
אז הגיע הזמן הזה בשנה שבו אני צופה בכל ה-Keynotes מ #reInvent2022 של @awscloud כדי שאתם לא תצטרכו!
ארכז פה את ההכרזות המעניינות, עם דגש על דטה ו-ML, אבל לא רק. מאחר וזה הולך להיות ארוך, יש מקרא emoji: חידושים ב-AI (🤖), חידושים בדטה (📊) וסתם דברים מגניבים שאהבתי (☁️):
ארכז פה את ההכרזות המעניינות, עם דגש על דטה ו-ML, אבל לא רק. מאחר וזה הולך להיות ארוך, יש מקרא emoji: חידושים ב-AI (🤖), חידושים בדטה (📊) וסתם דברים מגניבים שאהבתי (☁️):

לפני שצוללים, כמה Themes שעלו מההכרזות:
1.🤖 אמזון מרחיבים את ה-offering סביב שירותי הדטה ו-ML כדי להתחרות יותר ב-Databricks. זה בא לידי ביטוי במספר הכרזות שביחד משחזרות כמה מה-Signature Features של Databricks, כמו שתקראו למטה. לדעתי זה דבר שהיה צריך לקרות מזמן, ועל חשבון מגוון
1.🤖 אמזון מרחיבים את ה-offering סביב שירותי הדטה ו-ML כדי להתחרות יותר ב-Databricks. זה בא לידי ביטוי במספר הכרזות שביחד משחזרות כמה מה-Signature Features של Databricks, כמו שתקראו למטה. לדעתי זה דבר שהיה צריך לקרות מזמן, ועל חשבון מגוון

פיצ׳רים אחרים שאמזון שיחררו ב-SageMaker בשנים האחרונות (ושלדעתי אף אחד לא משתמש בהם).
באופן דומה, אמזון סימנו את תחום ה-GeoSpatial כקטגוריה למיקוד תחת SageMaker, ומתחרים בענקית אחרת, ESRI, באיזורים מסויימים.
באופן דומה, אמזון סימנו את תחום ה-GeoSpatial כקטגוריה למיקוד תחת SageMaker, ומתחרים בענקית אחרת, ESRI, באיזורים מסויימים.

2.📊 אמזון הציגה את חזון ה-“Zero ETL”. הרעיון הוא להרחיב את יכולות ה-No/low code בכל מה ש קשור באינטגרציות דטה. תהליך מבורך וסופר שימושי, גם אם בסיסי. האמת שהעובדה שאינטגרציות דטה באמזון לא ממש עובדות ככה היום היא די מפתיעה – בכמה עננים מתחרים זה קיים במידה,

(לא מזמן החמאתי פה למיקרוסופט על ה-no code indexer המצוין של Azure).
3. מבחינת החוויה ב-Keynotes עצמם, אם פעם היו מרכזים הכרזות של פיצ׳רים (אפילו קטנים יחסית) ב-Keynote, היום זה הרבה יותר Show, עם לקוחות שעושים דברים מעוררי השראה (פיתוח תרופות לסרטן וכו׳ והרבה פירוטכניקה. למי שנוכח פיזית זו באמת חוויה מדהימה. לצפיה מרחוק זה כנראה מבאס.
אז יאללה, נתחיל בחידושים בתחום ה-AI. קבלו 7 הכרזות מעניינות הכנס (לא ממויין לפי סדר חשיבות):
1. 🤖 שוחרר הדור הבא של Notebooks ב-AWS. המחברות האלה הן משהו פשוט ושימושי שהרבה DSים (Data Scientists) אוהבים. עד היום הן היו בסיסיות, פשוט Jupyter Notebook עם בקאנד מנוהל אוטומטית (במקום איזו מכונה על EC2). היום הן מקבלות שלושה שיפורים חשובים ומגניבים:
א. 🤖 אינטגרציה עם Data Wrangler לטובת Data Prep (אבחון בעיות וניקוי של הדטה) בתוך ה-Notebooks עם חבילת sagemaker_datawrangler. איך זה עובד? החבילה מספקת ממשק מעל Pandas DataFrames, ומספקת UI שמוזרק לתוך המחברת בעת הדפסה של ה-df. בתוך ה-UI הזה ניתן לבצע פעולות ניקוי למינהן

(להיפטר משורות עם ערכים בעיתיים וכו׳). בלחיצה על Apply, החבילה מג׳נרטת את קוד הפייתון לביצוע הטנספורמציות ומזריקה אותו לתא מתחת.

ב. 🤖 תמיכה בעריכה קולבורטיבית של מחברות (*אהמ אהמ* קולאב), ״גוגל דוקס סטייל״.

ג. 🤖 אוטומציה של הרצת מחברות עם SageMaker Notebook Jobs. זה פיצ׳ר חזק ביותר (שקיים בצורה דומה ב-Databricks) כי הוא מאפשר ל-Data Scientist שעובדת ב-Notebook להפוך לכלי אורקסטרציה לג׳ובים ברמה של פרודקשן (מה שעד היום דרש פיתוח נפרד, בד״כ בידי מהנדס אחר).


אגב בזמנו בסקייליין פיתחתי משהו דומה לזה כאופן סורס - github.com/orcaman/nb_to_…
2. 🤖 יכולות משופרות לעשות אריזה למחברות ומודלים כ-Shareable Artifacts עם SageMaker JumpStart. זו יכולת ממש מגניבה לייצר קטלוג מחברות ומודלים שיוזרים אחרים בארגון יכולים לגשת אליו, למצוא מה שרלוונטי להם, לכוונן פרמטרים ולהריץ. חזק מאוד לדעתי.

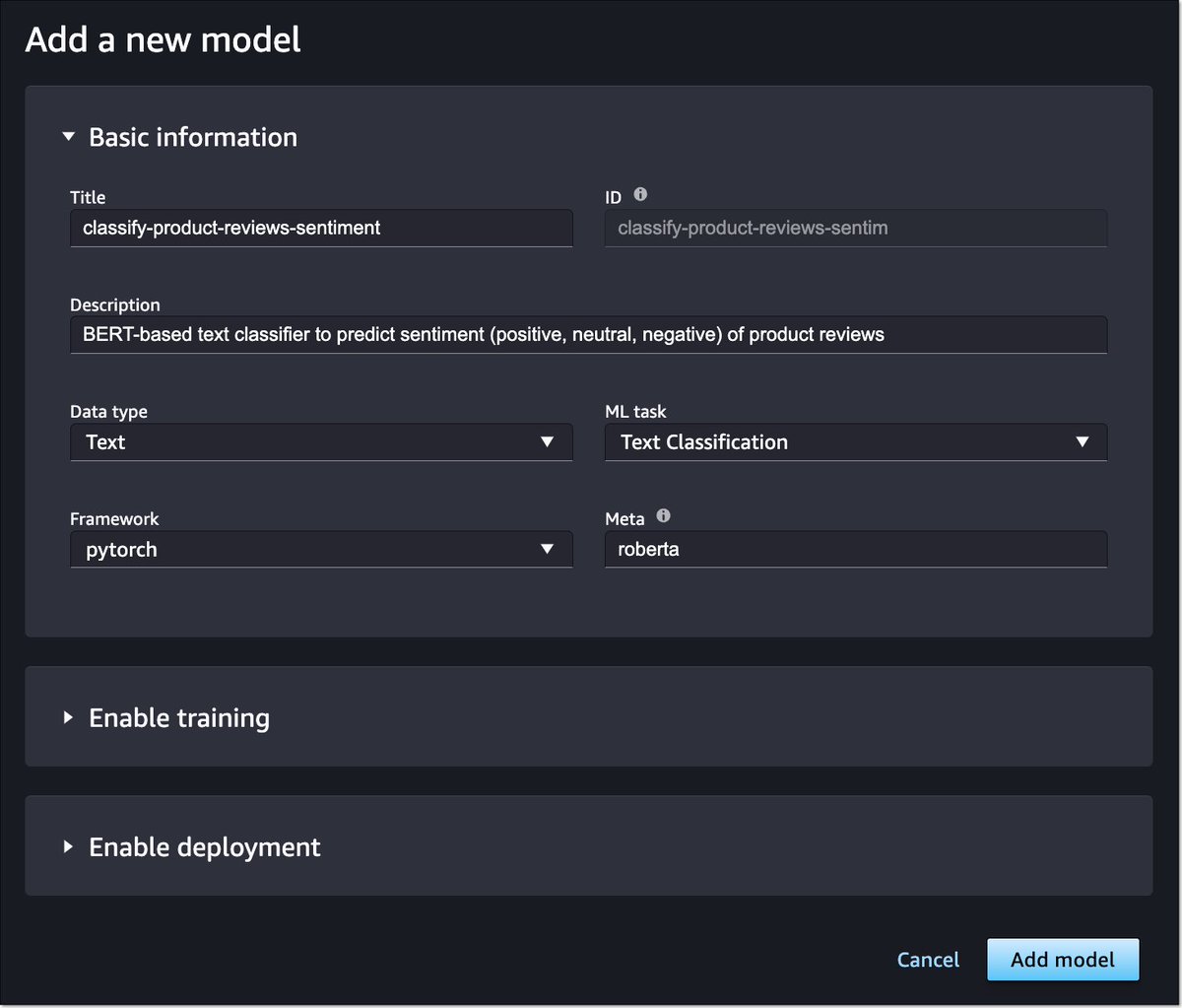

3.🤖 תמיכה ב-Data Wrangler Pipelines בתהליך ה-Inference: עד עכשיו, אם עשיתם שימוש ב-Data Wrangler כדי לייצר טרנספורמציות בתהליך הכנת וניקוי הדטה – באופן טיפוסי בצד של ה-Training של המודל, הייתם צריכים לקודד מחדש באופן ידני את כולן בצד ה-Inference (הקוד שקוראים לו כדי לייצר

פרדיקציה), כי הוקטור שמתקבל כקלט צריך לעבור אותן כדי שהמודל יוכל לעבד אותו. עכשיו ניתן לשחזר את אותן טרנספורמציות באופן אוטומטי לשימוש בצד ה-Inference.
4. 🤖 כלי governance ל-SageMaker: זו הכרזה שמורכבת משלושה רכיבים סביב הנושא של governance:
א. סט מובנה של Roles לפי Use cases (למשל כדי לייצר הפרדה בין הרשאות ל-Data Scientist מול ה-MLOps, הראשונה צריכה גישה לS3 והרצת ניסויים, השני צריך צריך גישה לייצר Jobs ו-Endpoints, גישה ל-ECR וכו׳.


ב. יישות חדשה שאמור לרכז את כל ה-metadata על המודל – SageMaker Cards. דברים כמו הביצועים שלו מצד אחד אבל גם מטרות השימוש והסיכונים


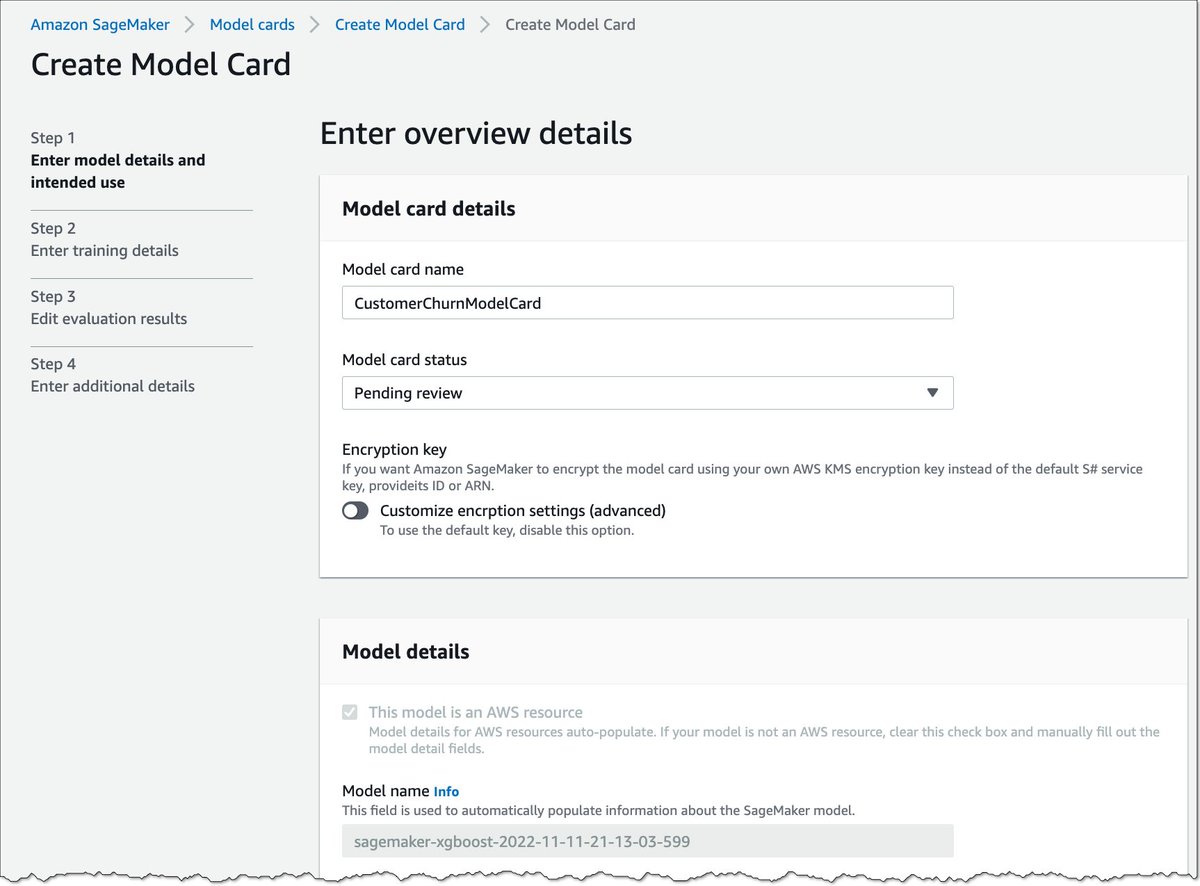
ג. דשבורד מודלים שמציג את כל ה-Cards הנ״ל

5.🤖 הכרזה מיוחדת בנוף: אמזון החליטו לקחת את הנושא של GeoSpatial Analysis ברצינות ולהקדיש לו סקשן משל עצמו ב-SageMaker. ביחד, הכלים האלה יכולים להתחרות בפלטפורמה של ESRI שהיום שולטת בשוק הזה. ל-SageMaker Studio הולך להתווסף מקטע בשם GeoSpatial שיש בו ארבעה Wizards למטרות שונות:


א. Earth Observation jobs: איזור ב-SageMaker שלוקח אתכם שלב אחרי שלב ביצירת תובנות על סמך צילומי לווין (ממקורות מידע כמו לוויני Copernicus Sentinel- שכבר נמצאים ב-Open Data של AWS). המודלים הנתמכים כרגע הם Spectral Index, Cloud Masking, Land Cover Segmentation, ואני לא אעמיק


בזה כאן יותר מזה - מדובר בגדול בסט של pretrained ML models ואופרטורים לתמרון דטה גיאוגרפי שמשולבים בסטודיו בצורה יפה.
מעבר לעבודה בתוך הסטודיו, ניתן כמובן גם לייצא את העבודה ל-SageMaker Notebook ולהמשיך שם יותר פריסטייל בפייתון.
מעבר לעבודה בתוך הסטודיו, ניתן כמובן גם לייצא את העבודה ל-SageMaker Notebook ולהמשיך שם יותר פריסטייל בפייתון.
ב. Vector Enrichment jobs – מתוך SageMaker Notbooks, ניתן לאתחל ג׳ובים שמטרתם להעשיר את הדטה במידע גיאוגרפי. הקלאסי זה Reverse Geocoding (המרה של קואורדינטות לכתובת – פעולה שכיחה מאוד גם אצלנו ב-JLL, כשאנחנו רוצים להבין מה סט הכתובות האפשרי של נכס נדל״ן)

ו- Map Matching (מיפוי של קואורדינטות GPS למקטעים של דרכים וכבישים במפה).
ג. כלי ויזואליזציה למפות מובנה בסטודיו – כלי שיודע לקבל GeoJSON (פורמט סטנדרטי לתיאור של מידע גיאוגרפי) ולרנדר אותו על מפה. אפשר לטעון כמה דטסטים ביחד כמובן (נניח בתי ספר ממקור אחד ונכסי נדל״ן ממקור אחר)

ד. SageMaker Notebooks שמגיעים עם ספריות מותקנות מראש לצרכי תמרון דטה גיאוגרפי – GeoPandas, Rasterio, GDAL, Fiona ועוד.
6.🤖 הוכרז SageMaker Shadow Testing – פיצ׳ר חמוד ב-SageMaker Endpoints שמאפשר Traffic Split בין מודלים לטובת A/B Testing (בסגנון מה שכבר קיים ב-AWS Lambda). נכון לעכשיו, יש דשבורד שמראה מטריקות לא מעניינות לדעתי (בעיקר סביב צריכת זיכרון, CPU וכו׳),


אבל אפשר לצפות שבעתיד יהיה אפשר לחבר לשם כל CloudWatch Metric.
7.🤖 אמזון CodeWhisperer מעלה הילוך: נוספה תמיכה ב-SSO (ללקוחות Enterprise בעיקר) ובכמה שפות (C# ו-TypeScript, עד עכשיו היה רק Python, Java ו-JavaScript). פגשתי את מי שאחראי על המוצר באמזון בכנס ומאוד התרשמתי מהכיוון שזה הולך אליו. תחרות אמיתית ל-Copilot, במיוחד לארגונים גדולים.
יאללה, עברנו להכרזות בתחום הדטה 📊:
1.📊 יריית הפתיחה של חזון ה-Zero ETL: שתי אינטגרציות No code ל-Data Warehouse של אמזון, Redshift: auto copy from S3 ו-Aurora Zero-ETL Integration. השמות די מסבירים את עצמם אז לא אעמיק פה. מדובר בשתי יכולות אמנם בסיסיות למדי אבל סופר שימושיות,


ואני בטוח שיאיצו את האדופשן של Redshift / ישפרו flows קיימים שנכתבו ״ידנית״.
2.📊 סיבה לדאגה ל-Databricks? עטיפת Athena מעל Spark. כמו שפעם היינו חייבים לטעון קבצי CSV ל-SQL על מנת לתשאל אותם, ו-Athena אפשר לעשות את זה ישירות מעל S3, עכשיו ניתן לעשות את אותו הדבר לפרקטים מבלי להרים Spark Cluster.

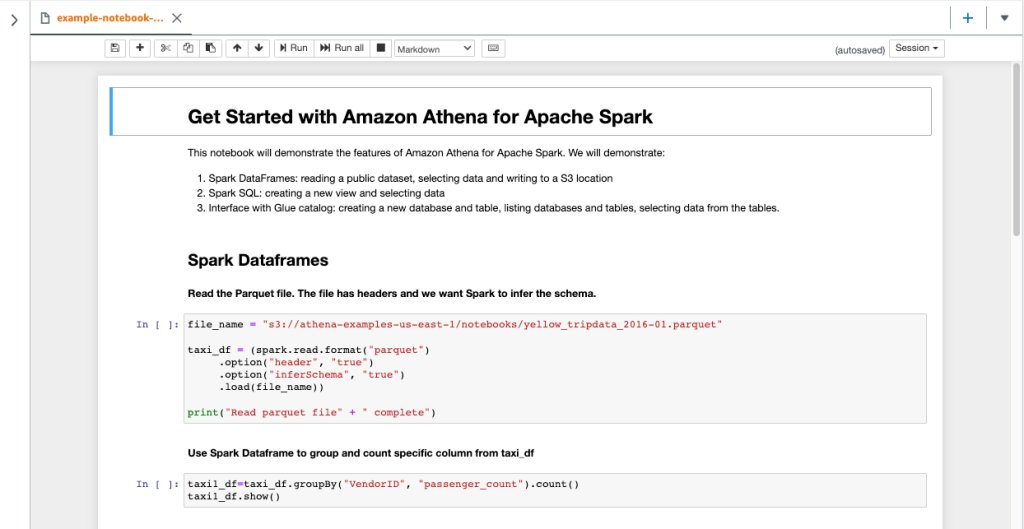
המשמעות: עבודה עם Spark DataFrames, Spark SQL בצורה “Serverless” מתוך Jupyter Notebook מעל אמזון.

3.📊 המלחמה עם elastic מעלה הילוך: הוכרז OpenSearch (ה-Clone של אמזון ל-ElasticSearch) בגירסת Serverless. כמו כל Serverless infa, המטרה היא לחסוך למפתחים התעסקות עם המשאבים של הקלאסטר ולתת לפלטפורמה לעשות Scaling בצורה אוטומטית על בסיס העומס.
התוצאה של זה בפועל היא חיסכון בעלויות (לא חייבים להחזיק קלאסטר גדול כל הזמן במקרים שבהם קשה לצפות ספייקים בעומס).
4.📊 אינטגרצית Spark ל-Redshift: האינטגרציה מאפשרת טעינה של דטה מתוך Redshift אל Spark SQL DataFrames, וכתיבה שלהם בחזרה אל טבלאות ב-Redshift. בגדול אמזון לקחו אופן סורס שעושה את זה (github.com/spark-redshift…) ובנו מעליו (ובמקומו) משהו רשמי.
5.📊דיפלוי Blue/Green ל-RDS: זה פיצ׳ר שהולך לחסוך כאב ראש גדול להמון אנשים. אחת הדרכים לעדכן DB בפרודקשן (״כחול״) היא ע״י החלפה שלו בגירסה מסונכרת מסביבת הסטייג׳ינג (״ירוק״) שמכילה עדכונים. היום אנחנו עושים את זה בצורה ידנית (בקוד כמובן), והפיצ׳ר הזה ישדרג אותנו למשהו מנוהל


ועכשיו, לקטגוריה האחרונה של הכרזות: סתם דברים מגניבים שאהבתי בלי קשר לדטה ו-ML:
1.☁️ תמיכה ב-Parallel Map ל-Step Functions. למי שלא מכיר/ה, Step Functions זה Workflow Manager כזה של אמזון שמאפשר למדל Processing Pipeline בצורה ויזואלית או בקוד. לרוב כל שלב בפייפליין הוא למדה שעושה משהו (טרנספורמציה לדטה, I/O וכו׳). עד היום,

היה אפשר לייצר לולאה שמוגבלת ב40 הרצות של הפייפליין במקביל. העדכון שהוכרז מאפשר לעשות הרצה מקבילית של עד 10,000 ״צעדים״ (למדות), מה שהופך את כל הפלטפורמה הזו ליותר מעניינת לצרכי עיבוד נתונים ובכלל.
2. ☁️ שיפור בעיית ה-Cold Start בלמדה עם Lambda SnapStart: אחת הבעיות המוכרות בלמדה היא בעית ה-Cold Start. מצד אחד, אנחנו מרוויחים פונקציה ללא ניהול תשתיות, ומשלמים עליה רק מתי שהיא רצה, ברמת השניה. מצד שני, זה אומר כאשר אף אחד לא משתמש בפונקציה,

הסביבה שלה יורדת, ואז אם יש בקשה חדשה פתאום, היוזר חוטף דיליי רצחני בגלל הזמן שלוקח לאתחל את הסביבה (זה במיוחד בעייתי כשטוענים ספריות כבדות ויכול להגיע גם ל10 שניות). הפיתרון לזה עד היום היה לא להשתמש בלמדה, או לעשות Provisioned Concurrency – להחזיק מראש סביבות למעלה כל הזמן רק
למקרה שיגיעו יוזרים אחרי תקופה ממושכת של חוסר פעילות. אבל זה פיתרון יקר (יש שרתים שמוקדשים לנו עם הסביבות האלה כל הזמן), ולא נותן מענה למקרה שיש exceptions בקוד וצריכים להרים סביבה חדשה. SnapStart בא לפתור (או לשפר את זה):
מאחורי הקלעים, מיד אחרי ה-Init הראשון של פונקצית למדה חדשה, הפלטפורמה לוקחת Snapshot של הזיכרון ושמה אותו באיזה Cache (שפג אחרי 14 יום של חוסר פעילות או פיבלוש של גירסה חדשה). זה מאפשר לאתחל סביבות למדה הרבה יותר מהר במקרה של חוסר פעילות ומקצר את ה-Cold Start משמעותית
3.☁️ דטה סקיוריטי ב-CloudWatch: מכירים את זה שאתם מדפיסים מידע רגיש ב-GitHub Actions או כל טרמינל מנוהל אחר ובמקום המידע רואים כוכביות (******)? אז בשעה טובה זה מתאפשר עכשיו מעל CloudWatch Logs. יש מעל 100 תבניות built in לבחור מהן (דטה רגיש בעולמות ברפואה, פיננסים וכו׳)
כדי לבקש מ-CloudWatch למסך דטה רגיש בלוגים.
• • •
Missing some Tweet in this thread? You can try to
force a refresh




