
We just introduced PyTorch 2.0 at the #PyTorchConference, introducing torch.compile!
Available in the nightlies today, stable release Early March 2023.
Read the full post: bit.ly/3VNysOA
🧵below!
1/5
Available in the nightlies today, stable release Early March 2023.
Read the full post: bit.ly/3VNysOA
🧵below!
1/5
PyTorch 2.0 introduces torch.compile, a compiled mode that accelerates your model without needing to change your model code. On 163 open-source models ranging across vision, NLP, and others, we found that using 2.0 speeds up training by 38-76%.
2/5
2/5

PyTorch 2.0 is *100%* backward-compatible.
The codebase is the same, the APIs are the same, and the way you write models is the same.
We are calling it 2.0 because it marks adding a significant new set of features.
3/5
The codebase is the same, the APIs are the same, and the way you write models is the same.
We are calling it 2.0 because it marks adding a significant new set of features.
3/5
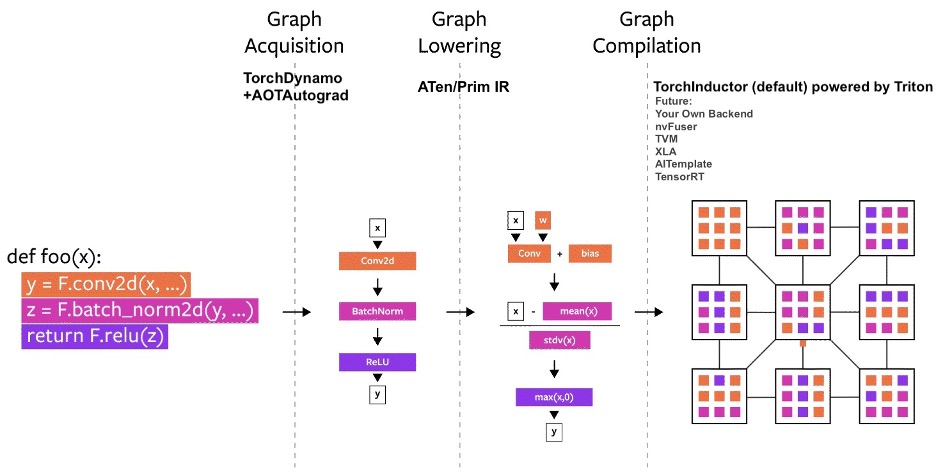
New components in PyTorch 2.0.
- TorchDynamo generates FX Graphs from bytecode analysis
- AOTAutograd generates backward graphs ahead-of-time
- PrimTorch introduces a small operator set to make backends easier
- TorchInductor: a DL Compiler powered by OpenAI Triton
4/5
- TorchDynamo generates FX Graphs from bytecode analysis
- AOTAutograd generates backward graphs ahead-of-time
- PrimTorch introduces a small operator set to make backends easier
- TorchInductor: a DL Compiler powered by OpenAI Triton
4/5
Keep an eye out for more news around the release of PyTorch 2.0 in the upcoming months. In the meantime, you can read more about the technology, benchmarks and how to get started here: bit.ly/3VNysOA
#PyTorchConference
5/5
#PyTorchConference
5/5
• • •
Missing some Tweet in this thread? You can try to
force a refresh









