How to make forensically NOT reliable facial reconstructions with #midjourney.
I will explain you in detail the easy process and all the prompts used in my most controversial thread of 2023 (so far) so you can experiment too.
Here it goes 🧵👇
I will explain you in detail the easy process and all the prompts used in my most controversial thread of 2023 (so far) so you can experiment too.
Here it goes 🧵👇


First, the context.
I published this thread using MidJourney the other day.
The controversy was served! The reconstructions were NOT forensic nor, of course, scientifically correct.
I got into hot water 😔
I published this thread using MidJourney the other day.
The controversy was served! The reconstructions were NOT forensic nor, of course, scientifically correct.
I got into hot water 😔
https://twitter.com/javilopen/status/1612135377787301890
Come on!
Of course they weren't. How could they be if the AI used was not designed for that purpose and could not be fed with all the necessary input data?
Of course they weren't. How could they be if the AI used was not designed for that purpose and could not be fed with all the necessary input data?
The problem was that I didn't add a clear disclaimer at the beginning of the thread. Something like:
"Here's a half-hour NOT FORENSICALLY CORRECT experiment with MidJourney, to visually dream with the possibilities. No mummies suffered in the process. Come on in and enjoy!"
"Here's a half-hour NOT FORENSICALLY CORRECT experiment with MidJourney, to visually dream with the possibilities. No mummies suffered in the process. Come on in and enjoy!"

The fact is that, after spending a year non-stop experimenting with AI, sometimes I forget that not everyone who follows me understands that my intention is none other than to experiment with this technology in all possible ways and tell you all about it.
I enjoy it and many of those who follow me too. Fantasy or not.
https://twitter.com/javilopen/status/1605956386923220992
Sometimes, I encourage myself to touch on more "serious" subjects, but without straying too far from science fiction.
https://twitter.com/javilopen/status/1609595334799560706
And sometimes, I just really want to give you useful tools :)
https://twitter.com/javilopen/status/1613322733705650176
Nevertheless. Could AI be used to generate scientifically correct reconstructions?
Of course yes, as in the rest of the fields, AI could also be applied here.
But not with #midjourney: it's not made for this. MJ already does many wonders, don't ask it that much.
Of course yes, as in the rest of the fields, AI could also be applied here.
But not with #midjourney: it's not made for this. MJ already does many wonders, don't ask it that much.
We would need a specific AI, trained for this purpose, that could receive all the necessary data from the input. Among others: examinations of the skeletal remains (CT-scan or X-ray tomography), examinations of the preserved soft tissues, anatomical criteria, etc.

Disclaimer (just in case): I'm not an expert in forensic reconstructions, so I can't correctly list all the inputs that would be needed. You have to be careful on Twitter :)

The input data and the results of existing real works would be especially useful for training the model.

This could be done, so that it would be a significant sample to be able to feed the model, with blind tests: tests that are currently carried out in which input data is given to a professional (who does not see the photograph of the person trying to reconstruct )...

...but works with only the input data until it generates a 3d render or illustration. Finally, the result is compared with the real photograph of the person, to see if the process followed was correct or not.
Source: ciceromoraes.com.br/blog/?p=1247 Spectacular work by Cícero Moraes.
Source: ciceromoraes.com.br/blog/?p=1247 Spectacular work by Cícero Moraes.

It's not trivial, but a model trained on enough such examples, together perhaps with current diffusion models, could, hypothetically, do a very decent job of face reconstruction.
I don't think it's far away the day we see something like this.
I don't think it's far away the day we see something like this.
And hey, I don't see anyone's work threatened: even with a great leap in automation and time savings, human supervision, touch-ups, adjustments, etc. will still be needed.
Well, let's go!
Now what I promised you: paint and color with @javilop!
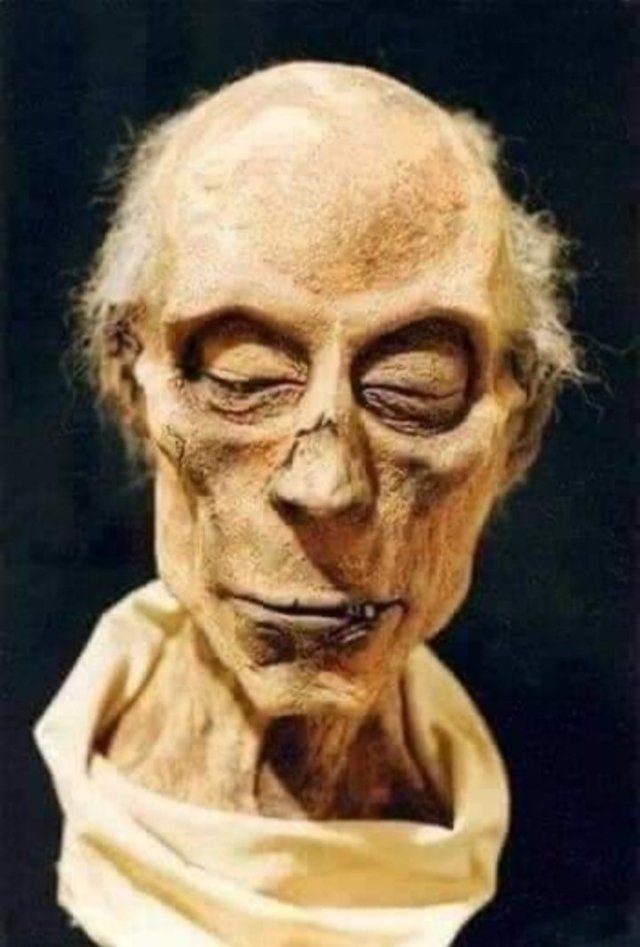
Let's rebuild NON-FORENSICALLY reliable mummies!
Now what I promised you: paint and color with @javilop!
Let's rebuild NON-FORENSICALLY reliable mummies!

The tool I used is midjourney.com. Interestingly, it is used from their Discord channel and/or by talking directly to their bot (if you upgrade to one of their paid plans).
For these "reconstructions" it is necessary to use an init image (the mummy). In this other thread I already explained how this could be done.
https://twitter.com/javilopen/status/1613107083959738369
Let's go!
🔥🔥🔥 In "ALT" you have all the prompts 🔥🔥🔥
You will see that they all follow the same scheme.
1️⃣. Ramses II
🔥🔥🔥 In "ALT" you have all the prompts 🔥🔥🔥
You will see that they all follow the same scheme.
1️⃣. Ramses II

Younger! Just change the age in the prompt, et voila!
![[url] AI-generated portrait...](https://pbs.twimg.com/media/FmhnRLAaAAEe6hA.jpg)
2️⃣. The surfer guanche.
You were looking forward to it, I know.
You were looking forward to it, I know.

![[url] AI-generated portrait...](https://pbs.twimg.com/media/FmhnTKXagAAMN8Z.jpg)
By the way, in the professional reconstructions it seems that he actually had brown hair... although in the English Wikipedia they say: "including brown red hair"... so who knows.

3️⃣. Tollund Man.
Or at least, his head.
Or at least, his head.

![[url] AI-generated portrait...](https://pbs.twimg.com/media/FmhnVk9acAAJtOk.jpg)
4️⃣ Lady Rai.

![[url] AI-generated portrait...](https://pbs.twimg.com/media/FmhnW8KagAAoRb3.png)
5️⃣. Menmaatre Seti I.

![[url] AI-generated portrait...](https://pbs.twimg.com/media/FmhnYapaEAEmkTH.jpg)
Tip: You can refine the image by using the image generated in the previous step as the input image. The prompt is the same, but in successive iterations it can acquire new nuances:

Utilicé la misma técnica para la segunda imagen de Lady Rai. Mi favorita de todo el hilo.

Thanks for reading!
Can't wait to see your mummies come to life! Show them to me!
And if you want more curious things, sometimes reliable, sometimes not, sign up to my newsletter. An easy RT to the 1st tweet of the thread would also motivate me 🙏 Thx!
javilopen.substack.com
Can't wait to see your mummies come to life! Show them to me!
And if you want more curious things, sometimes reliable, sometimes not, sign up to my newsletter. An easy RT to the 1st tweet of the thread would also motivate me 🙏 Thx!
javilopen.substack.com
• • •
Missing some Tweet in this thread? You can try to
force a refresh