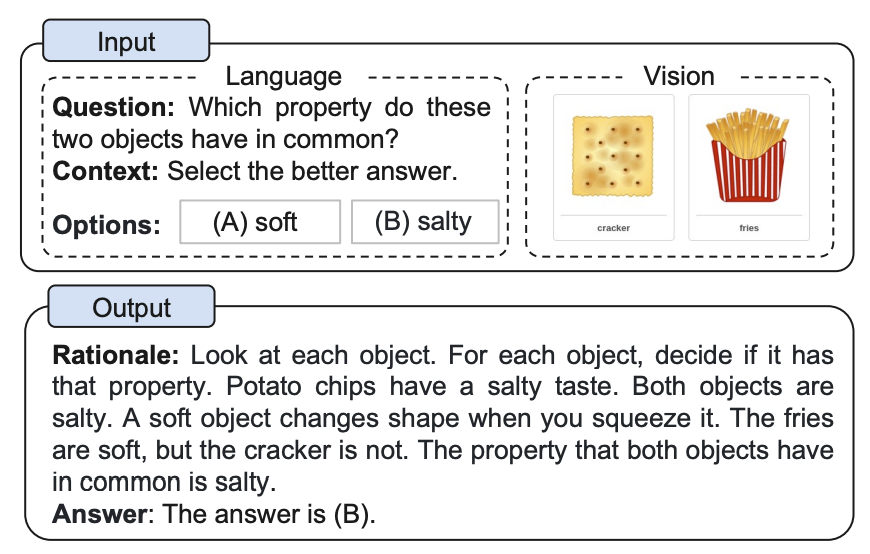
We want to pretrain🤞
Instead we finetune🚮😔
Could we collaborate?🤗
ColD Fusion:
🔄Recycle finetuning to multitask
➡️evolve pretrained models forever
On 35 datasets
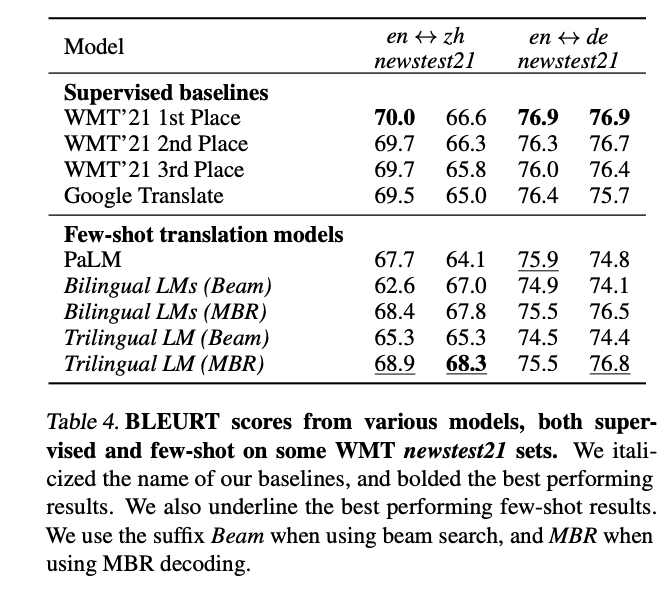
+2% improvement over RoBERTa
+7% in few shot settings
🧵
#NLProc #MachinLearning #NLP #ML #modelRecyclying
Instead we finetune🚮😔
Could we collaborate?🤗
ColD Fusion:
🔄Recycle finetuning to multitask
➡️evolve pretrained models forever
On 35 datasets
+2% improvement over RoBERTa
+7% in few shot settings
🧵
#NLProc #MachinLearning #NLP #ML #modelRecyclying
We all wish to improve pretraining
If only we had unlimited compute and data...
Together we have!
We propose a way to recycle finetuning
and transform it into multitask learning!
arxiv.org/abs/2212.01378
@Shachar_Don @VenezianElad @colinraffel @noamslonim @YoavKatz73 me
If only we had unlimited compute and data...
Together we have!
We propose a way to recycle finetuning
and transform it into multitask learning!
arxiv.org/abs/2212.01378
@Shachar_Don @VenezianElad @colinraffel @noamslonim @YoavKatz73 me
How to perform multitasking, by simply uploading models?
Collaborative Descent (ColD) Fusion is simple:
Start from a pretrained model
Let contributors finetune on it, and share their models
Fuse the models to get a new better model
Take the improved model as the new best model
Collaborative Descent (ColD) Fusion is simple:
Start from a pretrained model
Let contributors finetune on it, and share their models
Fuse the models to get a new better model
Take the improved model as the new best model

What is fusing?
In short, it is creating one model from several
Practically, we just average the weights of finetuned models and it is good enough
More fusing methods and details:
In short, it is creating one model from several
Practically, we just average the weights of finetuned models and it is good enough
More fusing methods and details:
https://twitter.com/LChoshen/status/1513445649890615297
So we can iteratively collect finetuned models from the community and get better models. What could that achieve?
A) learn on the tasks contributed along the way (Fig)
B) become a better pretrained model!
and keep improving with more data and contributors!
A) learn on the tasks contributed along the way (Fig)
B) become a better pretrained model!
and keep improving with more data and contributors!

As a pretrained
🟦ColD Fusion is just great!
🟩much better than multitasking
⬜️not to mention vanilla RoBERTa
We did not expect that, but we surely did not expect to
🟧beat MUPPET!
SoTA multitask on more datasets, tuned, tweaks and all
We have none of those, just a new method
🟦ColD Fusion is just great!
🟩much better than multitasking
⬜️not to mention vanilla RoBERTa
We did not expect that, but we surely did not expect to
🟧beat MUPPET!
SoTA multitask on more datasets, tuned, tweaks and all
We have none of those, just a new method

It also does as well on unseen datasets as on the 35 seen datasets (top yellow blue)
but remember, it is a pretrained model, are you surprised finetuning on data already seen in pretraining\multitask is not helpful?
More details in the paper...
but remember, it is a pretrained model, are you surprised finetuning on data already seen in pretraining\multitask is not helpful?
More details in the paper...
ColD Fusion provides great benefits when only 100 test examples are available
*These improvements are few shot on unseen dataset
*These improvements are few shot on unseen dataset

To sum, ColD Fusion allows a model
to continually evolve
♻️just share and recycle
We have the algorithm, now we just need to start using it!
Creating a platform and scaling is our next goal, interested? contact us.
Let's do it together!
Models: huggingface.co/ibm/ColD-Fusion
to continually evolve
♻️just share and recycle
We have the algorithm, now we just need to start using it!
Creating a platform and scaling is our next goal, interested? contact us.
Let's do it together!
Models: huggingface.co/ibm/ColD-Fusion
• • •
Missing some Tweet in this thread? You can try to
force a refresh