Do you want to do a psychology experiment while following best practices in open science? My collaborators and I have created Experimentology, a new open web textbook (to be published by MIT Press but free online forever).
experimentology.io
Some highlights! 🧵
experimentology.io
Some highlights! 🧵

The book is intended for advanced undergrads or grad students, and is designed around the flow of experimental project - from planning through design, execution, and reporting, with open science concepts like reproducibility, data sharing, and preregistration woven throughout.

We start by thinking through what an experiment is, highlighting the role of randomization in making causal claims and introduce DAGs (causal graphs) as a tool for thinking about these. We then discuss how experiments relate to psychological theories.
experimentology.io/1-experiments
experimentology.io/1-experiments


We introduce issues of reproducibility, replicability, and robustness and review the meta-science literature on each of these. We also give a treatment of ethical frameworks for human subjects research and the ethical imperative for open science.
experimentology.io/3-replication
experimentology.io/3-replication
In our chapters on statistics, we introduce estimation and inference and both Bayesian and frequentist approaches. Our emphasis is on model-building and data description, rather than on dichotomous p<.05 inference.
experimentology.io/7-models
experimentology.io/7-models

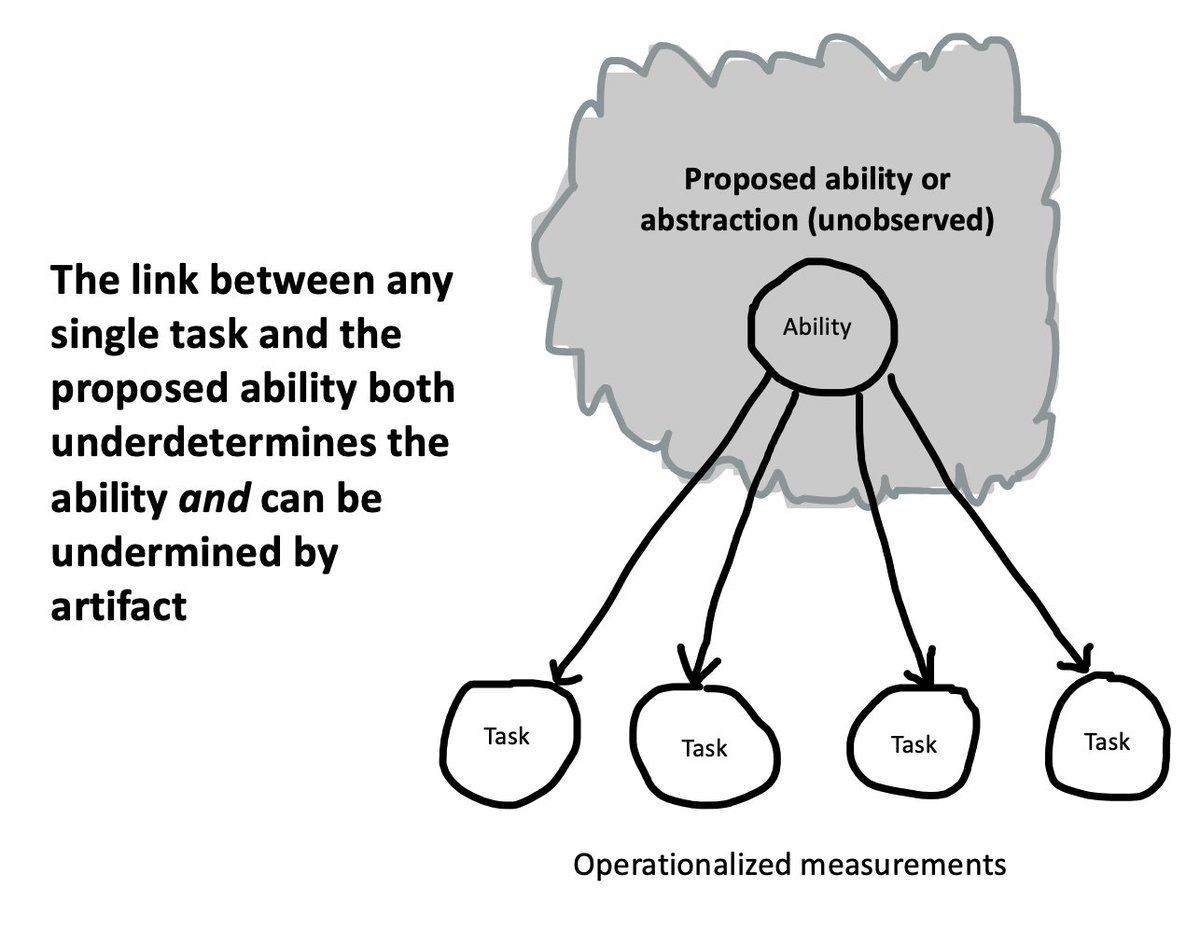
Next, we move to the meat of the book, with chapters on measurement, design, and sampling. I'm very proud of these chapters because I don't know of any similar treatment of these topics, and they are critical for experimentalists!
experimentology.io/8-measurement
experimentology.io/8-measurement



How do you organize your files for sharing? Should you include manipulation checks? What are best practices for piloting? The next section of the book has chapters on preregistration, data collection, and project management.
experimentology.io/11-prereg
experimentology.io/11-prereg

The final section contains chapters on presenting and interpreting research, including writing, visualization, and meta-analysis.
experimentology.io/14-writing
experimentology.io/14-writing

Throughout, the book features case studies, "accident reports" (issues in the published literature), code boxes for learning how to reproduce our examples, and boxes highlighting ethical issues that come up during research.
We also have four "tools" appendices, including introductions to RMarkdown, github, the tidyverse, and ggplot.
experimentology.io/A-git
experimentology.io/A-git
Use Experimentology in your methods course! We include a guide for instructors with sample schedules and projects, and we'd love to get your feedback on how the material works in both undergrad and grad courses.
experimentology.io/E-instructors
experimentology.io/E-instructors
Experimentology is still work in progress, and we're releasing it in part to gather feedback on errors, omissions, and ways that we can improve the presentation of complex topics. Please don't hesistate to reach out or to log issues on our issue tracker:
github.com/langcog/experi…
github.com/langcog/experi…
My wonderful co-authors are @mbraginsky, @JulieCachia, @coles_nicholas_, @Tom_Hardwicke, @hawkrobe, Maya Mathur, and Rondeline Williams!
• • •
Missing some Tweet in this thread? You can try to
force a refresh