
This is the story of an embodied multi-modal agent crafted over 4 papers and told in 4 posts
The embodied agent is able to perceive, manipulate the world, and react to human instructions in a 3D world
Work done by the Interactive Team at @deepmind between 2019 and 2022
🧵
The embodied agent is able to perceive, manipulate the world, and react to human instructions in a 3D world
Work done by the Interactive Team at @deepmind between 2019 and 2022
🧵
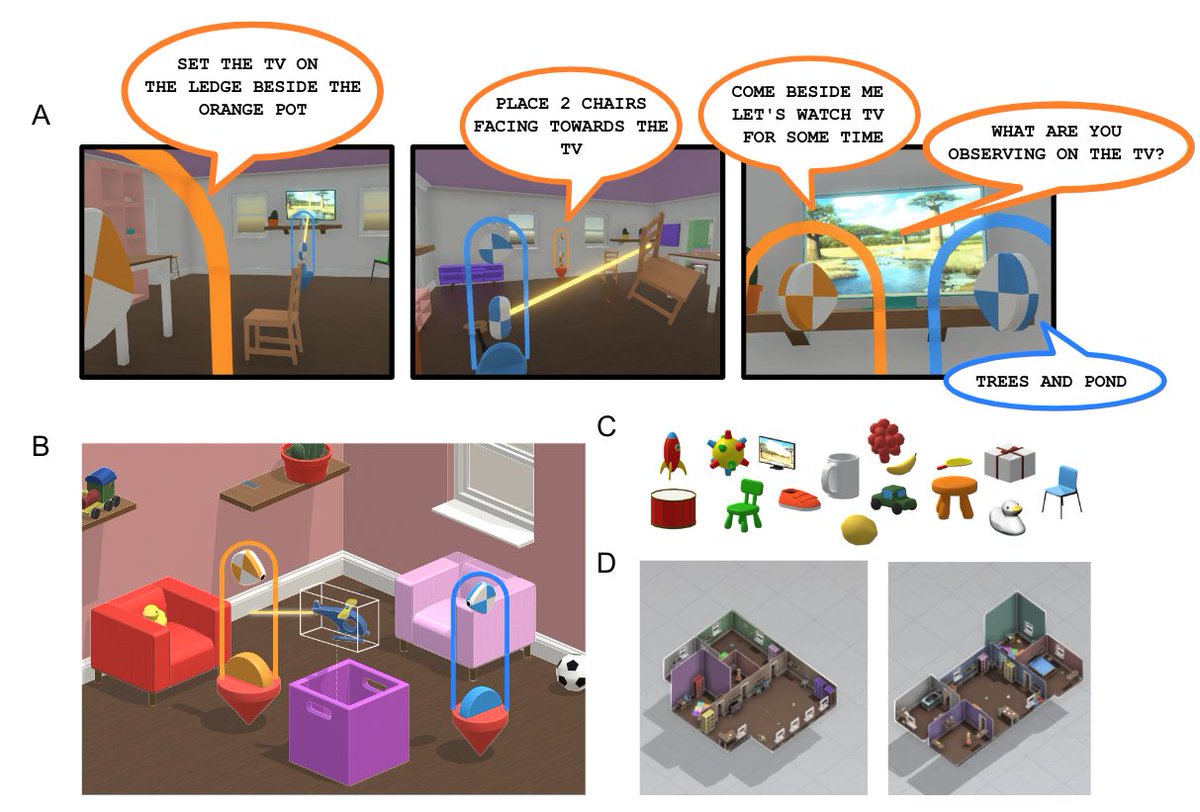
Imitating Interactive Intelligence arxiv.org/abs/2012.05672
The case for training the agent using Imitation Learning is outlined
The environment "The Playroom" is generated
The general multi-modal architecture is crafted
At the end, an auxiliary simil-GAIL loss is crucial
1/n
The case for training the agent using Imitation Learning is outlined
The environment "The Playroom" is generated
The general multi-modal architecture is crafted
At the end, an auxiliary simil-GAIL loss is crucial
1/n

Interactive Agents with IL & SSL
arxiv.org/abs/2112.03763
In the end it's all about scale and simplicity
The agent was hungry for data, so it was fed more
A simpler contrastive cross-modal loss replaced GAIL
A hierarchical 8-step action was introduced
New agent code name: MIA
2/n
arxiv.org/abs/2112.03763
In the end it's all about scale and simplicity
The agent was hungry for data, so it was fed more
A simpler contrastive cross-modal loss replaced GAIL
A hierarchical 8-step action was introduced
New agent code name: MIA
2/n

Evaluating Interactive Agents
arxiv.org/abs/2205.13274
Evaluation becomes the bottleneck
Agents evaluated with a new approach called Standardized Test Suite. Still manual, but offline. Faster, more interpretable & controllable
MIA on steroids. 164M params and LLM
3/n
arxiv.org/abs/2205.13274
Evaluation becomes the bottleneck
Agents evaluated with a new approach called Standardized Test Suite. Still manual, but offline. Faster, more interpretable & controllable
MIA on steroids. 164M params and LLM
3/n

https://twitter.com/lonzaandrea/status/1608465889053274112?ref_src=twsrc%5Etfw%7Ctwcamp%5Etweetembed%7Ctwterm%5E1608465889053274112%7Ctwgr%5E7cb197e4df533bfb27bd4fac8db6ac3ad468dc65%7Ctwcon%5Es1_c10&ref_url=https%3A%2F%2Fpublish.twitter.com%2F%3Fquery%3Dhttps3A2F2Ftwitter.com2Flonzaandrea2Fstatus2F1608465889053274112widget%3DTweet
Interactive Agent with RLHF
arxiv.org/abs/2211.11602
RL is introduced
A new breed of agent is created: similar to MIA but with RLHF tuning and a learned RW model
As always.. The agent ingested more data
Also a new interactive evaluation is introduced
4/n

Question: With the new RLHF approach, did it converge to a more standard training methodology?
Great work by the Interactive Agents Team at @deepmind : @arahuja @fede_carne @petko87ig @_agoldin @countzerozzz @TheGeorgePowell @santoroAI and others
#deeplearning #RL #ML #AI
END/n
Great work by the Interactive Agents Team at @deepmind : @arahuja @fede_carne @petko87ig @_agoldin @countzerozzz @TheGeorgePowell @santoroAI and others
#deeplearning #RL #ML #AI
END/n
• • •
Missing some Tweet in this thread? You can try to
force a refresh







