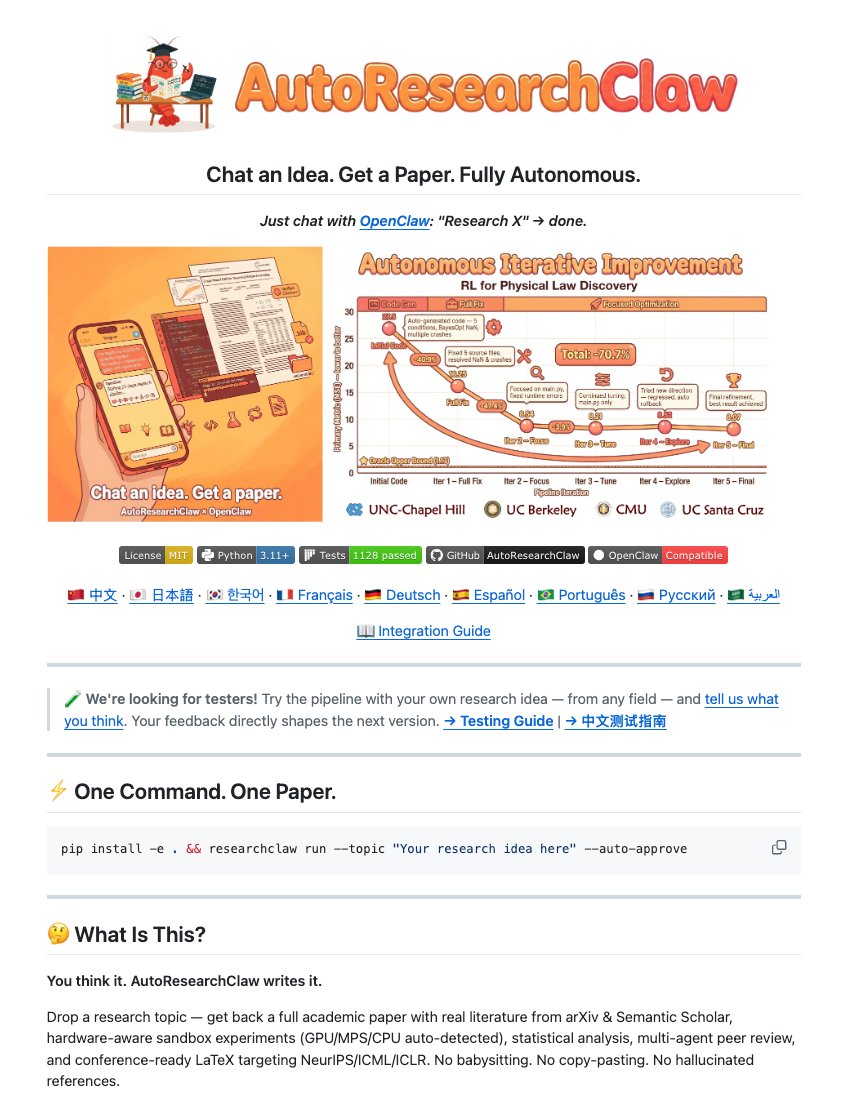
The "#ChatGPT for Search Engines" extension has been updated to V1.5.5 with a ton of new features! 🤗
🔗 chrome.google.com/webstore/detai…
See what's in the box in the thread below 🧵👇
🔗 chrome.google.com/webstore/detai…
See what's in the box in the thread below 🧵👇
https://twitter.com/DataChaz/status/1608188069433196548
New feat #01. Code Syntax highlighting 👇 

New feat #02.
New Trigger Settings (`Always`, `Manually` or `Question`)
New Trigger Settings (`Always`, `Manually` or `Question`)

New feat #03.
New Dark Theme!
New Dark Theme!


New feat #05.
Auto-clear conversations: This function is to avoid overloading #ChatGPT's system, saving more resources!
Auto-clear conversations: This function is to avoid overloading #ChatGPT's system, saving more resources!


A big thanks to the Devs at @chatgptforseach for these enhancements! 🔥
You can download the new `#ChatGPT for Search Engines` extension here:
🔗 chrome.google.com/webstore/detai…
You can download the new `#ChatGPT for Search Engines` extension here:
🔗 chrome.google.com/webstore/detai…
• • •
Missing some Tweet in this thread? You can try to
force a refresh