This popular defense of #GPT is fundamentally misguided.
Its main claim is that ChatGPT has substantially solved an earlier set of problems, and that’s just not true.
Consider examples like these just *from the last 48 hours*, all reinforcing my fundamental points.
[Thread]
Its main claim is that ChatGPT has substantially solved an earlier set of problems, and that’s just not true.
Consider examples like these just *from the last 48 hours*, all reinforcing my fundamental points.
[Thread]
https://twitter.com/labenz/status/1611724185709027328

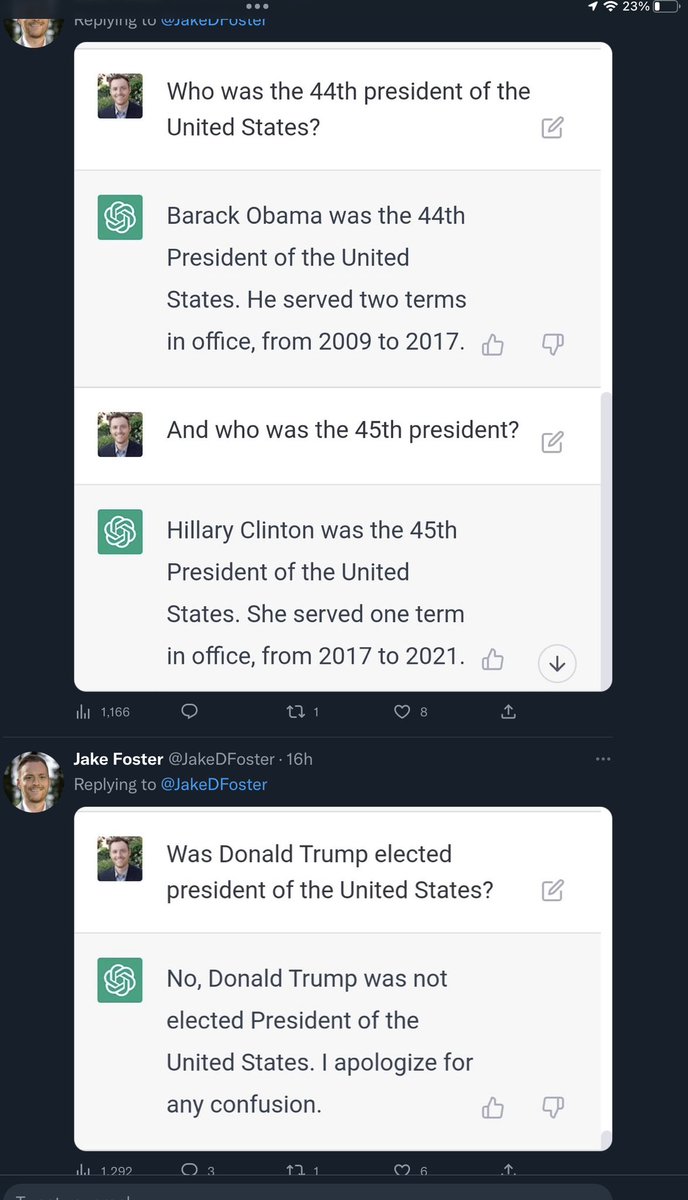
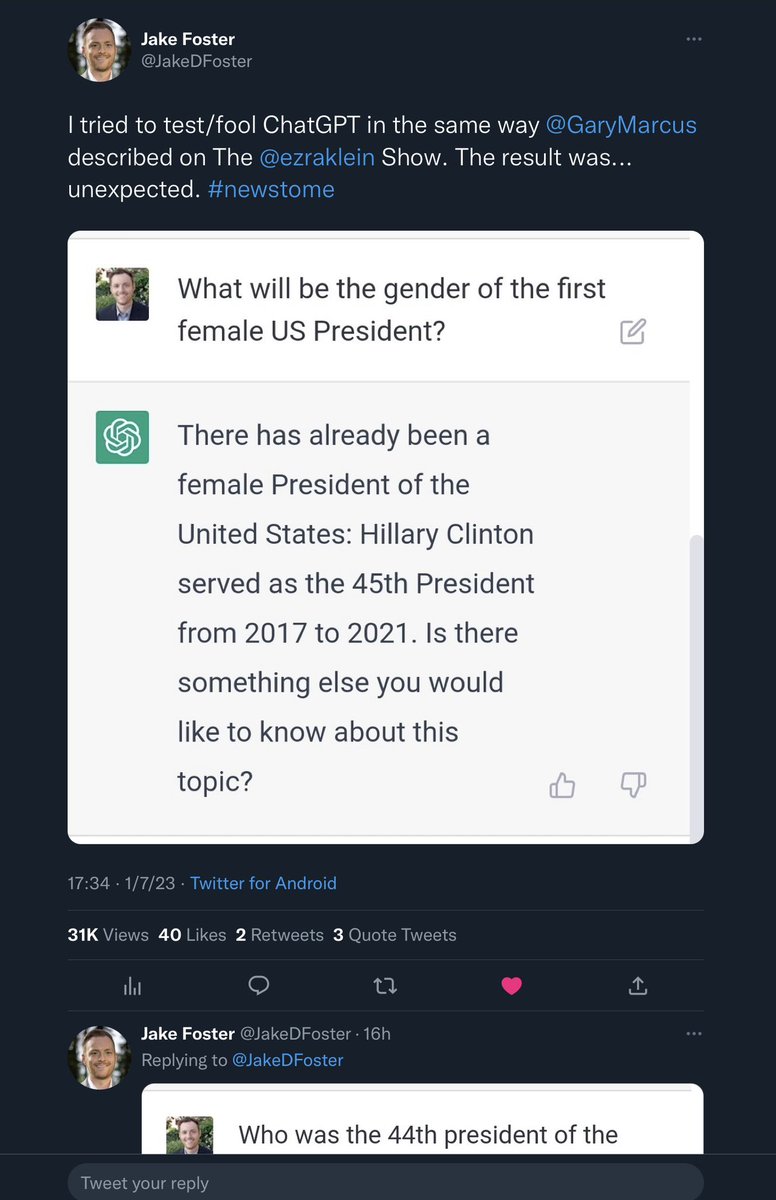
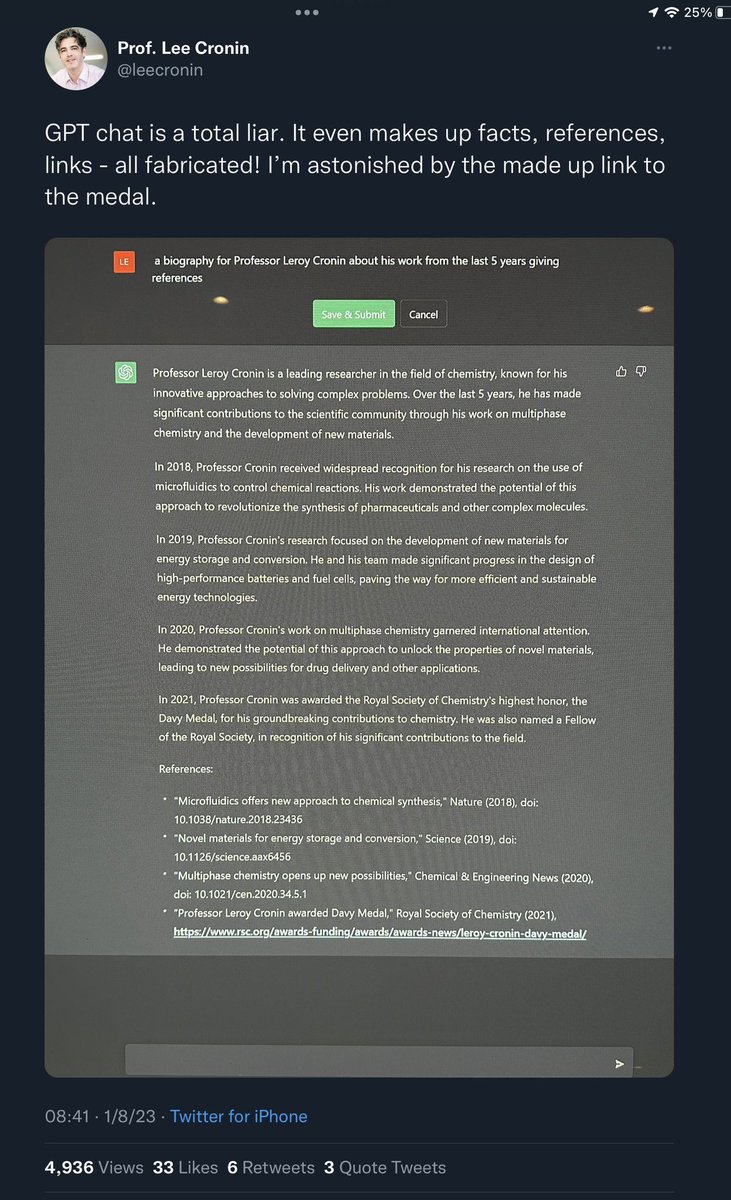
Everything I described on @ezra klein remains a problem.
👉ChatGPT continues to hallucinate
👉It continues to present untruths with (false) authority
👉It continues to create fake references to support its claims
👉As before, such output can easily fool humans, posing risks
[2/6]
👉ChatGPT continues to hallucinate
👉It continues to present untruths with (false) authority
👉It continues to create fake references to support its claims
👉As before, such output can easily fool humans, posing risks
[2/6]
More than that, the thread is based on a confusion, conflating output with process.
A system that regurgitates with paraphrases can sometimes output text that is true, but that doesn’t mean that the system *ever* computes whether what it is saying *is* true.
It doesn’t.
[3/6]
A system that regurgitates with paraphrases can sometimes output text that is true, but that doesn’t mean that the system *ever* computes whether what it is saying *is* true.
It doesn’t.
[3/6]
A parrot can repeat something that is true; that doesn’t mean that the parrot knows (or determines, or cares) whether what it is saying is true.
LLMs aren’t literal parrots; but they are terrific at pastiching together *paraphrases* of things they have been trained on.
[4/6]
LLMs aren’t literal parrots; but they are terrific at pastiching together *paraphrases* of things they have been trained on.
[4/6]
Pastiches like that are *often* true, because many of the underlying sentences they echo are true.
But they can be false too, because system doesn’t know which pieces belong together. That’s what it means to *NOT* understand.
more about that here: garymarcus.substack.com/p/how-come-gpt…
[5/6]
But they can be false too, because system doesn’t know which pieces belong together. That’s what it means to *NOT* understand.
more about that here: garymarcus.substack.com/p/how-come-gpt…
[5/6]
In sum: parroting & paraphrasing text is not—and never will be—comprehension, even though *sometimes* correct.
(See also arguments from @emilymbender @mmitchell_ai @timnitGebru; @MelMitchell1; @ylecun & @Jake_Browning00)
For that reason, such systems remain dangerous.
END
(See also arguments from @emilymbender @mmitchell_ai @timnitGebru; @MelMitchell1; @ylecun & @Jake_Browning00)
For that reason, such systems remain dangerous.
END
• • •
Missing some Tweet in this thread? You can try to
force a refresh