I always thought #StableDiffusion prompts needed the right combination of words. But byte-pair encoding can represent anything you can type, including math formulas and emojis. Turns out you don't need any words at all! Here's how and why this works...🧵
Prompt: e=mc^2
Prompt: e=mc^2

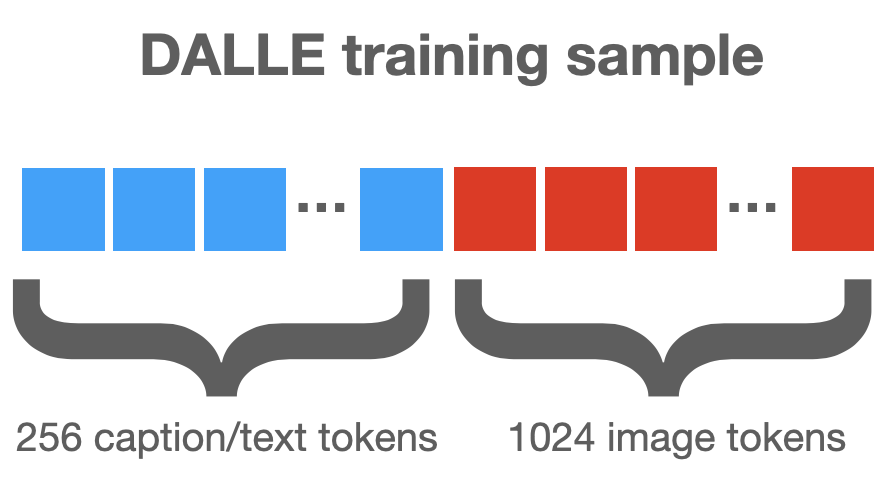
Prompts are fed to stable diffusion as binary code, with each letter/symbol represented as several bytes. Then a "tokenizer" looks for commonly occurring spans of adjacent bytes and groups them into a single known "word". Stable diffusion only knows 49408 words.
Here's "🧛🦇🗡️"
Here's "🧛🦇🗡️"


You might think 49408 is a lot. Well, it's not. Here's the first 1200 words in the vocabulary. They don't get you very far. The words are auto-selected by a simple algorithm and half are junk. And what are the weird "�" entries? We'll get back to them later...

Common english words, symbols, and *most* emojis are known to SD as a single "word."
Next, each "word" is replaced with a 512-dimensional "embedding vector". The result is a list of at most 77 such embedding vectors.
Prompt: 🧑🚀👽🛰️🌌 🔥🍄
Next, each "word" is replaced with a 512-dimensional "embedding vector". The result is a list of at most 77 such embedding vectors.
Prompt: 🧑🚀👽🛰️🌌 🔥🍄

These vectors go into a large neural network that makes the image. All emojis are represented by fairly similar embedding vectors. In fact, most emojis lie closer to unrelated emojis than to any English word. Still, the model understands the unique meaning of each emoji.

Unfortunately, there's a LOT of possible unicode characters and words - too many to have a separate embedding vector for each. Remember those "�" things? When unusual stuff comes along it's broken into individual bytes and represented using these emergency "words".
But there's only 256 different bytes, so we can have a separate embedding vector for each byte. Stable Diffusion is trained on 2 billion captions, so it learns to recognize many byte sequences even if they aren't in the vocabulary of "common" words that get their own vector.
Let's look at some of the rejects. Unlike most emojis,🏯 and📜 are not commonly used enough to be part of the 49K-word vocabulary. The closest conventional word to 🏯 in embedding space is "yin" (as in "yin and yang"). The closest word to 📜 is "news".
Here's "🏯🔥🐉 📜"
Here's "🏯🔥🐉 📜"




Emojis that represent writing implements are not widely used. 🖍 and 🖊 have to stay as raw bytes. But the neural net recognizes their byte sequences and associates them with artistic styles. In fact, you can control the style of an image by placing one in your prompt.



Text tokenization is a topic that is often dismissed as tedious and boring, but I think it's weirdly fascinating. Maybe that says more about me than about tokenization, though. Hopefully some of you out there in Twitterland agree. Thanks for reading!
• • •
Missing some Tweet in this thread? You can try to
force a refresh