BLOOM.
A large language model trained by researchers from around the world by @BigscienceW.
How did they do it?
Why did they do it?
Let's dive in.
1/21
🧵
A large language model trained by researchers from around the world by @BigscienceW.
How did they do it?
Why did they do it?
Let's dive in.
1/21
🧵

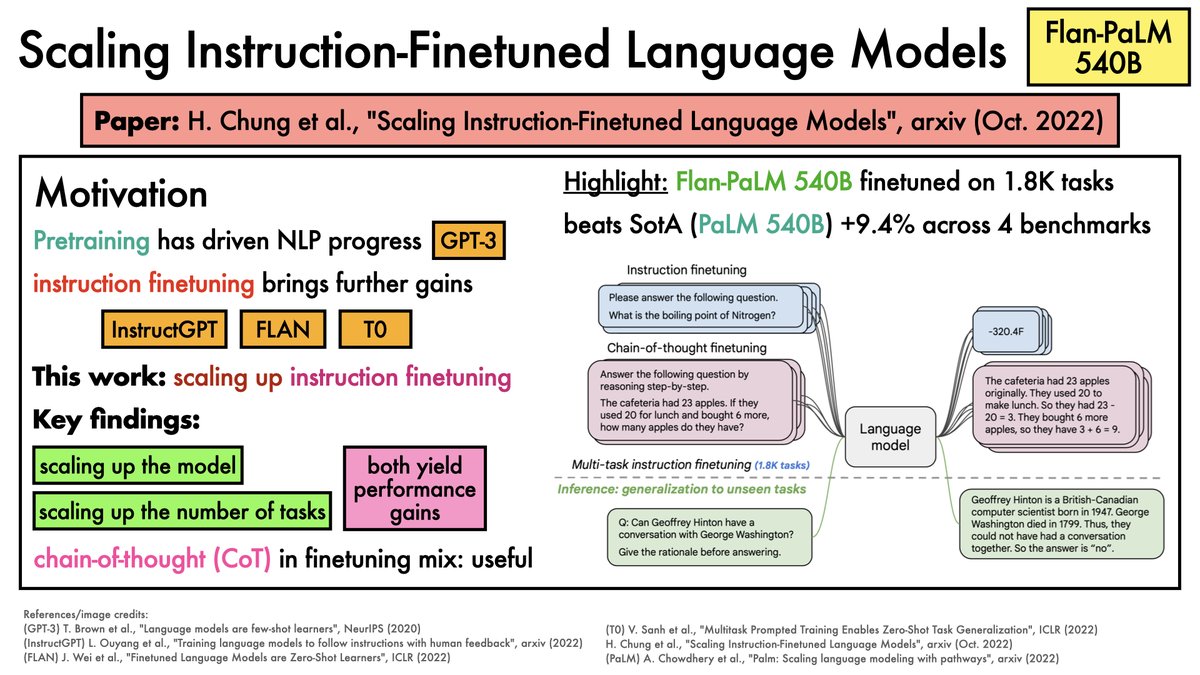
Large Languages Models (LLMs) now play a key role in NLP.
But few orgs can afford to train them.
Also:
- most LLMs focus on English
- many are not public
Goals for BLOOM
- release a strong multilingual LLM
- document the development process
2/21
But few orgs can afford to train them.
Also:
- most LLMs focus on English
- many are not public
Goals for BLOOM
- release a strong multilingual LLM
- document the development process
2/21

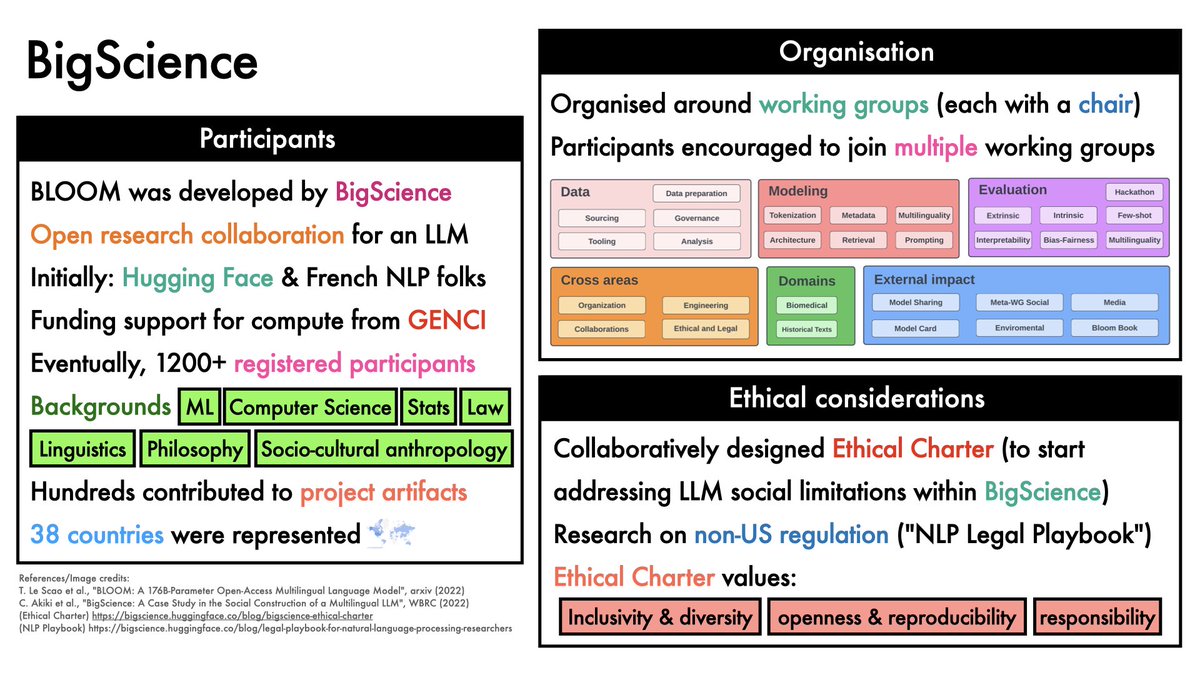
BLOOM was a BigScience effort:
- 28 countries
- 1200+ registered participants
3/21
- 28 countries
- 1200+ registered participants
3/21
Training data is key.
For BLOOM, the goals were to prioritise:
- human involvement
- local expertise
- language expertise
4/21
For BLOOM, the goals were to prioritise:
- human involvement
- local expertise
- language expertise
4/21

Also important: data governance.
Efforts were made to:
- obtain permission for data where possible
- keep data sources separate until final preprocessing
- provide tools to inspect/visualise data
- share data where possible
5/21
Efforts were made to:
- obtain permission for data where possible
- keep data sources separate until final preprocessing
- provide tools to inspect/visualise data
- share data where possible
5/21

BLOOM was ultimately trained on ROOTS.
ROOTS = "Responsible Open-Science Open-Collaboration Text Sources":
- 1.61 TB
- 46 natural languages
- 13 coding languages
Careful studies were conducted to select the architecture, objective and model.
6/21
ROOTS = "Responsible Open-Science Open-Collaboration Text Sources":
- 1.61 TB
- 46 natural languages
- 13 coding languages
Careful studies were conducted to select the architecture, objective and model.
6/21

Ultimately, the project settled on a decoder-only architecture.
7/21
7/21

Training used the @genci_fr Jean Zay cluster:
- 3.5 months
- 384 (80GB) A100s
- > 1 million GPU hours
8/21
- 3.5 months
- 384 (80GB) A100s
- > 1 million GPU hours
8/21

The Megatron-DeepSpeed framework was used for efficiency.
This provides:
- data parallelism (replicate model across GPUs)
- tensor parallelism (split within individual layers across GPUs)
- pipeline parallelism (split different layers across GPUs)
9/21
This provides:
- data parallelism (replicate model across GPUs)
- tensor parallelism (split within individual layers across GPUs)
- pipeline parallelism (split different layers across GPUs)
9/21

Other fun engineering details that proved useful:
- mixed-precision training
- CUDA kernel fusion
- disabling async CUDA kernel launches (avoid deadlocks)
- splitting parameter groups (to avoid excessive CPU mem allocation)
10/21
- mixed-precision training
- CUDA kernel fusion
- disabling async CUDA kernel launches (avoid deadlocks)
- splitting parameter groups (to avoid excessive CPU mem allocation)
10/21

Carbon footprint is fairly difficult to estimate reliably (it's a complex business).
With this caveat, BLOOM CO2eq emissions were lower than other models of similar sizes.
In part, this is due to French nuclear electricity generation (with relatively low emissions).
11/21
With this caveat, BLOOM CO2eq emissions were lower than other models of similar sizes.
In part, this is due to French nuclear electricity generation (with relatively low emissions).
11/21

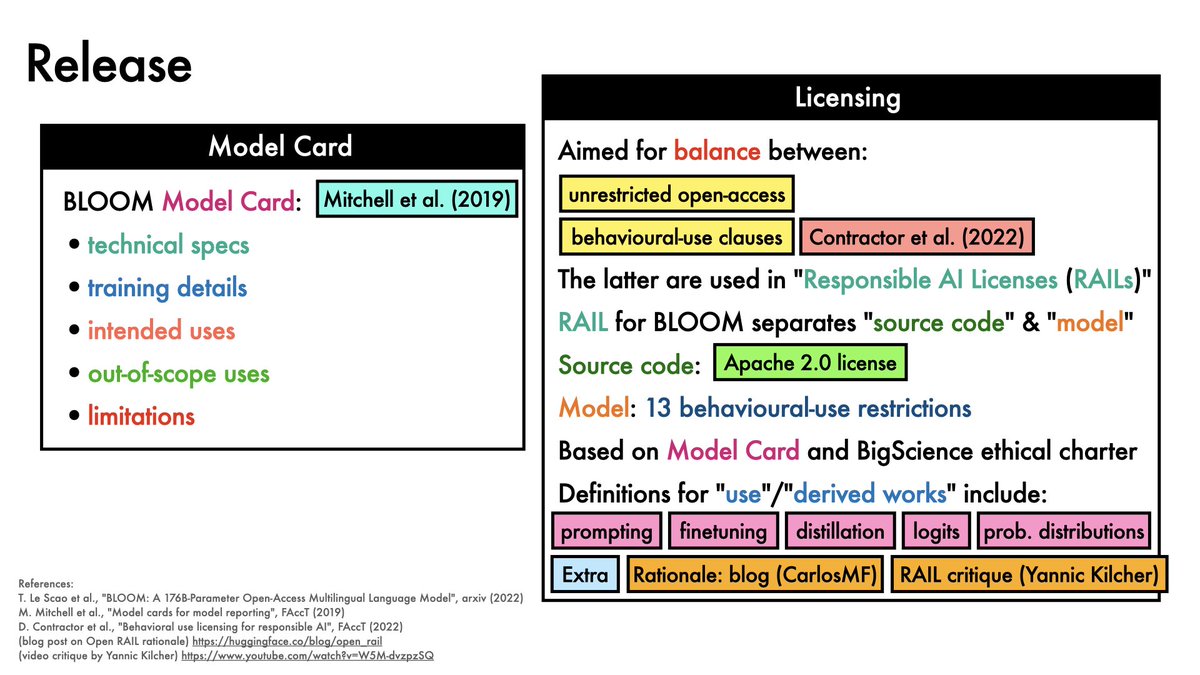
BLOOM is released under a Responsible AI License (RAIL).
This has 13 behavioural-use restrictions related to LLM use cases.
12/21
This has 13 behavioural-use restrictions related to LLM use cases.
12/21
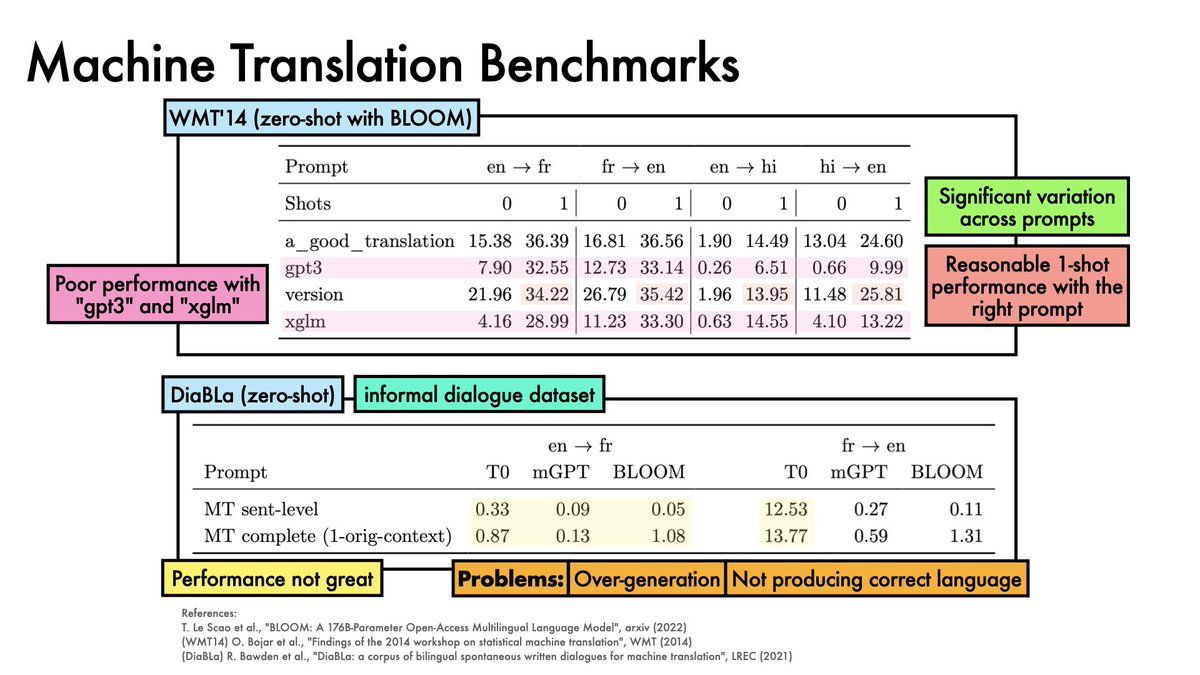
On WMT14, 1-shot BLOOM does a reasonable job with the right prompt
On DiaBla (an informal dialogue dataset), BLOOM (and other models) struggle
13/21
On DiaBla (an informal dialogue dataset), BLOOM (and other models) struggle
13/21
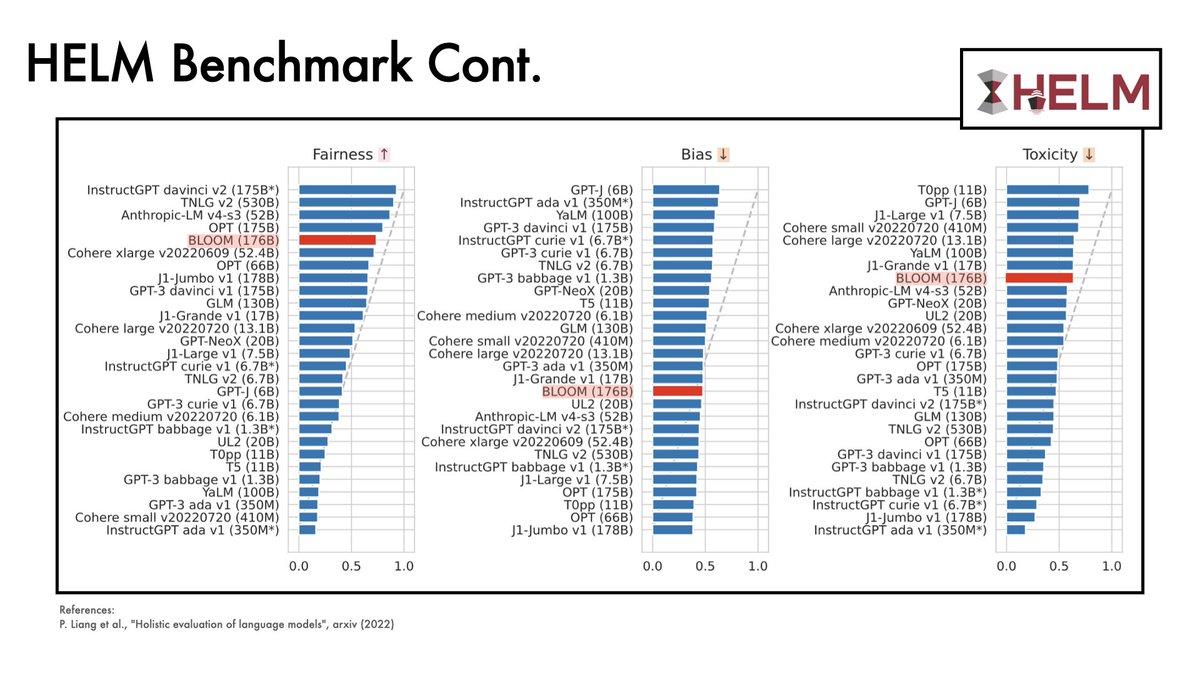
On @StanfordHAI's HELM benchmark, BLOOM:
- lags somewhat behind the top closed-source models on accuracy
- is poor on calibration error
- but quite good on robustness
14/21
- lags somewhat behind the top closed-source models on accuracy
- is poor on calibration error
- but quite good on robustness
14/21

BLOOM also does:
- relatively well on fairness
- somewhat moderately on bias
- poorly on toxicity metrics
15/21
- relatively well on fairness
- somewhat moderately on bias
- poorly on toxicity metrics
15/21
Similarly to other LLMs, BLOOM benefits considerably from multilingual multitask finetuning.
16/21
16/21

BLOOM can generate code.
But it lags behind models like Codex on the HumanEval benchmark.
17/21
But it lags behind models like Codex on the HumanEval benchmark.
17/21

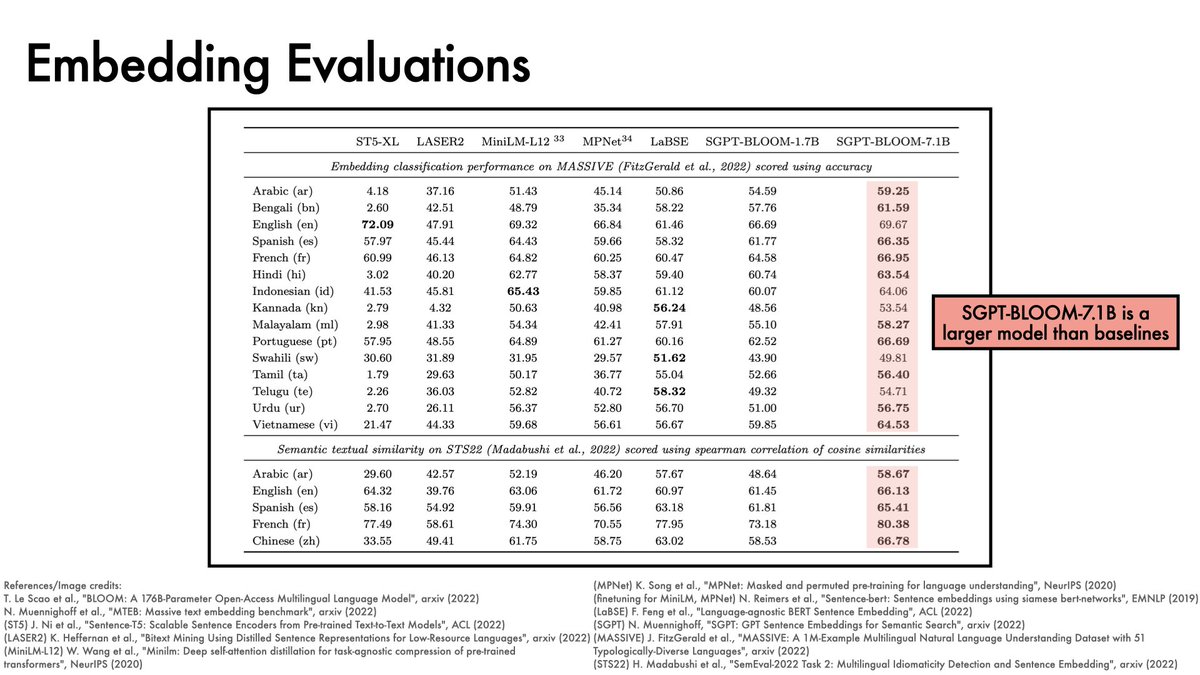
BLOOM can also produce solid embeddings for retrieval.
18/21
18/21
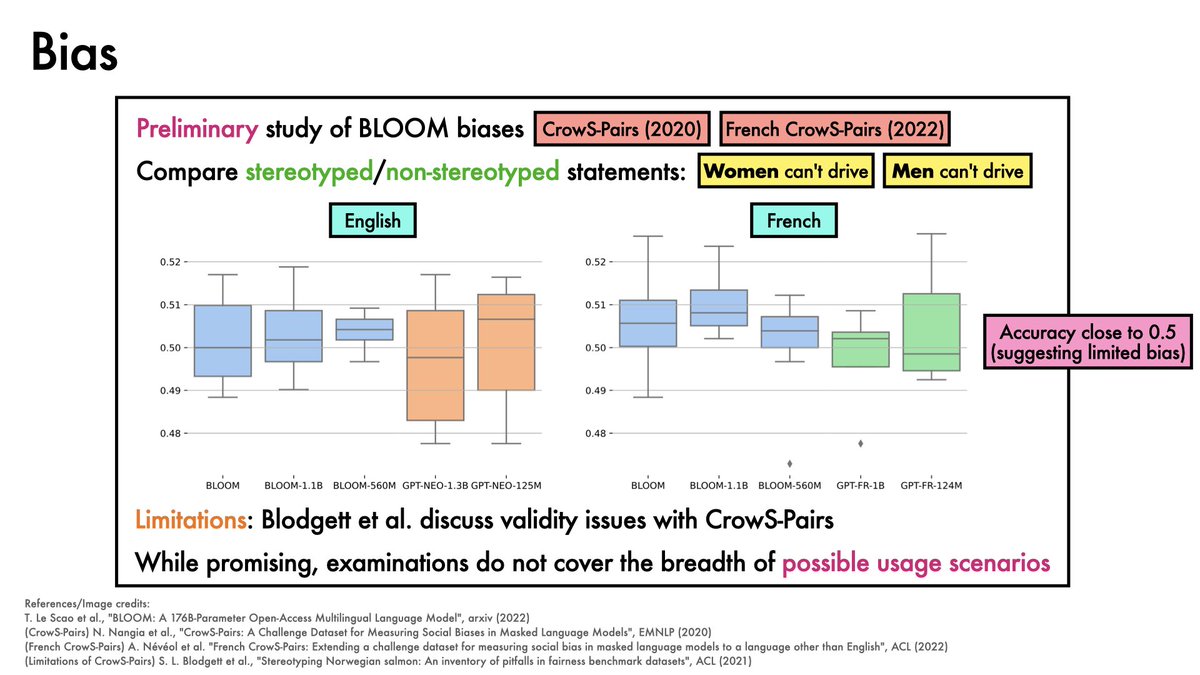
A preliminary study of BLOOM suggests limited bias.
Caveats apply.
19/21
Caveats apply.
19/21
For those who enjoy videos:
20/21
20/21
Links:
- slides: samuelalbanie.com/files/digest-s…
- references: samuelalbanie.com/digests/2023-0…
- arxiv: arxiv.org/abs/2211.05100
- code and models: huggingface.co/bigscience/blo…
21/21
- slides: samuelalbanie.com/files/digest-s…
- references: samuelalbanie.com/digests/2023-0…
- arxiv: arxiv.org/abs/2211.05100
- code and models: huggingface.co/bigscience/blo…
21/21
• • •
Missing some Tweet in this thread? You can try to
force a refresh