
🥇 LLMs together (co-created model merging, BabyLM, https://t.co/MzhDgAjfxQ)
🥈 Spreading science over hype in #ML & #NLP
Proud shareLM💬 Donor
@IBMResearch & @MIT
 Lora as you probably know learns in addition to W (some dense matrix e.g. the fully connected) AB, two matrices (of low dim between them)
Lora as you probably know learns in addition to W (some dense matrix e.g. the fully connected) AB, two matrices (of low dim between them)
 So we have seen papers showing that models gain a lot from seeing examples (ICL) with random labels
So we have seen papers showing that models gain a lot from seeing examples (ICL) with random labels  The story is very simple
The story is very simple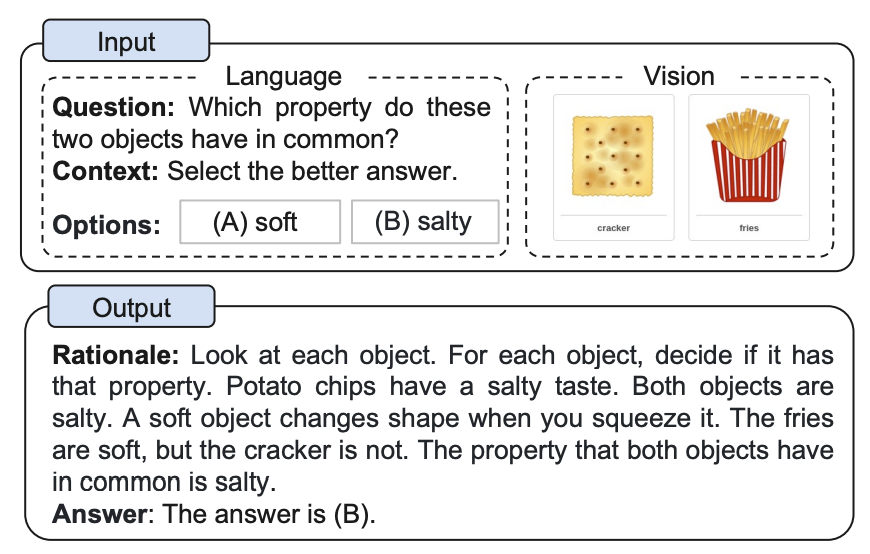 What is this Chain of Though everyone are talking about?
What is this Chain of Though everyone are talking about?
 The setting is quite simple:
The setting is quite simple:

 The main idea behind pretraining claims that, given some hard enough loss, we can train on a lot of data and learn how the world works so well, that we could easily transfer this knowledge to perform the tasks we really care about.
The main idea behind pretraining claims that, given some hard enough loss, we can train on a lot of data and learn how the world works so well, that we could easily transfer this knowledge to perform the tasks we really care about.

 It all started on ICLR2015(!)
It all started on ICLR2015(!)
 Take two models, put them in the loss space
Take two models, put them in the loss space
 The basic idea is quite simple:
The basic idea is quite simple:
 The paper creates synthetic languages (using a PCFG) with various ordering rules, being able to compare each order.
The paper creates synthetic languages (using a PCFG) with various ordering rules, being able to compare each order. 
