
Cognitive scientist at Stanford. Open science advocate. @stanfordsymsys director. Bluegrass picker, slow runner, dad.
 Part of a weekly Experimentology series running through the spring and summer, one chapter at a time. Today is Ch 6, on inference — with Maya Mathur as cowriter.
Part of a weekly Experimentology series running through the spring and summer, one chapter at a time. Today is Ch 6, on inference — with Maya Mathur as cowriter.
 A scientific model represents part or a whole of a particular system of interest, allowing researchers to explore, probe, and explain specific behaviors of the system. plato.stanford.edu/entries/models…
A scientific model represents part or a whole of a particular system of interest, allowing researchers to explore, probe, and explain specific behaviors of the system. plato.stanford.edu/entries/models…

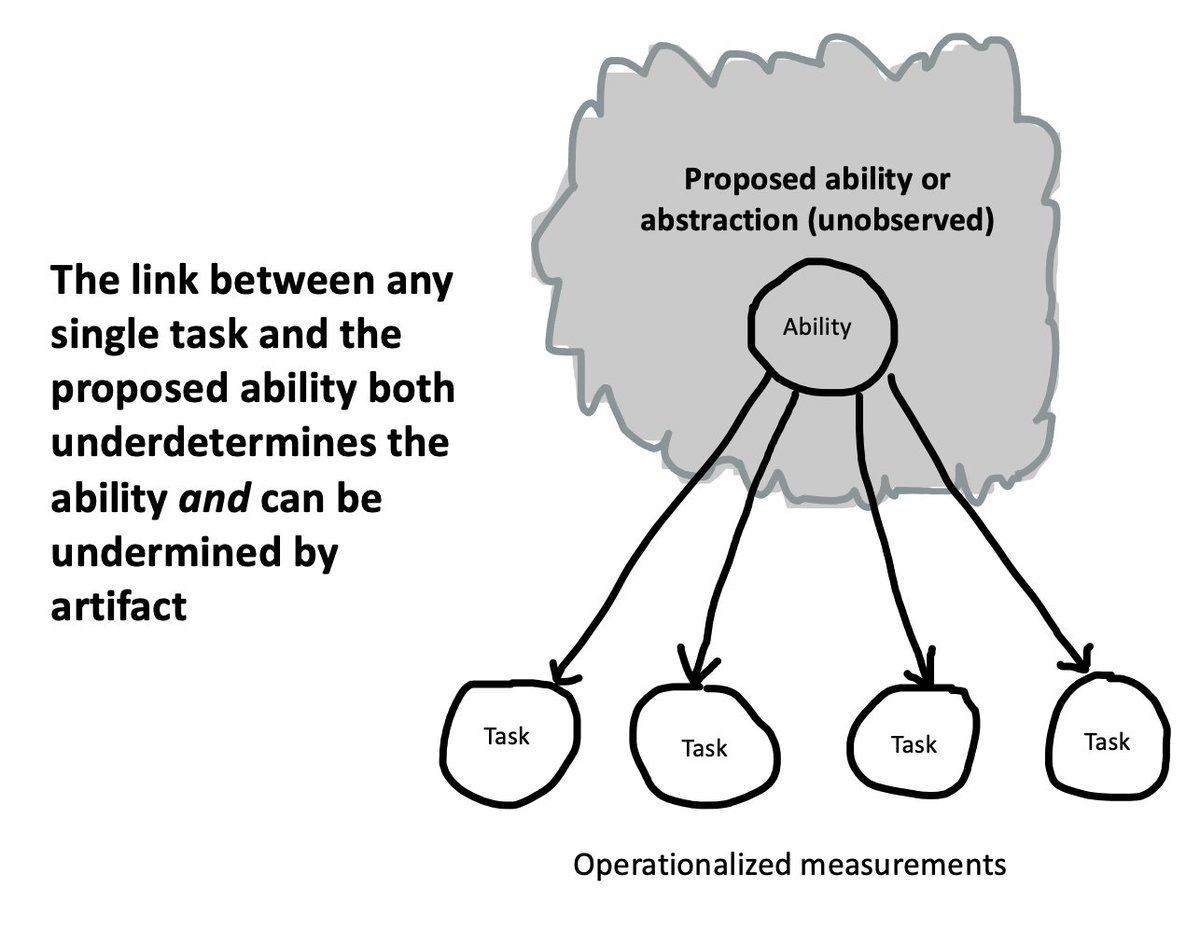 This thread builds on my previous thread about general principles for LLM evaluation. Here I want to talk specifically about claims about the presence of a particular ability (or relatedly, an underlying representation or abstraction).
This thread builds on my previous thread about general principles for LLM evaluation. Here I want to talk specifically about claims about the presence of a particular ability (or relatedly, an underlying representation or abstraction).
 Just to be clear, in this thread I'm not saying that LLMs do or don't have *any* cognitive capacity. I'm trying to discuss a few basic ground rules for *claims* about whether they do.
Just to be clear, in this thread I'm not saying that LLMs do or don't have *any* cognitive capacity. I'm trying to discuss a few basic ground rules for *claims* about whether they do.

 Recent progress in AI is truly astonishing, though somewhat hard to interpret. I don't want to reiterate recent discussion, but @spiantado has a good take in the first part of lingbuzz.net/lingbuzz/007180; l like this thoughtful piece by @MelMitchell1 as well: pnas.org/doi/10.1073/pn…
Recent progress in AI is truly astonishing, though somewhat hard to interpret. I don't want to reiterate recent discussion, but @spiantado has a good take in the first part of lingbuzz.net/lingbuzz/007180; l like this thoughtful piece by @MelMitchell1 as well: pnas.org/doi/10.1073/pn…
 The book is intended for advanced undergrads or grad students, and is designed around the flow of experimental project - from planning through design, execution, and reporting, with open science concepts like reproducibility, data sharing, and preregistration woven throughout.
The book is intended for advanced undergrads or grad students, and is designed around the flow of experimental project - from planning through design, execution, and reporting, with open science concepts like reproducibility, data sharing, and preregistration woven throughout. 



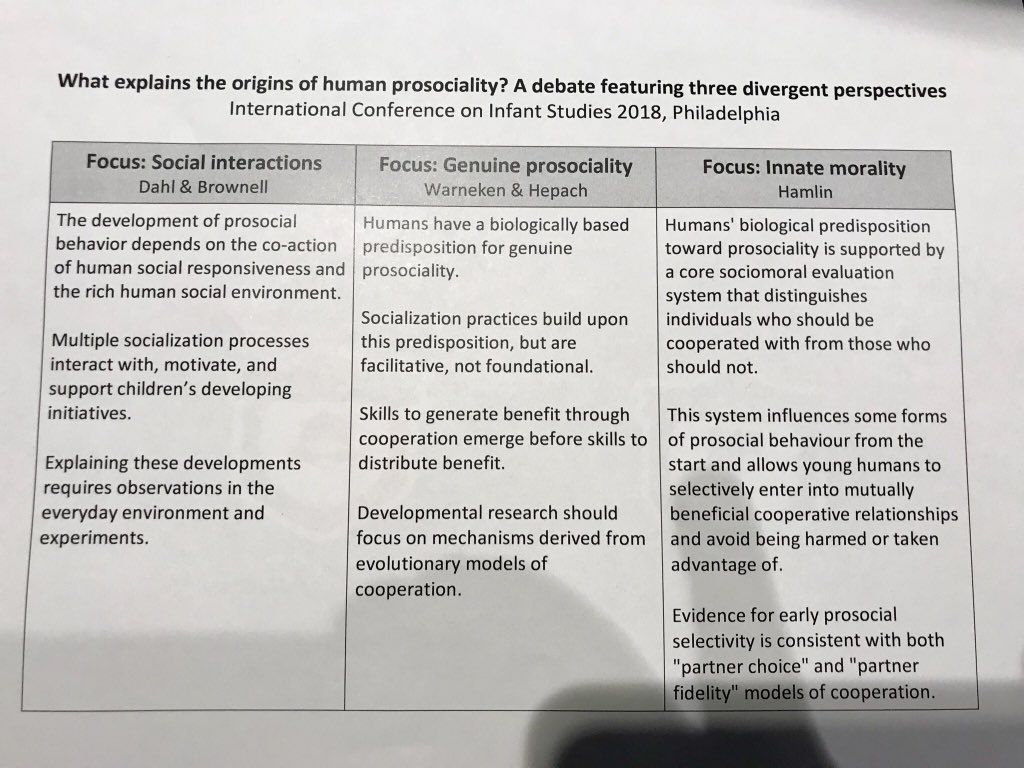 Dahl up first. Puzzles of prosociality: there’s an amazing ability to help others prosocially from an early age, but some infants don’t! Why? Behaviors emerge via 1) social interest and 2) socialization.
Dahl up first. Puzzles of prosociality: there’s an amazing ability to help others prosocially from an early age, but some infants don’t! Why? Behaviors emerge via 1) social interest and 2) socialization.