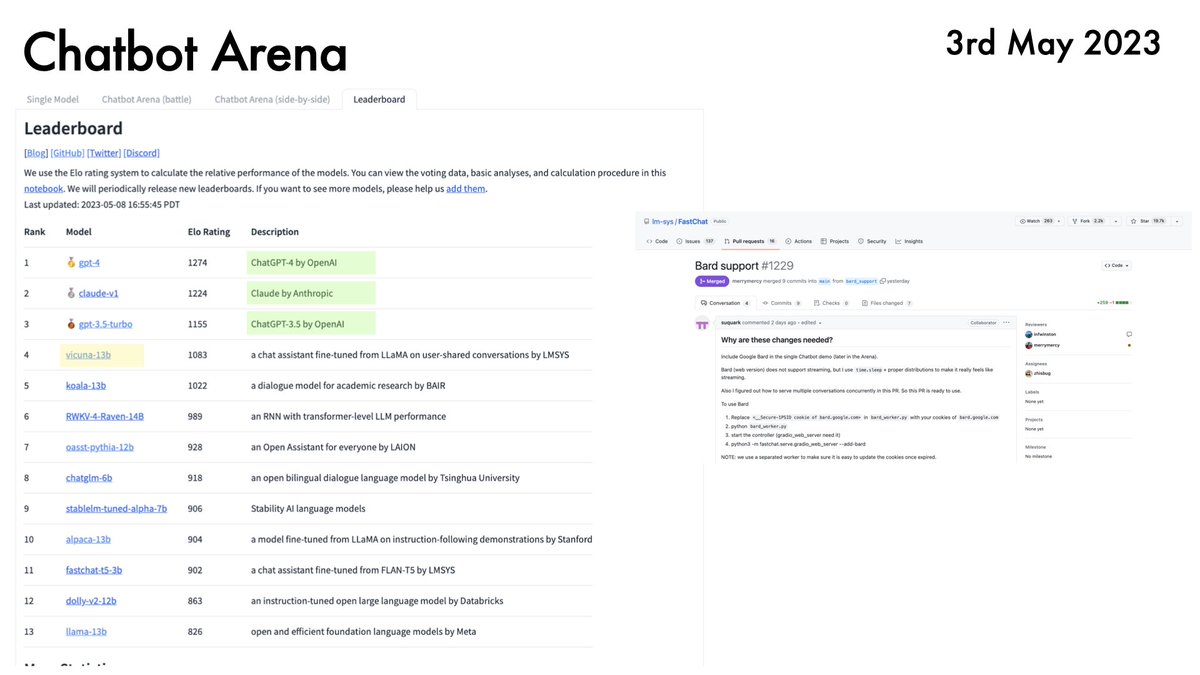
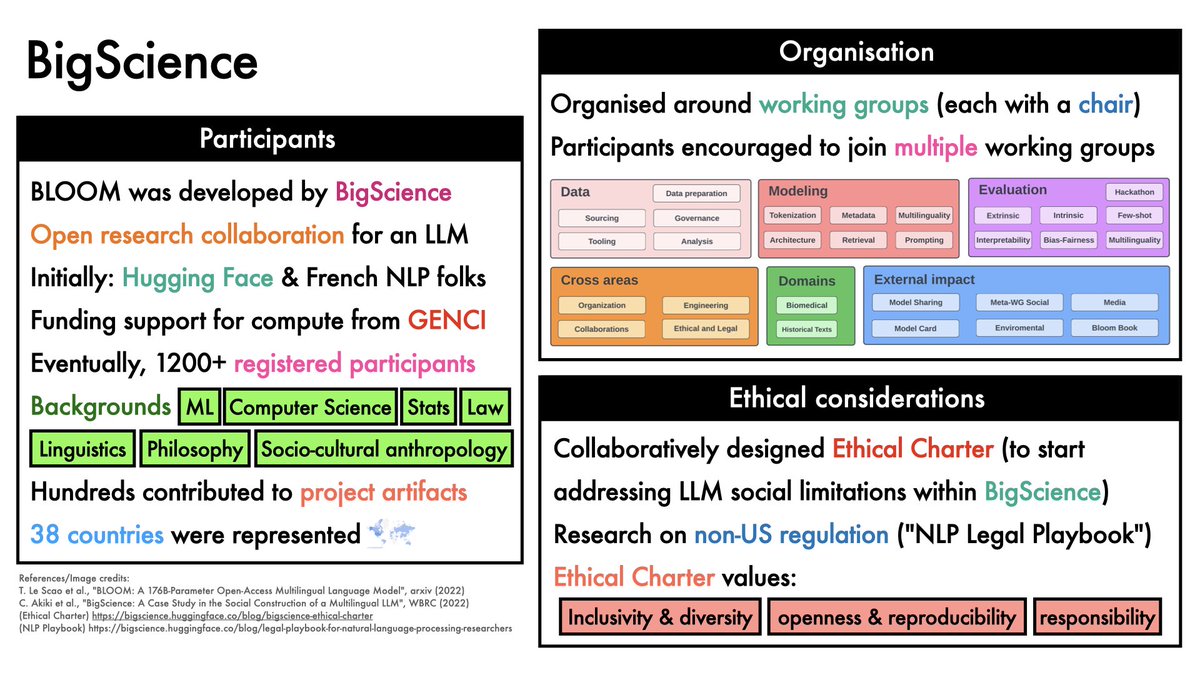
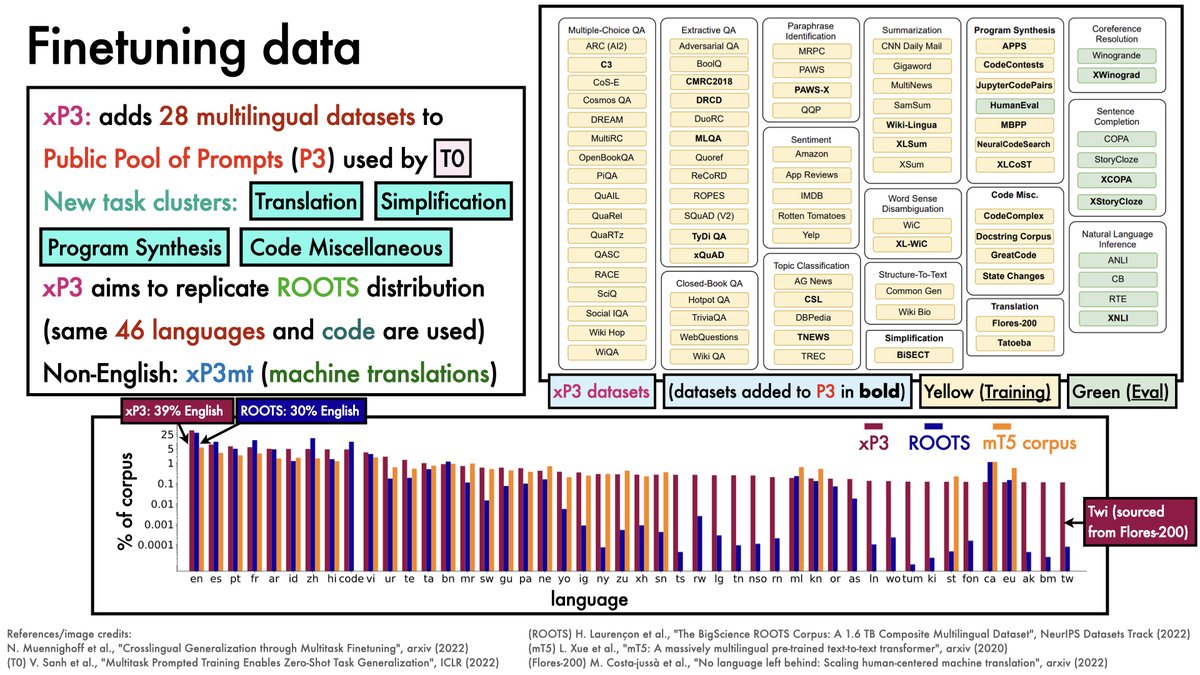
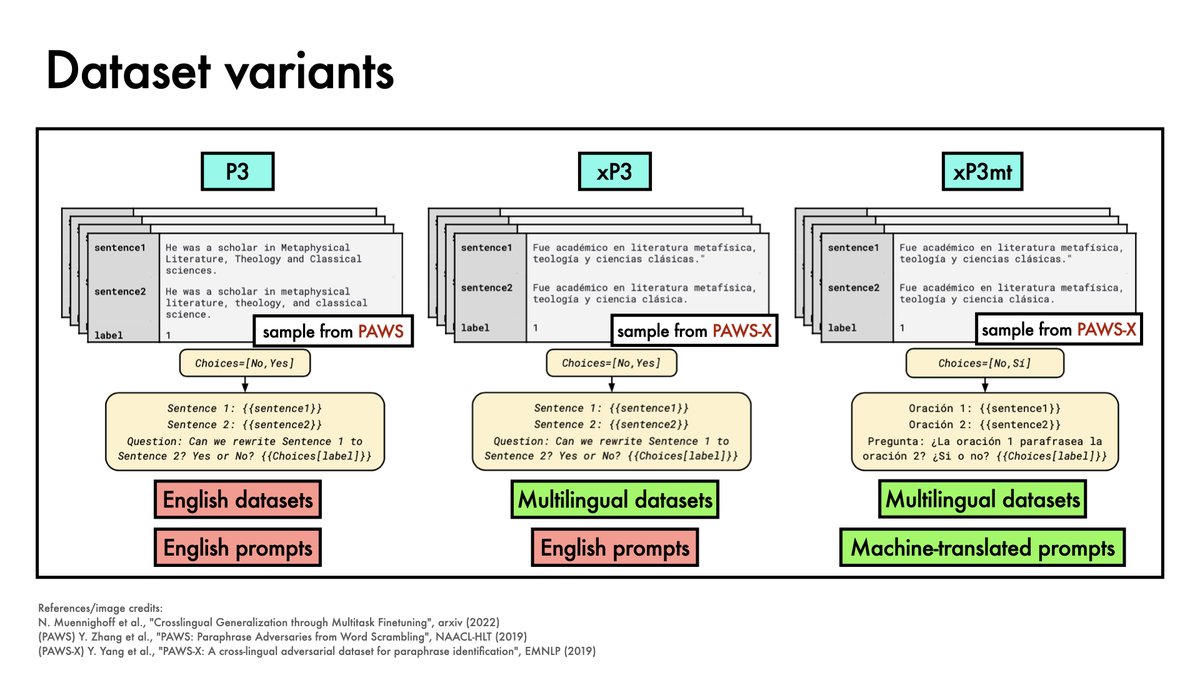
Finetuning language models on instructions increasingly seems a compute-efficient way to gain performance.
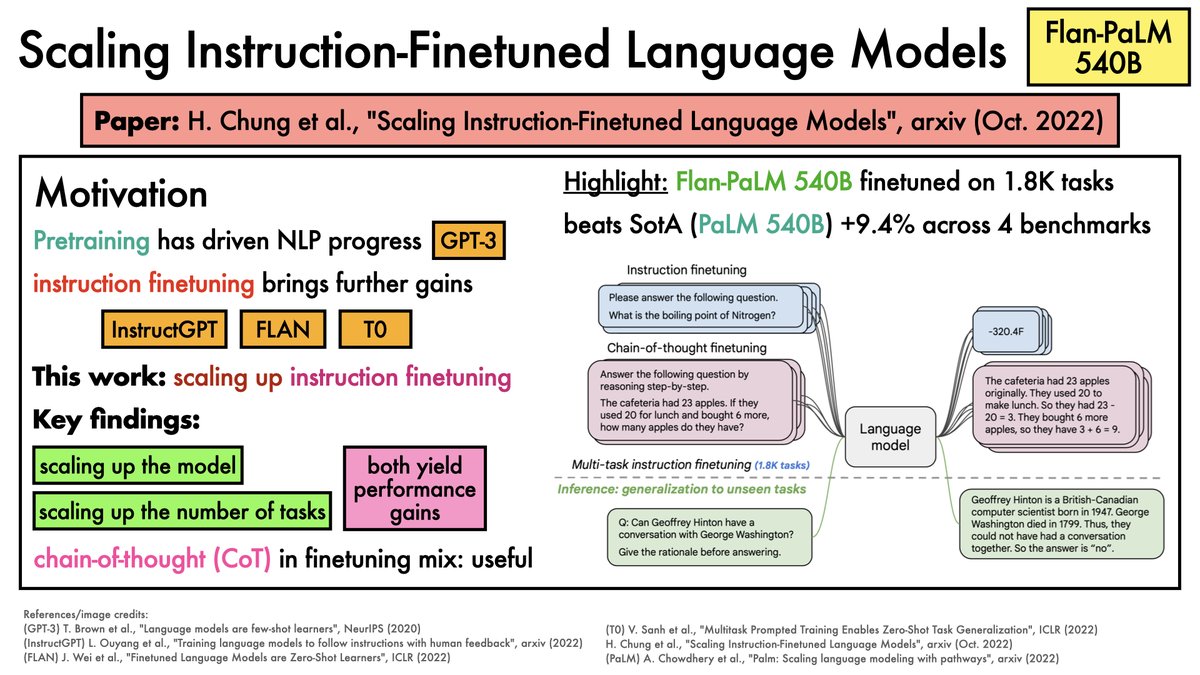
Recent work from @hwchung27, @_jasonwei, @JeffDean, @quocleix & others scales this up to new regimes.
TLDR: Even for big models (540B params), gains are substantial.
1/12
Recent work from @hwchung27, @_jasonwei, @JeffDean, @quocleix & others scales this up to new regimes.
TLDR: Even for big models (540B params), gains are substantial.
1/12
For those who prefer a narrated version:
2/12
2/12
Flan-PaLM 540B (PaLM 540B finetuned on instructions) makes major progress on MMLU.
Note: my previous graph (
Even with the update, the numbers remain impressive.
3/12
Note: my previous graph (
https://twitter.com/SamuelAlbanie/status/1584257440891416576) lacked some of the available SotA forecasts - that's updated below.
Even with the update, the numbers remain impressive.
3/12
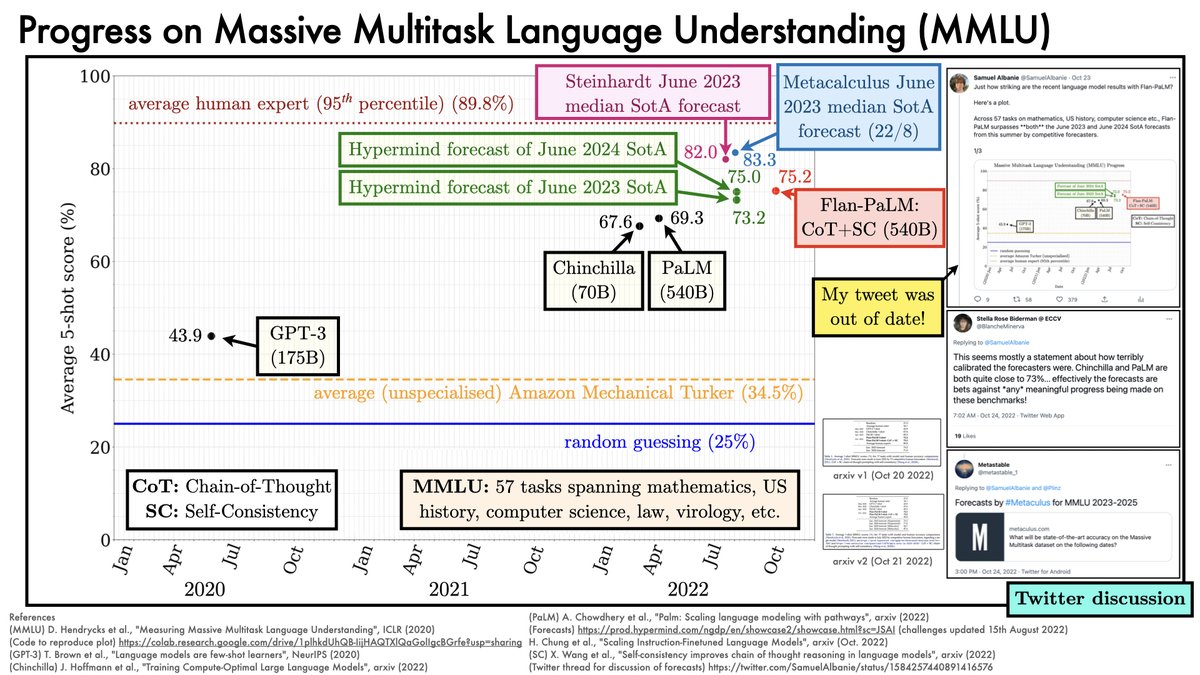
The forecasts themselves are interesting.
Credit to @JacobSteinhardt for leading these.
I recommend his analysis 1 year into the forecast bounded-regret.ghost.io/ai-forecasting…
TLDR: forecasters didn't do well. But to some degree, this is because progress was "surprising".
4/12
Credit to @JacobSteinhardt for leading these.
I recommend his analysis 1 year into the forecast bounded-regret.ghost.io/ai-forecasting…
TLDR: forecasters didn't do well. But to some degree, this is because progress was "surprising".
4/12

Hypermind SotA forecasters revised their estimates upwards earlier this summer. But not massively.
@jacoabsteinhardt flagged in July '22 that Hypermind forecasts seemed low.
Metacalculus forecasts & Steinhardt's are higher.
ML researchers: contribute to future forecasts!
5/12
@jacoabsteinhardt flagged in July '22 that Hypermind forecasts seemed low.
Metacalculus forecasts & Steinhardt's are higher.
ML researchers: contribute to future forecasts!
5/12

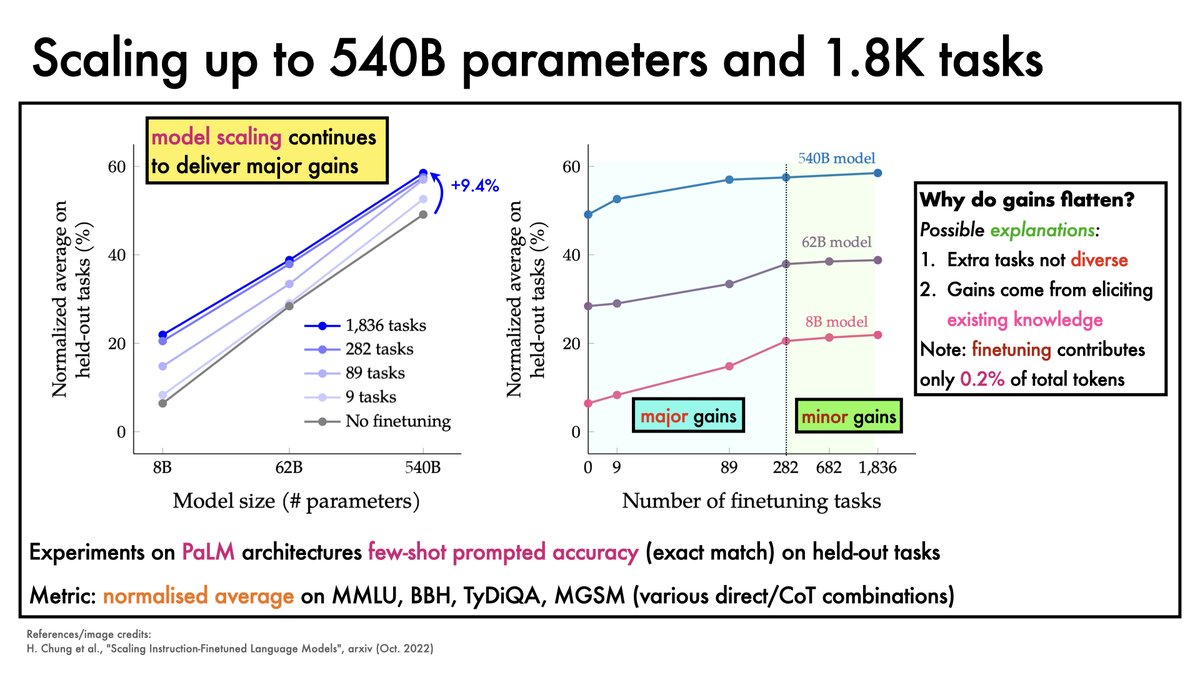
@Hwchung et al. explore a regime that uses a lot of instructions ~1800 tasks in total.
Models from small (80 million params) to v. big (540 billion params) are studied.
Interestingly, finetuning is relatively cheap (at most 1.6% of compute relative to pretraining).
6/12
Models from small (80 million params) to v. big (540 billion params) are studied.
Interestingly, finetuning is relatively cheap (at most 1.6% of compute relative to pretraining).
6/12
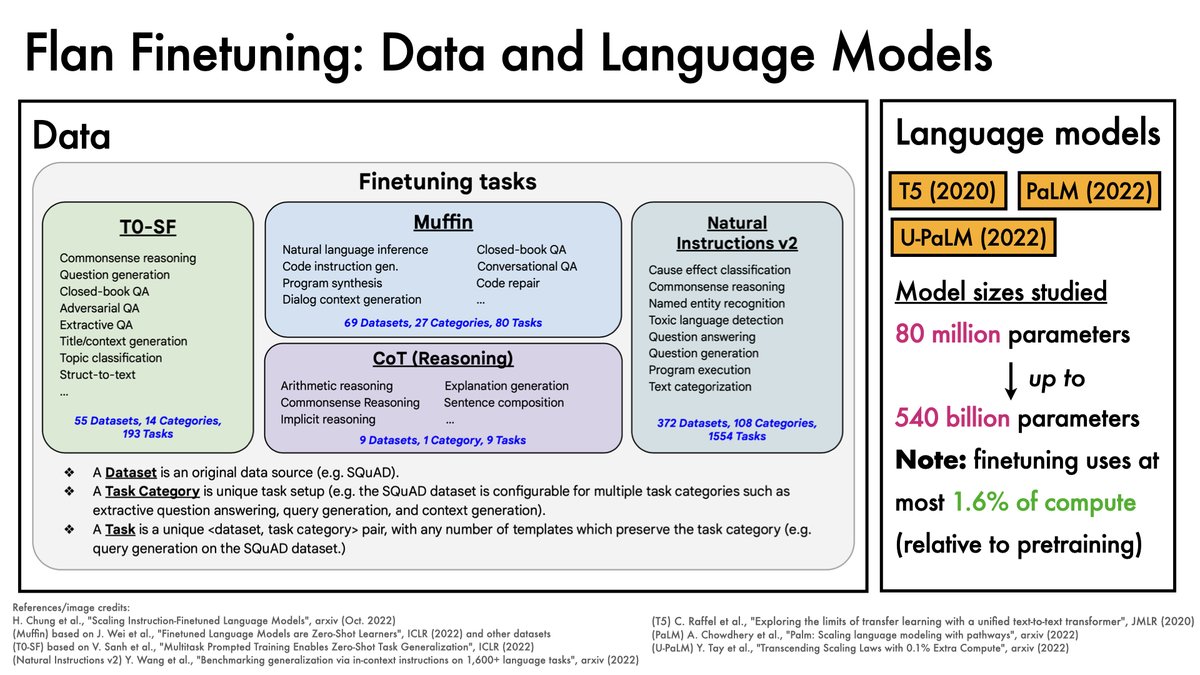
Increasing model size continues to yield major gains.
Increasing the number of tasks helps, but brings diminishing returns.
7/12
Increasing the number of tasks helps, but brings diminishing returns.
7/12
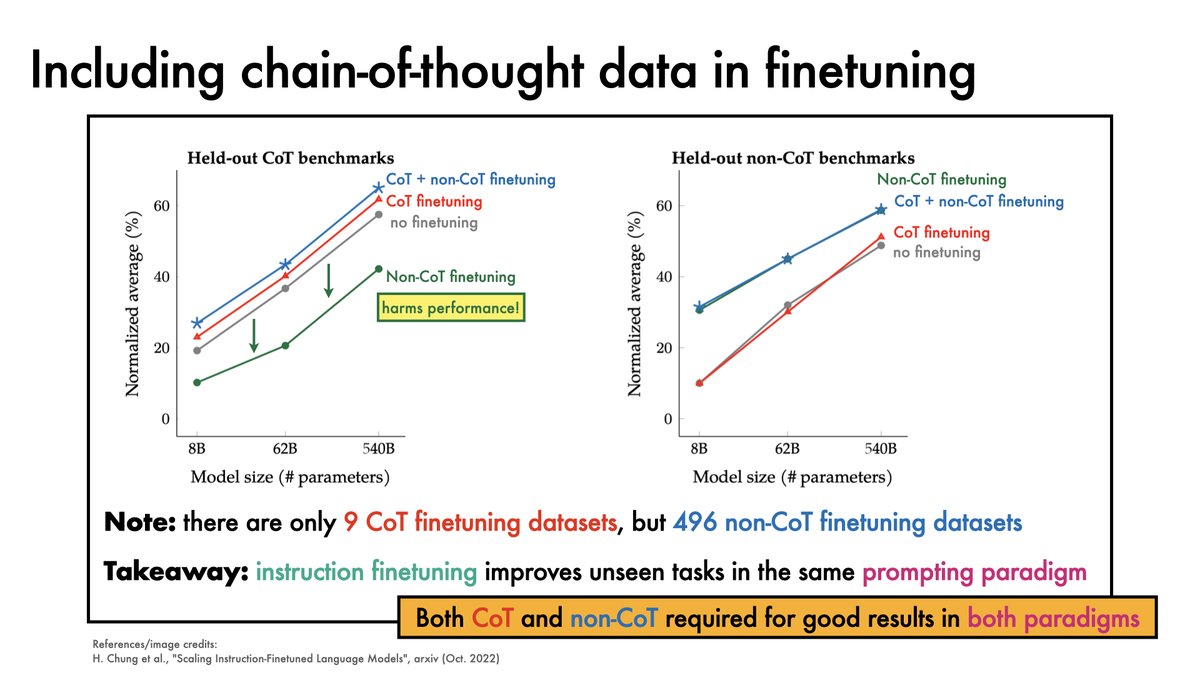
To perform well in both chain-of-thought and non-chain-of-thought prompting paradigms, both kinds of data should be included in the finetuning mixture.
8/12
8/12
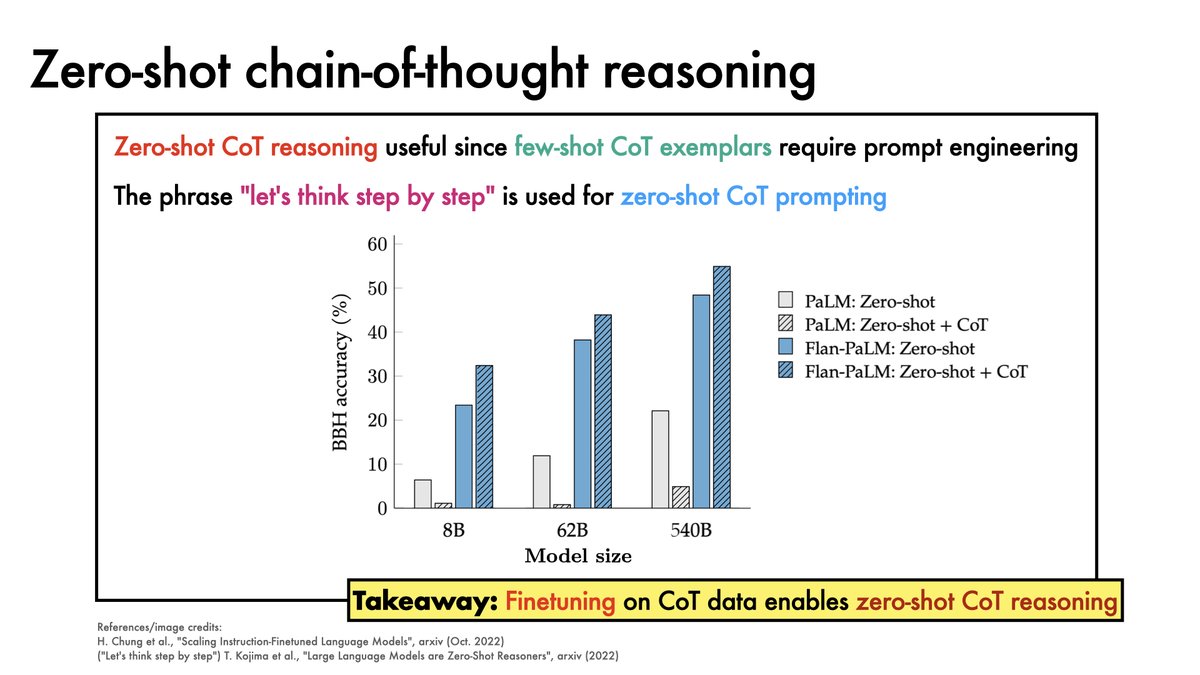
Flan finetuning (which includes chain-of-thought data) enables Flan-PaLM to benefit from chain-of-thought prompting in a zero-shot setting.
9/12
9/12
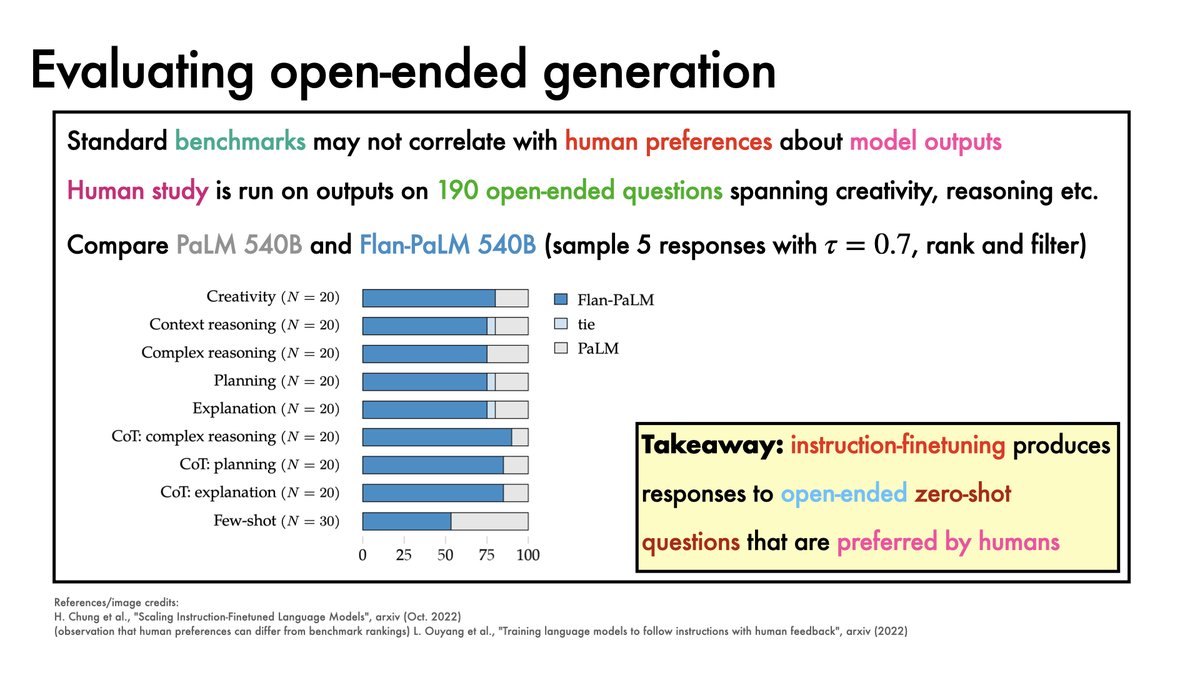
It's useful to note that human preferences about open-ended model outputs may not correlate with NLP benchmark scores.
Still, human annotators prefer Flan-PaLM 540B to PaLM 540B by a healthy margin.
10/12
Still, human annotators prefer Flan-PaLM 540B to PaLM 540B by a healthy margin.
10/12
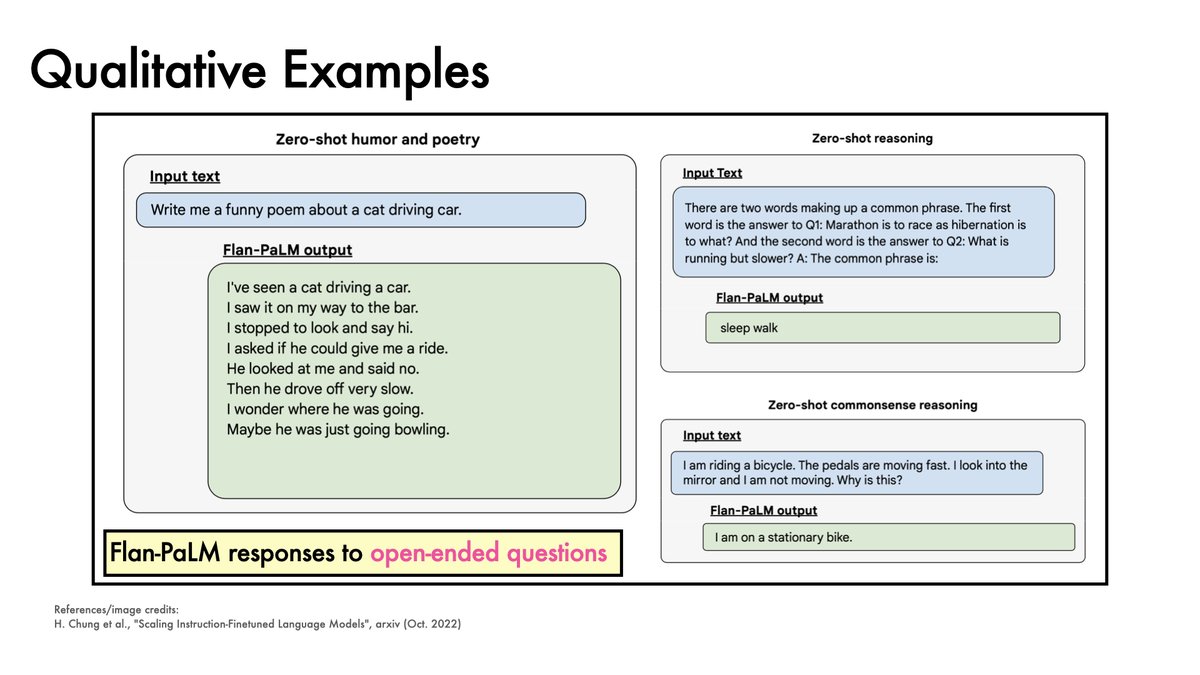
If cats driving cars are your thing, Flan-PaLM can write funny poems.
11/12
11/12
Overall takeaway: instruction finetuning seems likely to be broadly applicable for pretrained language models.
Paper: arxiv.org/abs/2210.11416
12/12
Paper: arxiv.org/abs/2210.11416
12/12

• • •
Missing some Tweet in this thread? You can try to
force a refresh