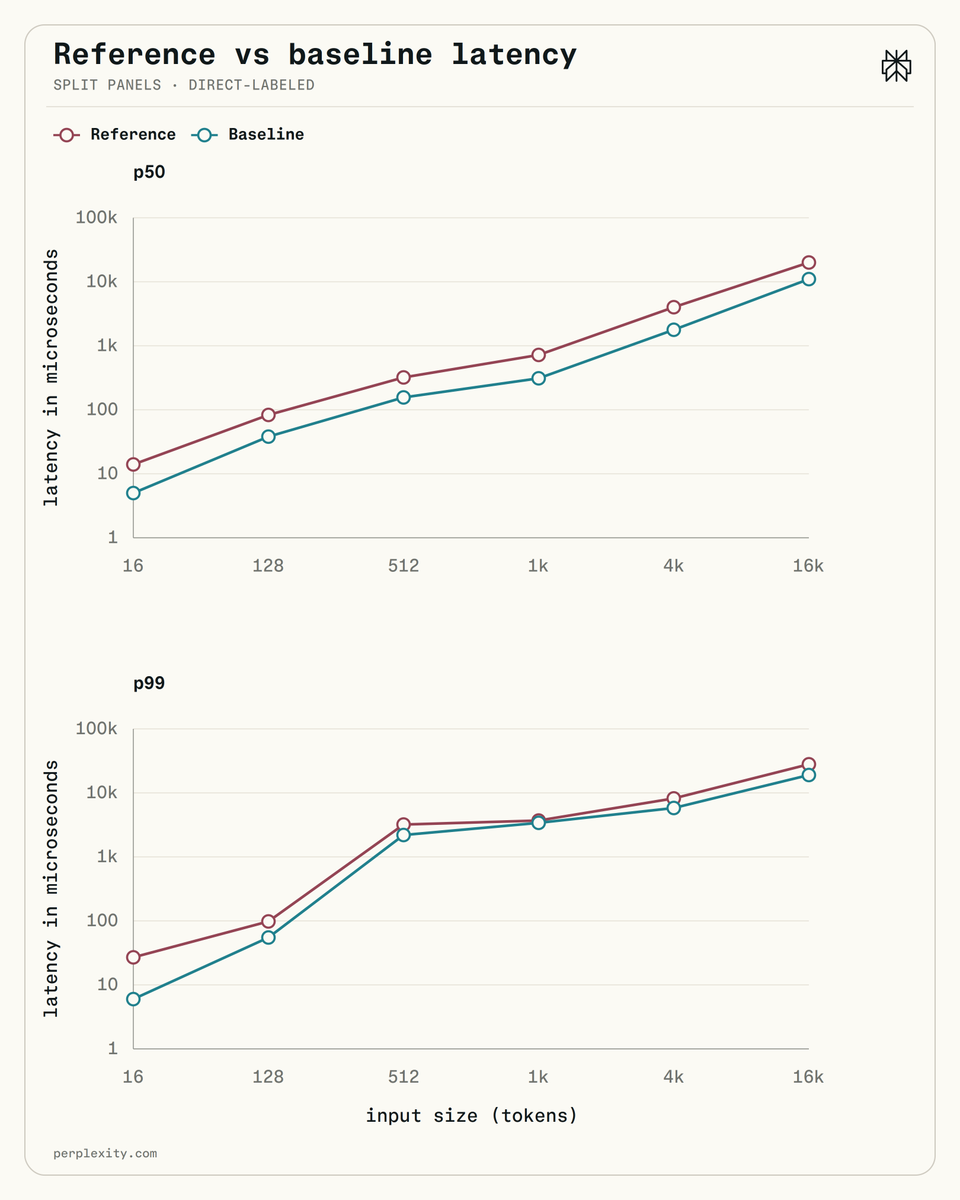
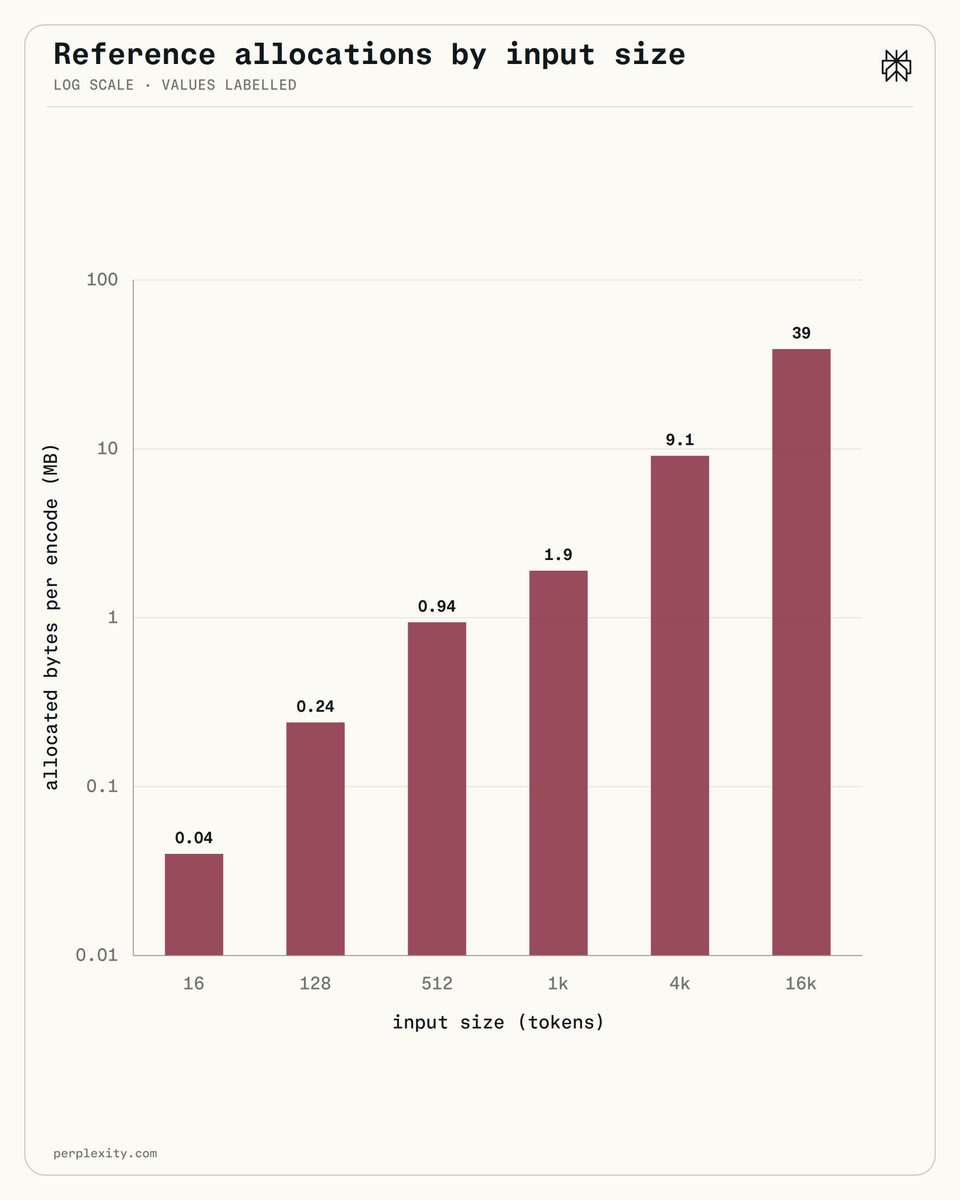
Introducing Bird SQL, a Twitter search interface that is powered by Perplexity’s structured search engine. It uses OpenAI Codex to translate natural language into SQL, giving everyone the ability to navigate large datasets like Twitter.
perplexity.ai/sql
perplexity.ai/sql
With Bird SQL, you can quickly find information on Twitter that would have been impossible to find with conventional search engines or web browsing:
"most liked tweets about #worldcup"
perplexity.ai/sql?uuid=9b03e…
"most liked tweets about #worldcup"
perplexity.ai/sql?uuid=9b03e…



Filter down to content you’re curious about:
"tweets about chatGPT liked by Elon Musk"
perplexity.ai/sql?uuid=0a675…
"tweets about chatGPT liked by Elon Musk"
perplexity.ai/sql?uuid=0a675…


Analyze social graphs:
"People followed by Jeff Bezos who don’t follow him back"
perplexity.ai/sql?uuid=b37ef…
"People followed by Jeff Bezos who don’t follow him back"
perplexity.ai/sql?uuid=b37ef…


If you are interested in using our search engine on your structured or unstructured data, contact us at support@perplexity.ai, our Discord server, or via Twitter. Join our Discord to learn more about search and large language models: discord.com/invite/kWJZsxP…
This is a demo, not a commercial product. There are limitations to our Twitter data, database performance, and the expressiveness of SQL. Bird SQL does not interpret the content of tweets. For unstructured search, try Perplexity Ask.
https://twitter.com/perplexity_ai/status/1600551871554338816
• • •
Missing some Tweet in this thread? You can try to
force a refresh