
🎉Introducing RoentGen, a generative vision-language foundation model based on #StableDiffusion, fine-tuned on a large chest x-ray and radiology report dataset, and controllable through text prompts!
@PierreChambon6 @Dr_ASChaudhari @curtlanglotz
🧵#Radiology #AI #StanfordAIMI
@PierreChambon6 @Dr_ASChaudhari @curtlanglotz
🧵#Radiology #AI #StanfordAIMI
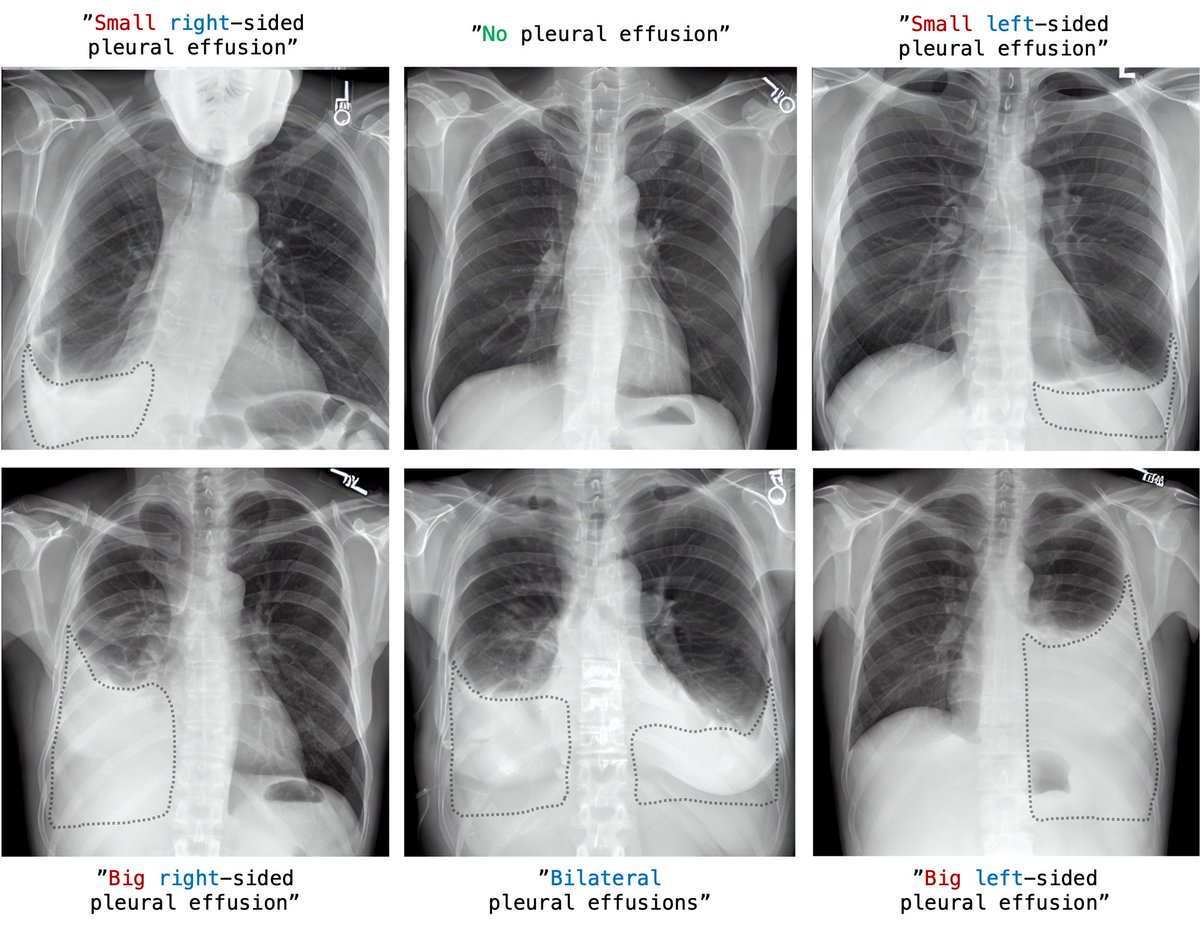
#RoentGen is able to generate a wide variety of radiological chest x-ray (CXR) findings with fidelity and high level of detail. Of note, this is without being explicitly trained on class labels.

Built on previous work, #RoentGen is a fine-tuned latent diffusion model based on #StableDiffusion. Free-form medical text prompts are used to condition a denoising process, resulting in high-fidelity yet diverse CXR, improving on a typical limitation of GAN-based methods.

Context: Latent diffusion models like #StableDiffusion trained on large natural image-text datasets like @laion_ai’s #LAION-5B are able to generate highly realistic images controlled by text prompts, but their knowledge about specific domains like medical imaging is limited.

Few-shot fine-tuning of #StableDiffusion with a prior-preserving loss (#DreamBooth) previously allowed us to insert pathologies in generated CXR by text prompt, but the generated images show comparatively little diversity and are constrained to the classes used during training.

After scaling to tens of thousands of CXR image-report pairs, SD starts replacing previously learned concepts in favor of medical domain-specific concepts like radiographic abnormalities (e.g., pleural effusions) with increasing levels of correctness and new abilites.

#RoentGen developed the ability to control CXR appearance with appropriate medical terminology and concepts. Note how in the first image, the generated images are in line with the radiological convention of displaying the right patient side on the left side of the image.

Compared to previous work, the outputs show a high degree of diversity. Note the variable appearance of the right-sided pleural effusion with varying amounts of interlobar fluid (top row, white arrowheads) for “big right (left) sided pleural effusion with adjacent atelectasis”.

Why synthetic CXR? They can be used to improve downstream tasks! Fine-tuning RoentGen on fixed training data yields a 5% improvement of a classifier trained jointly on synthetic and real images, and a 3% improvement when trained on a larger but purely synthetic training set.

Outside of data augmentation, this high level of control over the generated output also opens up new ways for data sharing (sharing models instead of the data itself), education and could be used to mitigate data imbalances and biases.
To balance the benefits of open-source science with the challenges of improper use of generative models, we aim to ensure sharing weights in accordance with the data usage agreement of MIMIC-CXR.
Weights can be requested in a tiered release at: forms.gle/Ggu2Kbu2MjMjxw…
Weights can be requested in a tiered release at: forms.gle/Ggu2Kbu2MjMjxw…
This project was a strong team effort accomplished by @PierreChambon6 Jean Benoit Delbrouck @sluijsjr @MPolacin @JMZambranoC @curtlanglotz @Dr_ASChaudhari from @StanfordAIMI and @StanfordRad and made possible with the help of @iScienceLuvr and S. Purohit from @StabilityAI.
That’s it! If you want to know more, check out the following resources:
Full preprint (arXiv): arxiv.org/abs/2211.12737
Project website: stanfordmimi.github.io/RoentGen/
#StanfordAIMI @StanfordAIMI @StanfordHAI
Full preprint (arXiv): arxiv.org/abs/2211.12737
Project website: stanfordmimi.github.io/RoentGen/
#StanfordAIMI @StanfordAIMI @StanfordHAI
• • •
Missing some Tweet in this thread? You can try to
force a refresh









