
Did some "testing" with the #ChatGPT (or #GPT3) detector by Hello-SimpleAI.
1. It's much more accurate than the GPT2 detector. All zero-shot prompt texts were detected. (but to be honest, anybody that works with ChatGPT on a daily basis can detect a ChatGPT text in 2 seconds)
1. It's much more accurate than the GPT2 detector. All zero-shot prompt texts were detected. (but to be honest, anybody that works with ChatGPT on a daily basis can detect a ChatGPT text in 2 seconds)
https://twitter.com/_akhaliq/status/1615965922841300992
2. Long-prompt generations (especially from GPT3 playground) and summaries: not so much. About 8 out of 10 texts were not detected.
3. Reworked text or "text combinations" (several layers of AI interactions): zero detection
4. Translations in German: almost zero detection
3. Reworked text or "text combinations" (several layers of AI interactions): zero detection
4. Translations in German: almost zero detection
Tl;dr: Helpful tool for ChatGPT detection. But the bigger question is: should text (content) that is improved / re-written / corrected / translated / transformed by a #LLM be detectable? And if so, why don't we label highly altered or enhanced pictures, videos or audio?
Little addition:
Text from explainlikeimfive.io
English text is 99,99% detected with ChatGPT Single-Page and Linguistic Version.
German text is only detected with Single-Page version but not with the Linguistic.
Answers generated with @perplexity_ai were 50/50%
Text from explainlikeimfive.io
English text is 99,99% detected with ChatGPT Single-Page and Linguistic Version.
German text is only detected with Single-Page version but not with the Linguistic.
Answers generated with @perplexity_ai were 50/50%

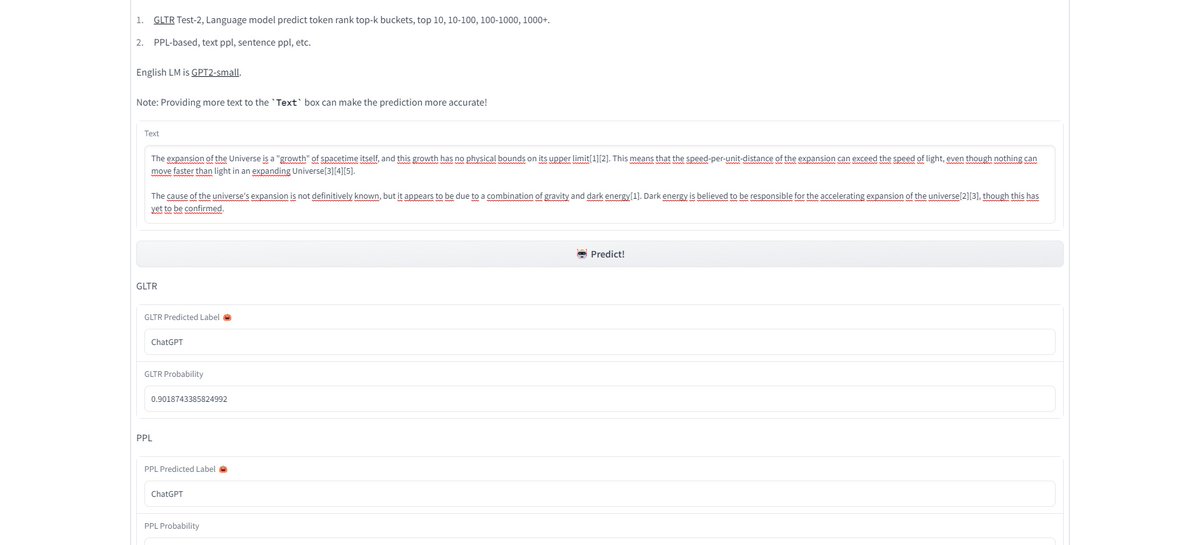
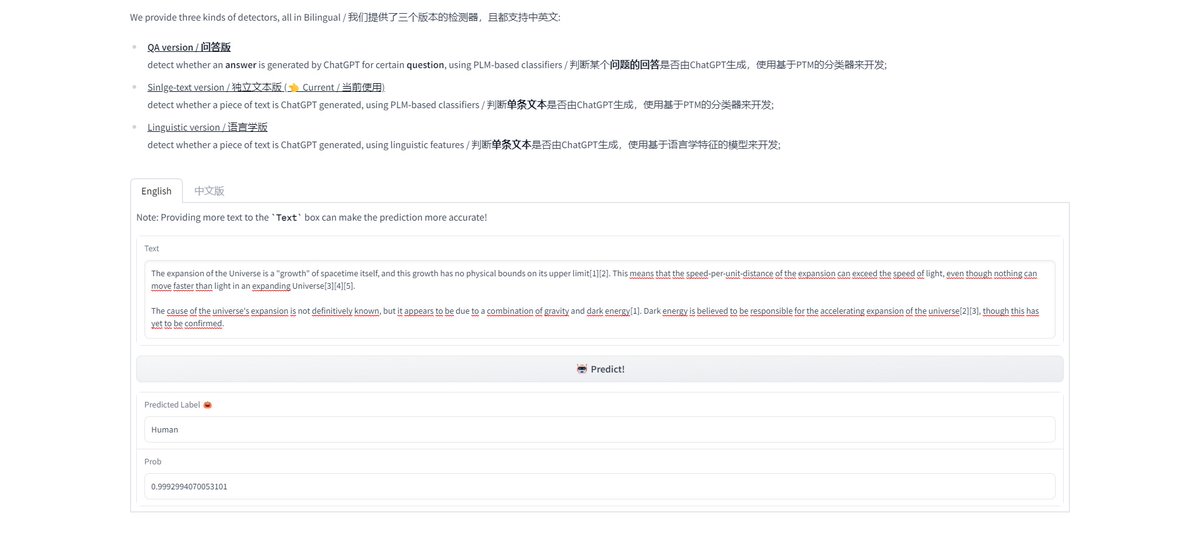
Adding 2 or more spelling errors changed a 99% detection to 99% human. Overall, the most important factor seems to be sentence structure and repetition.
And as the demo states: the longer the text, the better the detection. A 2-3 paragraph summary = zero det; 6 paras = 99% det.
And as the demo states: the longer the text, the better the detection. A 2-3 paragraph summary = zero det; 6 paras = 99% det.
• • •
Missing some Tweet in this thread? You can try to
force a refresh



