
Multilingual pre-training is really useful for improving the performance of deep networks on low resource languages (i.e., those that lack sufficient training data). But, whether multilingual pre-training is damaging for high resource languages is currently unclear. 🧵[1/5]
For BERT-style models like XLM-R (bit.ly/3Ww8qjY by @alex_conneau), models pre-trained over multilingual corpora (given proper tuning) can match the performance of monolingual models for high resources languages like English/French on GLUE. [2/5] 
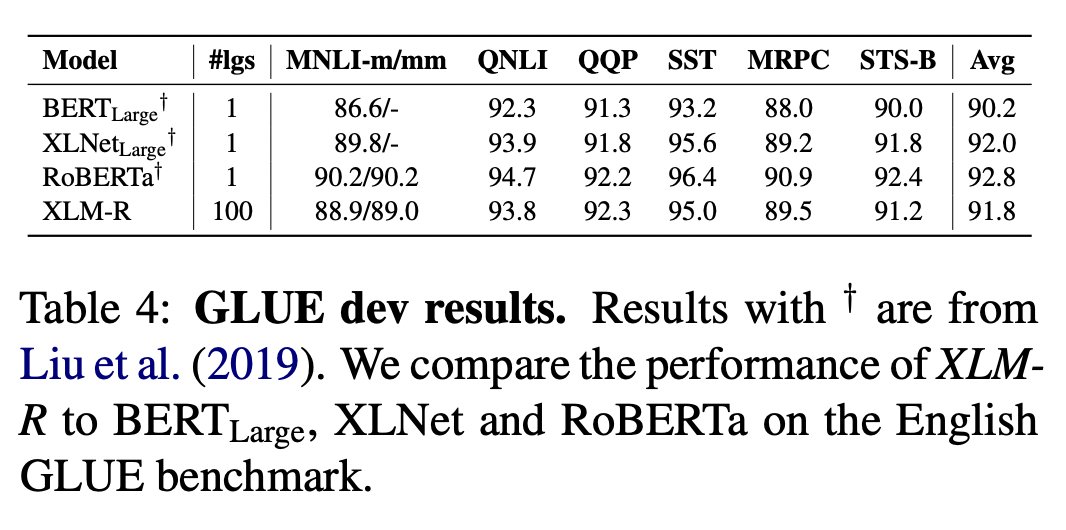
Recent research in large language models (bit.ly/3zI5JSQ by @Fluke_Ellington), however, indicates that multilingual pre-training significantly damages zero-shot generalization performance of LLMs in English. [3/5]

The basic takeaway from these results is that the curse of multilinguality (bit.ly/3NvW5bI) is real! Multilingual pre-training is sometimes damaging, but this damage can be mitigated by using larger models or tuning the sampling ratio between languages. [4/5]

Thanks to @davisblalock for pointing out this issue in his awesome newsletter (dblalock.substack.com). If you find these threads useful, feel free to subscribe to my newsletter as well (cameronrwolfe.substack.com)! [5/5]
#DeepLearning #NLP
#DeepLearning #NLP
• • •
Missing some Tweet in this thread? You can try to
force a refresh



