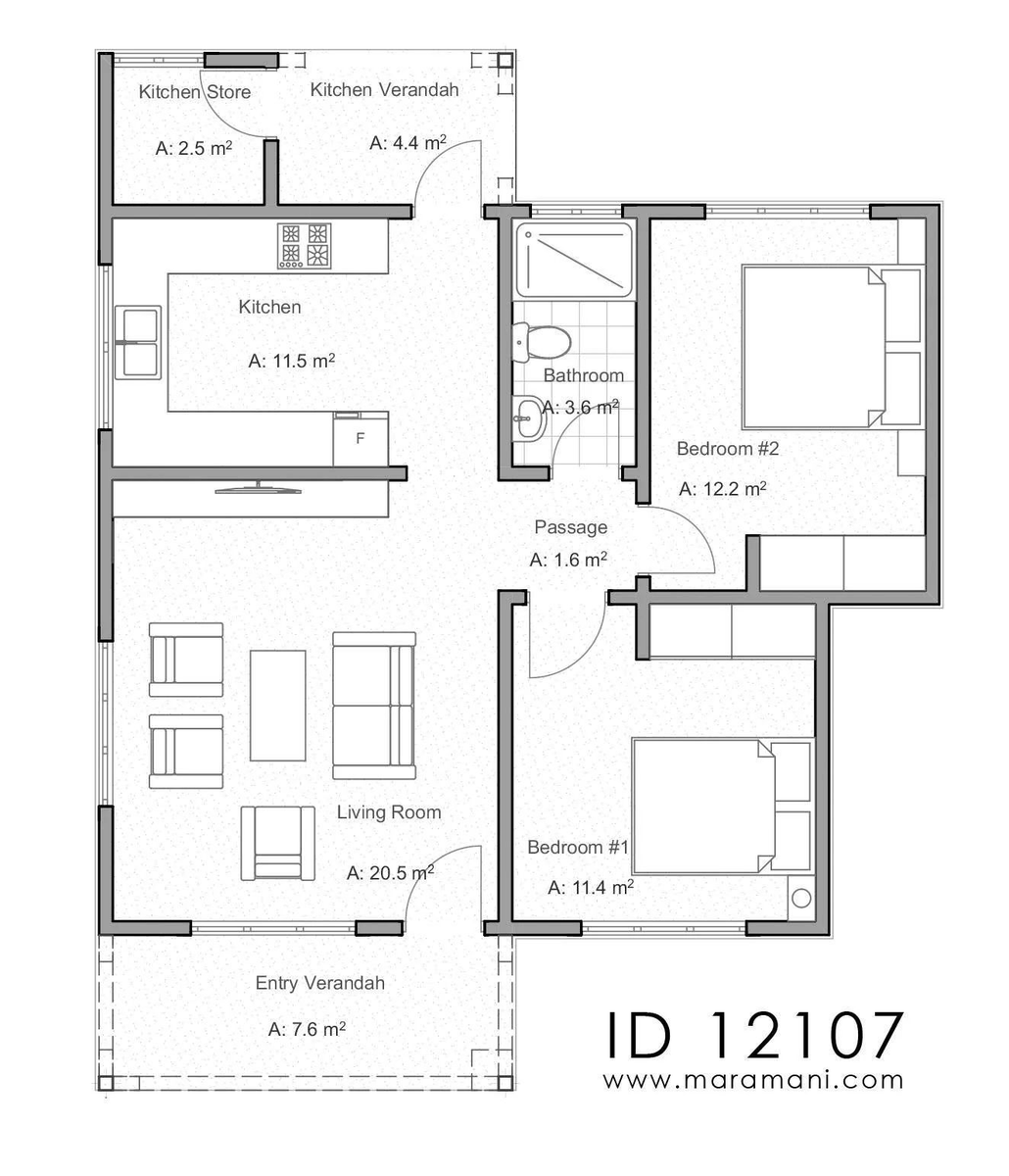
#Dreambooth will change how 2D game assets are being designed or generated.
Today's exploration: treasure chests 💎💰.
I trained Stable Diffusion with some low-poly treasure chests (23 images). 1h later, here's what's possible (🧵):
Today's exploration: treasure chests 💎💰.
I trained Stable Diffusion with some low-poly treasure chests (23 images). 1h later, here's what's possible (🧵):




At first, I randomly generated a set of 64 items, without any specific prompt engineering ("a treasure chest").

Here's a close-up view:

It's possible to add some backgrounds as well (forest, ocean)...


... or to generate a set of icons (with the squircle frame)

Let's be more specific and design "an old Asian treasure chest". Like the one pictured below.
Pretty easy... by using #img2img, I'm getting similar low-poly chests that look like the original photograph.
Pretty easy... by using #img2img, I'm getting similar low-poly chests that look like the original photograph.



The same concept, this time with a "wooden pirate chest“. The model keeps the shape of the original image.


There's literally no limit.
In the example below, I added: "wooden", "steel", "golden" and even "Halloween" & "Christmas".
In the example below, I added: "wooden", "steel", "golden" and even "Halloween" & "Christmas".




Some more explorations (spaceship chest, superhero chest, chest with legs...)




Please reach out if you're a concept artist and would like to try this with your own art/style/content (from props to characters, weapons, environments, etc).
🤝
#StableDiffusion #AIgenerated #Dreambooth #Gaming
🤝
#StableDiffusion #AIgenerated #Dreambooth #Gaming
More Dreambooth explorations here:
https://twitter.com/emmanuel_2m/status/1587991324816379904
• • •
Missing some Tweet in this thread? You can try to
force a refresh