
 Language models can explain neurons in language models
Language models can explain neurons in language models
 2/ 🏃💨 Tired of racing to publish your next high-impact research?
2/ 🏃💨 Tired of racing to publish your next high-impact research? Large Languages Models (LLMs) now play a key role in NLP.
Large Languages Models (LLMs) now play a key role in NLP. 
 For this study, datasets spanning 46 languages were gathered (collectively referred to as "xP3").
For this study, datasets spanning 46 languages were gathered (collectively referred to as "xP3").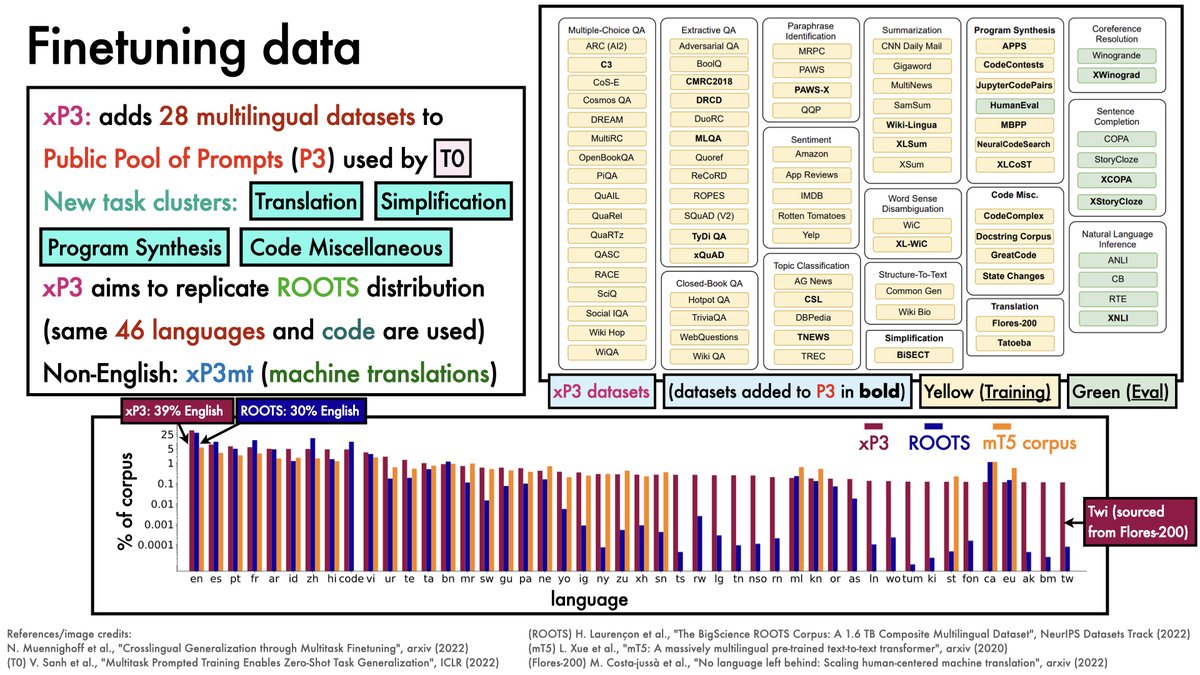
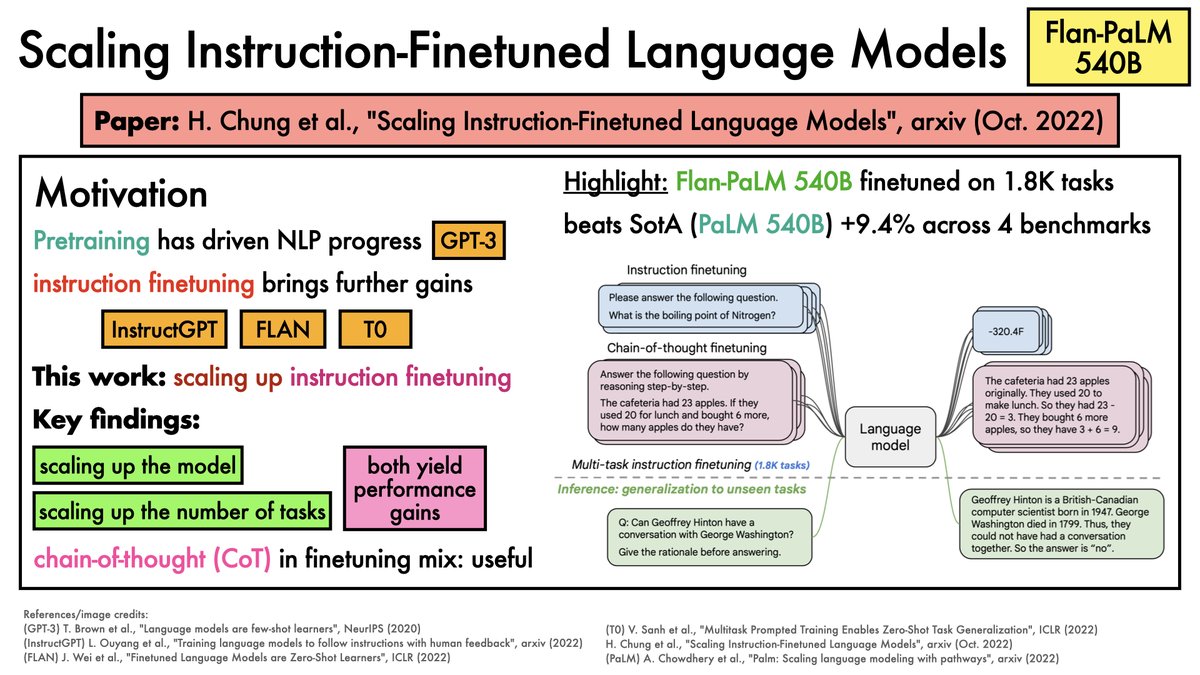 For those who prefer a narrated version:
For those who prefer a narrated version: Key idea: compress a large dataset into a small set of synthetic images that can train networks to the same accuracy as the original dataset.
Key idea: compress a large dataset into a small set of synthetic images that can train networks to the same accuracy as the original dataset.