🪐 Introducing Galactica. A large language model for science.
Can summarize academic literature, solve math problems, generate Wiki articles, write scientific code, annotate molecules and proteins, and more.
Explore and get weights: galactica.org
Can summarize academic literature, solve math problems, generate Wiki articles, write scientific code, annotate molecules and proteins, and more.
Explore and get weights: galactica.org
We believe models should be open.
To accelerate science, we open source all models including the 120 billion model with no friction. You can access them here.
github.com/paperswithcode…
To accelerate science, we open source all models including the 120 billion model with no friction. You can access them here.
github.com/paperswithcode…
We release our initial paper below. We train on a large scientific corpus of papers, reference material, knowledge bases and many other sources. Includes scientific text and also scientific modalities such as proteins, compounds and more.
galactica.org/paper.pdf
galactica.org/paper.pdf


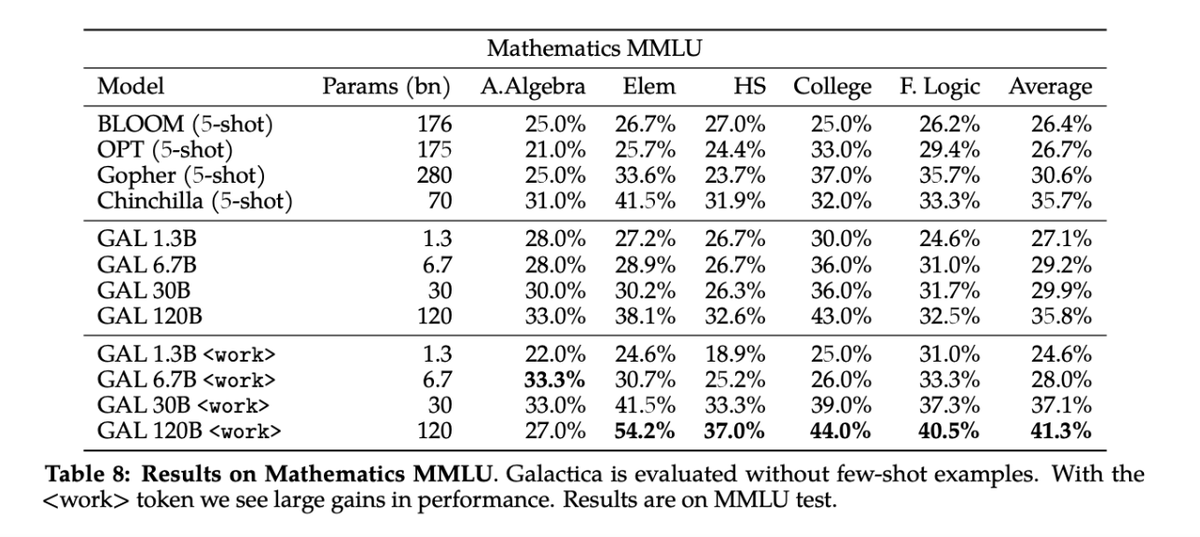
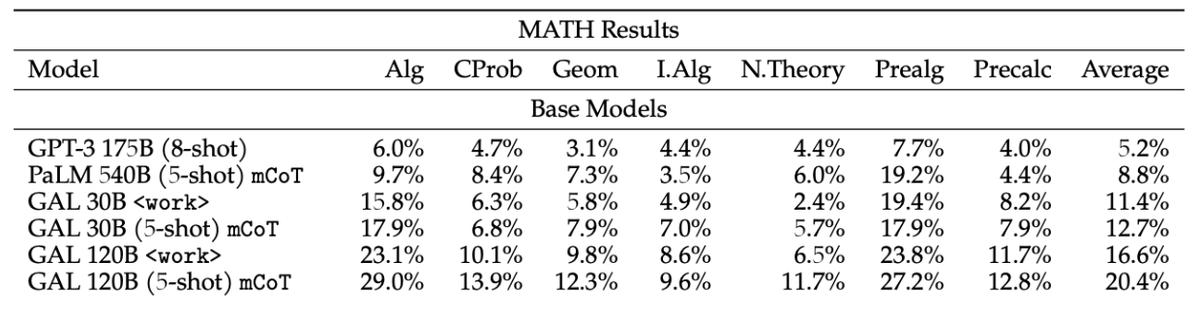
Galactica performs well on reasoning, outperforming Chinchilla on mathematical MMLU by 41.3% to 35.7%, and PaLM 540B on MATH with a score of 20.4% versus 8.8%.
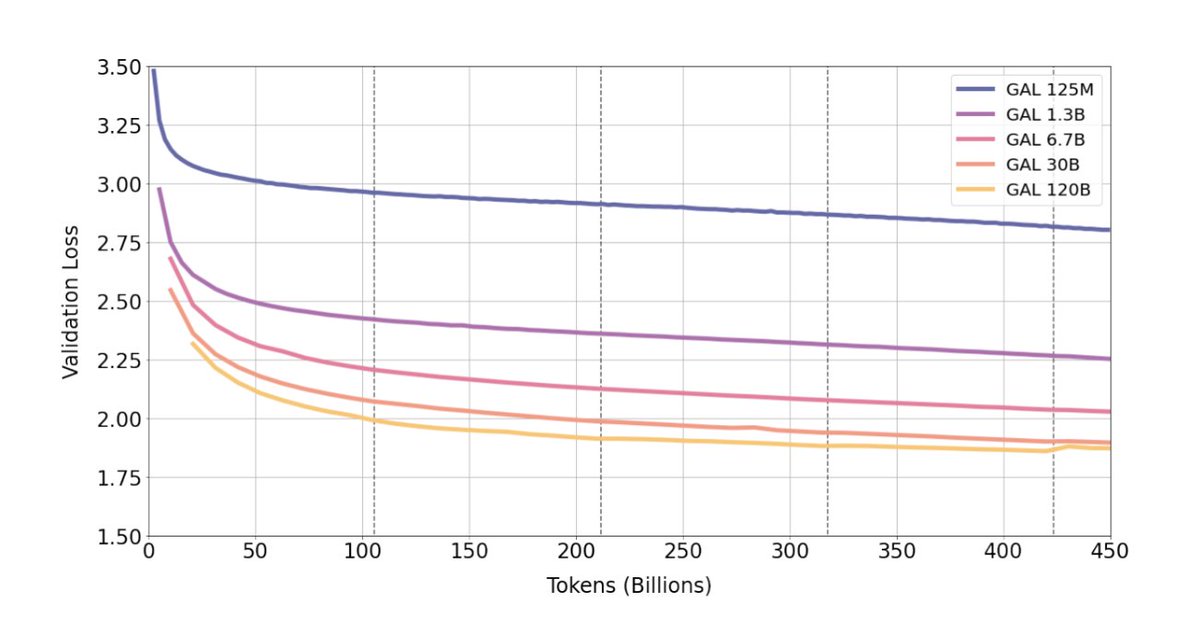
We train for over four epochs and experience improving performance with use of repeated tokens. For the largest 120B model, we trained for four epochs without overfitting.
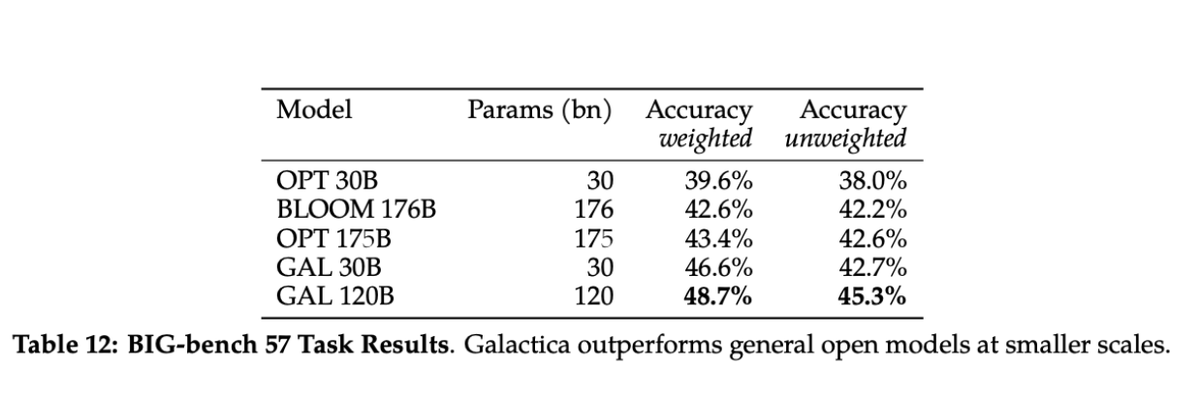
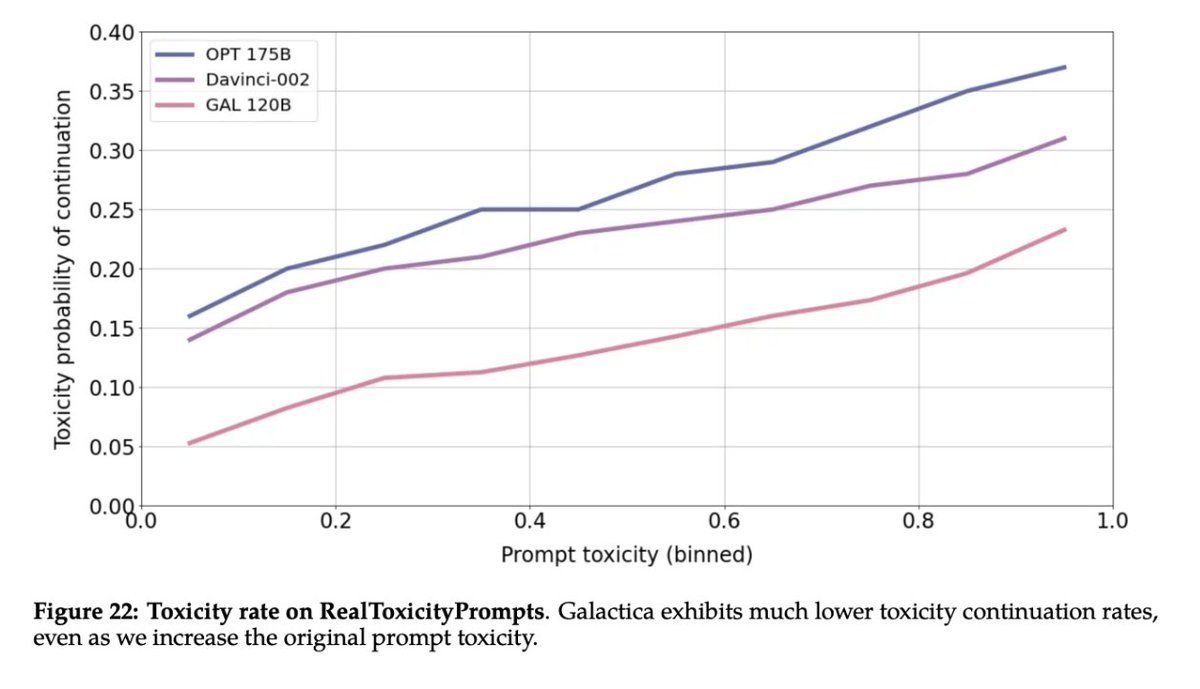
Despite not being trained on a general corpus, Galactica outperforms BLOOM and OPT-175B on BIG-bench. Galactica is also significantly less toxic than other language models based on evaluations.
This is just the first step on our mission to organize science. And there is a lot more work to be done. We look forward to seeing what the open ML community builds with the model.
• • •
Missing some Tweet in this thread? You can try to
force a refresh