
Research @Netflix • Writer @ Deep (Learning) Focus • PhD @optimalab1
 Also some examples of pairwise, pointwise, and reference prompts for LLM-as-a-Judge (as proposed in the original paper, where I found these figures) are shown in the image below for quick reference!
Also some examples of pairwise, pointwise, and reference prompts for LLM-as-a-Judge (as proposed in the original paper, where I found these figures) are shown in the image below for quick reference! 
 (1) Early research references:
(1) Early research references: To gain a better understanding of the basic concepts behind MoEs, check out my overview of the topic below. The MoE layer is a key advancement in LLM research that powers popular LLMs like Grok-1 and (per rumors in the community) GPT-4.
To gain a better understanding of the basic concepts behind MoEs, check out my overview of the topic below. The MoE layer is a key advancement in LLM research that powers popular LLMs like Grok-1 and (per rumors in the community) GPT-4. An implementation of masked self-attention in PyTorch (derived from NanoGPT by Andrej Karpathy) is provided below. As we can see, the implementation of masked self-attention is easy to follow if we understand the concepts behind the computation!
An implementation of masked self-attention in PyTorch (derived from NanoGPT by Andrej Karpathy) is provided below. As we can see, the implementation of masked self-attention is easy to follow if we understand the concepts behind the computation!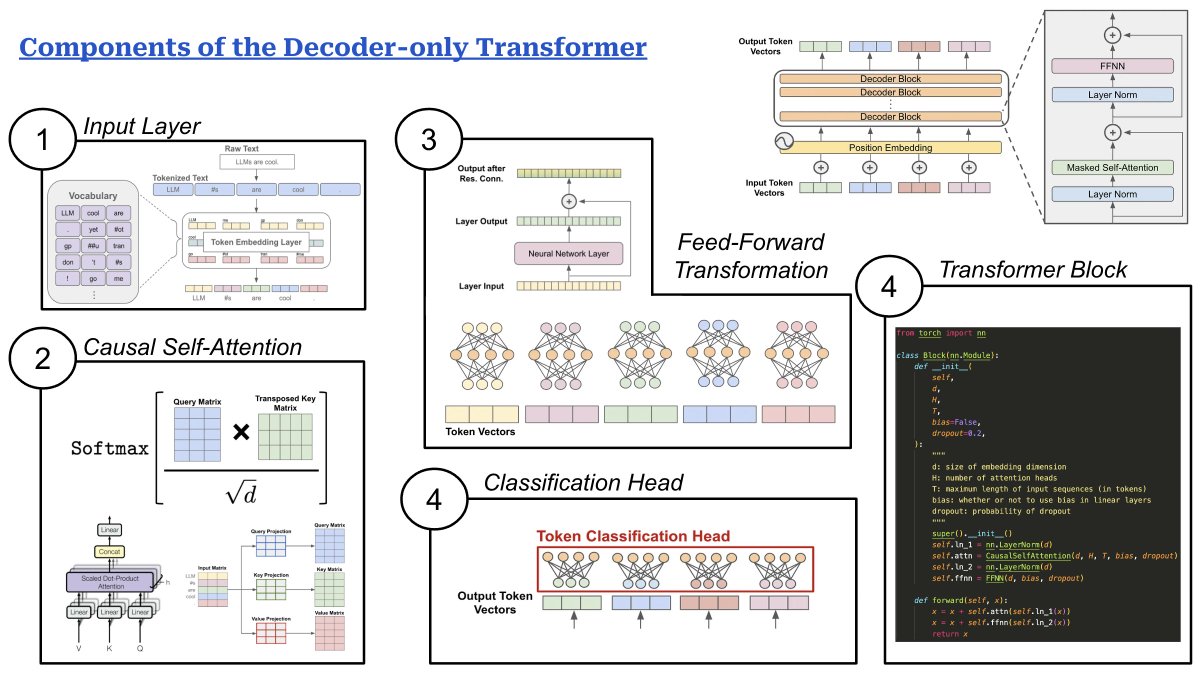 I also wrote an explainer of the decoder-only transformer a long time ago, right around when I first began writing publicly-available content about deep learning. Check it out below.
I also wrote an explainer of the decoder-only transformer a long time ago, right around when I first began writing publicly-available content about deep learning. Check it out below.  More interesting info on the superficial alignment hypothesis is provided below. This paper deeply studies the impact of alignment on LLMs, as well as proposes a "tuning-free" approach to alignment (maybe alignment literally requires no finetuning).
More interesting info on the superficial alignment hypothesis is provided below. This paper deeply studies the impact of alignment on LLMs, as well as proposes a "tuning-free" approach to alignment (maybe alignment literally requires no finetuning). For more details on OLMo and Dolma, check out my prior post below. This model (and the information, tools, and data that come with it) is incredibly important for anyone looking to better understand the LLM pretraining process.
For more details on OLMo and Dolma, check out my prior post below. This model (and the information, tools, and data that come with it) is incredibly important for anyone looking to better understand the LLM pretraining process. See below for links to the Dolma and OLMo papers. They're arguably the two most useful papers ever published if you're looking for information on how to pretrain your own LLM.
See below for links to the Dolma and OLMo papers. They're arguably the two most useful papers ever published if you're looking for information on how to pretrain your own LLM. 
 RAG was originally proposed in this paper:
RAG was originally proposed in this paper:  Some of the notable papers mentioned in the post above include:
Some of the notable papers mentioned in the post above include: Here's a link to the actual paper for those interested in reading more deeply about this topic.
Here's a link to the actual paper for those interested in reading more deeply about this topic. Also, one of the main reasons that I love this paper is that it was written by authors from my alma mater (Rice University), as well as Texas A&M. This is a great example of how academic research can provide practical and useful techniques in the era of LLMs.
Also, one of the main reasons that I love this paper is that it was written by authors from my alma mater (Rice University), as well as Texas A&M. This is a great example of how academic research can provide practical and useful techniques in the era of LLMs. 
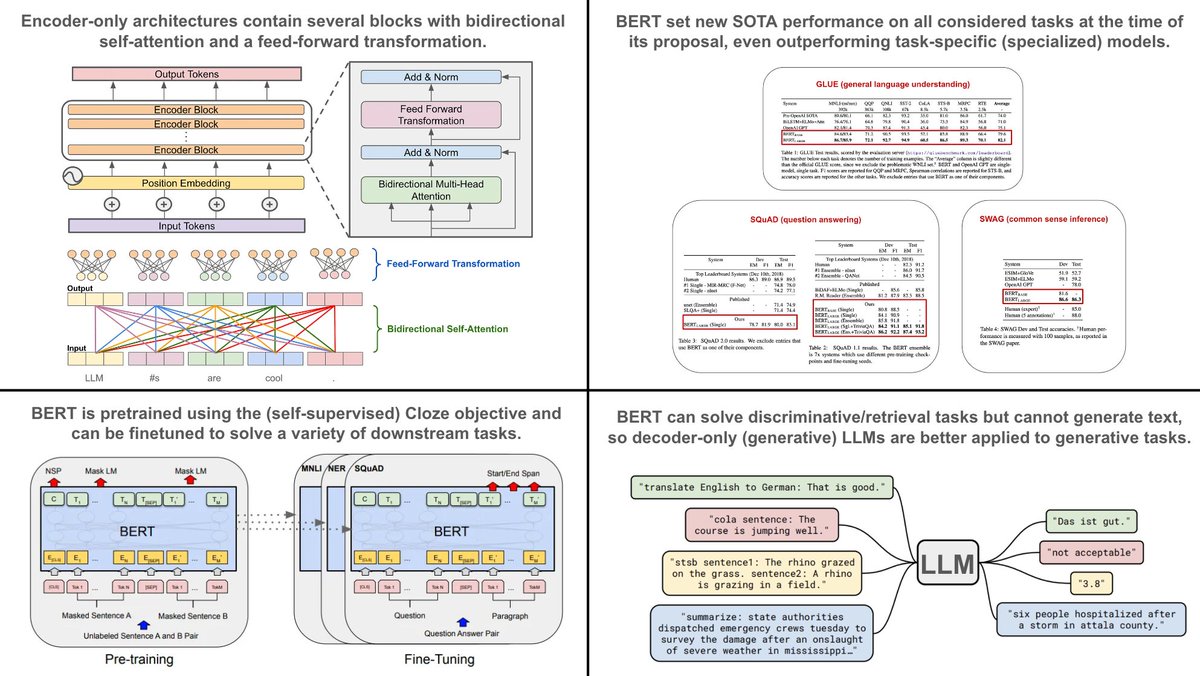 To learn more about the self-attention mechanism that is used by encoder-only transformer architectures, check out the post below. Bidirectional self-attention is the primary building block of encoder-only transformers!
To learn more about the self-attention mechanism that is used by encoder-only transformer architectures, check out the post below. Bidirectional self-attention is the primary building block of encoder-only transformers! For more details on language model pretraining with next token prediction, how it works, and how it is implemented, check out the post below.
For more details on language model pretraining with next token prediction, how it works, and how it is implemented, check out the post below. Also, the thoughts behind why I like language models so much were partially inspired by my newsletter recently passing 10K subscribers. Thanks to everyone who reads it and gives me a reason to continue working on and thinking about these models!
Also, the thoughts behind why I like language models so much were partially inspired by my newsletter recently passing 10K subscribers. Thanks to everyone who reads it and gives me a reason to continue working on and thinking about these models! 
 For more info on RLHF in general, check out my prior post on this topic, which outlines the history of RLHF and the role that it played in the recent generative AI boom.
For more info on RLHF in general, check out my prior post on this topic, which outlines the history of RLHF and the role that it played in the recent generative AI boom. Here are two papers that initially explored RLHF w/ LLMs:
Here are two papers that initially explored RLHF w/ LLMs:
 Here are links to the relevant papers:
Here are links to the relevant papers: For more information on flash attention, check out the paper!
For more information on flash attention, check out the paper! "The False Promise of Imitating Proprietary LLMs” is full of incredibly useful information and is a must-read for researchers in the LLM space. Primarily, this paper made me rethink how to properly evaluate LLMs and the systems built around them.
"The False Promise of Imitating Proprietary LLMs” is full of incredibly useful information and is a must-read for researchers in the LLM space. Primarily, this paper made me rethink how to properly evaluate LLMs and the systems built around them.