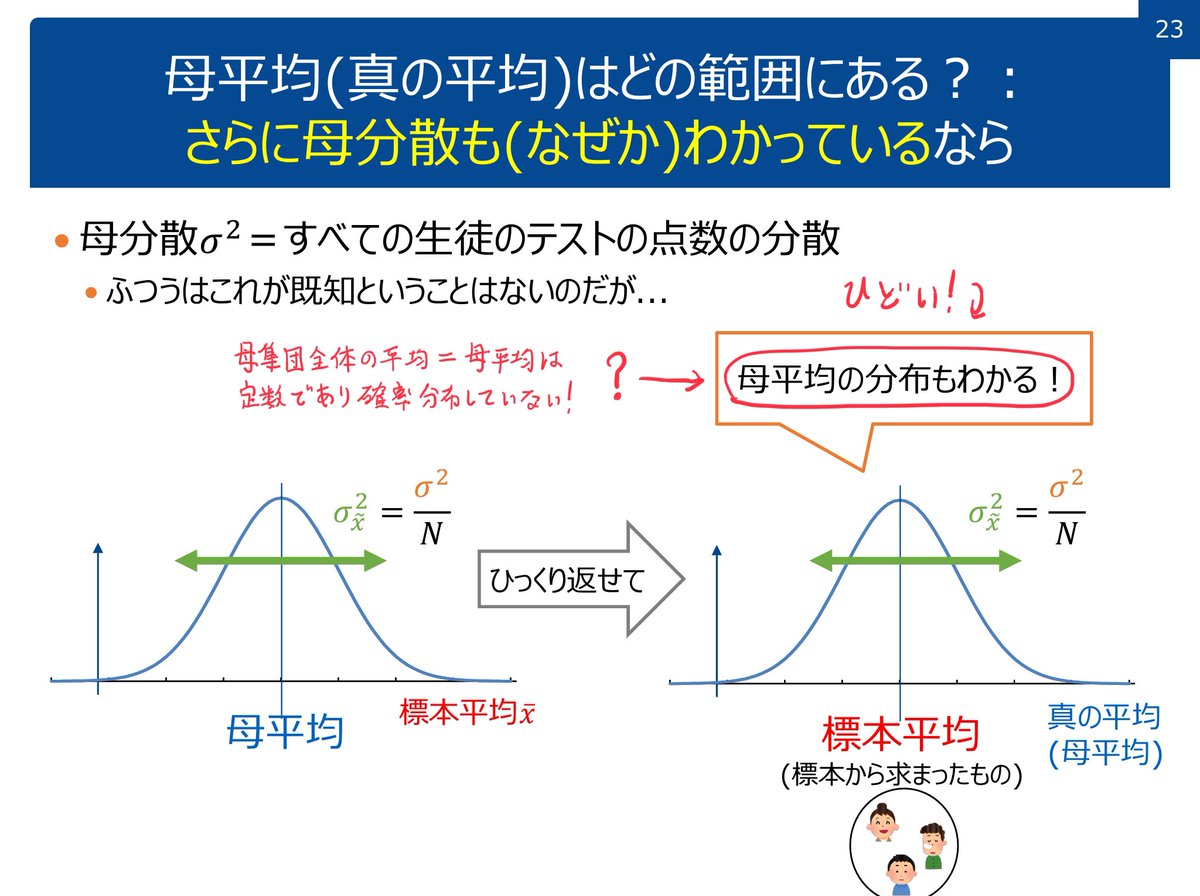
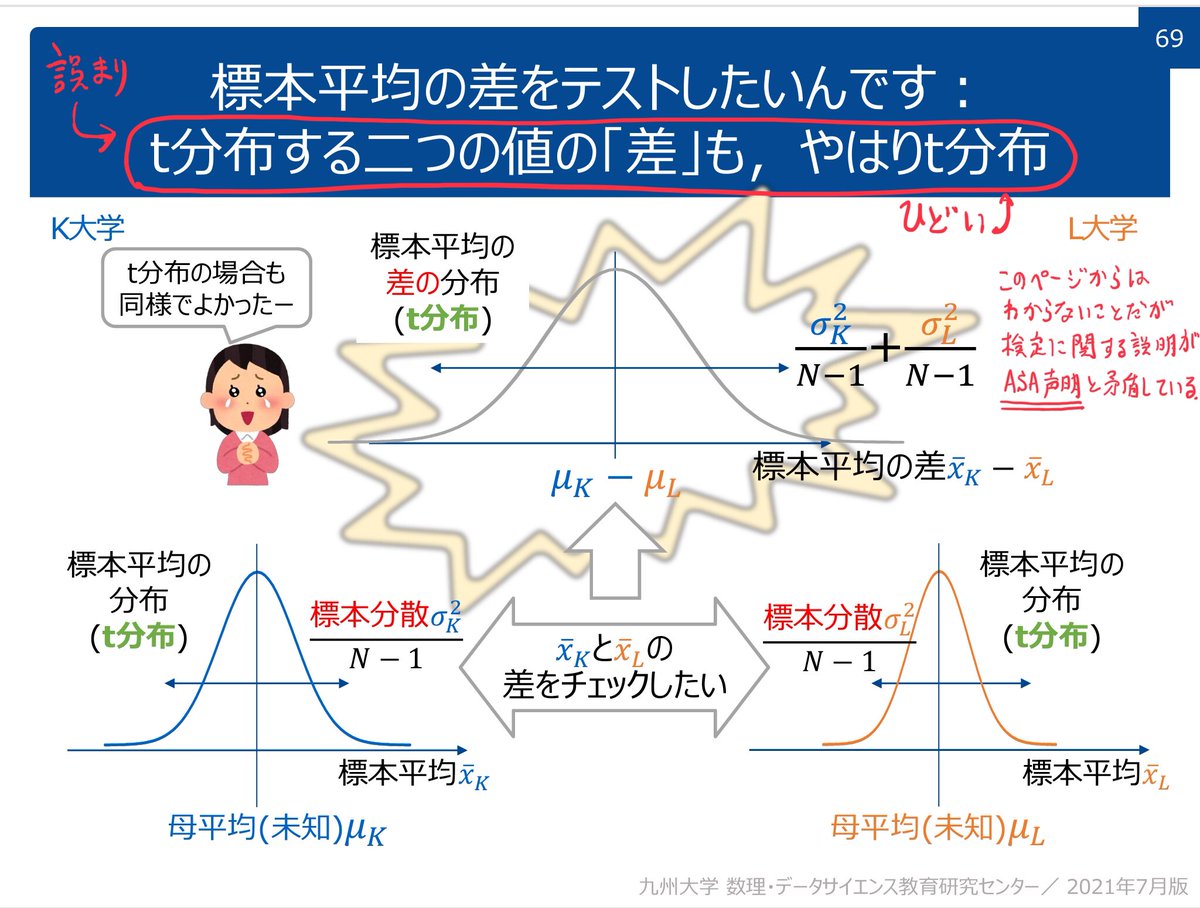
#統計 統計分析の背後には常にモデルがあり、統計的因果推論の場合には特に
* モデルを変えるべきときには変えなければいけない。
* 変更後のモデルに関する結果が変更前のモデルに関する結果から得られる場合がある。
が基本的。たぶん、パールさん達の方針は概念的にこのように要約される。続く
* モデルを変えるべきときには変えなければいけない。
* 変更後のモデルに関する結果が変更前のモデルに関する結果から得られる場合がある。
が基本的。たぶん、パールさん達の方針は概念的にこのように要約される。続く
https://twitter.com/genkuroki/status/1618002371585671174
#統計 例えば、変数XとYの関係を調べたいとき、Xが他の変数Zに影響されて決まる状況(例えば観察研究)と、ZのXへの影響を断ち切ってXのZと無関係に決まるようにした状況(例えばランダム化{比較,対照}試験)では、別の統計モデルを使う必要があります。
続く
続く
#統計 現象の背後にある法則は同一であっても、データの取得の仕方が異なれば、データの生成の仕方を記述する統計モデルも別のものにする必要がある。
こういうことはわざわざ言われなくても、当たり前だと言えないようでは、科学的な会話自体が不可能になるだろう。
続く
こういうことはわざわざ言われなくても、当たり前だと言えないようでは、科学的な会話自体が不可能になるだろう。
続く
#統計 もしも観察研究で得たデータだけを使って、「もしもランダム化対照試験をやっていたらどうなっていたか」に関する結果が得られればうれしいだろう。
一般には後者については部分的結果しか得られないだろうがそれでもうれしい。
続く
一般には後者については部分的結果しか得られないだろうがそれでもうれしい。
続く
#統計 そのためには、
観察研究で得たデータ
↓
↓通常の統計学
↓
観察研究の統計モデルに関する結果
↓
↓統計的因果推論の仕組み
↓
「もしもランダム化対照試験をやったなら」に対応する統計モデルに関する結果
を可能にすればよい。ただしモデルの妥当性はいつものように別に考える必要がある。
観察研究で得たデータ
↓
↓通常の統計学
↓
観察研究の統計モデルに関する結果
↓
↓統計的因果推論の仕組み
↓
「もしもランダム化対照試験をやったなら」に対応する統計モデルに関する結果
を可能にすればよい。ただしモデルの妥当性はいつものように別に考える必要がある。
#統計 実際には「ランダム化対照試験」のようなリアルな話を考えなくても、因果関係の情報を含むモデルMから、Xへの他の変数からの因果的影響を断ち切ってできるモデルM_Xを作り、Mに関する結果からM_Xに関する部分的結果を導く、というスタイルで統計的因果推論の仕組みを定式化できる。続く
#統計 注意:以上においてDAGやらバックドア基準やらの、パールさん的な統計的因果推論の解説で最初に出されてしまいがちな用語を一切使っていないことに注意!
そういう特殊な用語はテクニカルな話をするときには重要だが、統計的因果推論の仕組みの概念的説明では積極的に不要だと思います。
そういう特殊な用語はテクニカルな話をするときには重要だが、統計的因果推論の仕組みの概念的説明では積極的に不要だと思います。
#統計 DAGは易しい場合のモデルMとM_Xの記述に用いられ、バックドア基準はM_Xにおける条件付き確率分布がMにおいて対応する条件付き確率分布にいつ一致するかを考えれば得られます。
概念的枠組みと比較するとテクニカルな話題だとみなされます。(もちろんテクニカルにうまく行くので非常に大事)
概念的枠組みと比較するとテクニカルな話題だとみなされます。(もちろんテクニカルにうまく行くので非常に大事)
#統計 結構売れたように見えるJ.パール『因果推論の科学』を読んだ人の中には、
数学的にテクニカルな部分を理解できない
がゆえに
内容の本質的な部分を理解できなかった
が、
ルービンさん達を強くディスっている点は強く印象に残った
と思っている人達が多いと思う。😅😅😅😅😅
数学的にテクニカルな部分を理解できない
がゆえに
内容の本質的な部分を理解できなかった
が、
ルービンさん達を強くディスっている点は強く印象に残った
と思っている人達が多いと思う。😅😅😅😅😅
#統計 このディスり問題はかなり深刻に見える。
実際にはパールさん達の側がルービンさん達に不適切な感じでひどくディスられて来ており、パールさんはその点については怒って良い立場だと現在の私は思っています。
とにかく、その辺は色々ひどくこじれてしまっている。続く
実際にはパールさん達の側がルービンさん達に不適切な感じでひどくディスられて来ており、パールさんはその点については怒って良い立場だと現在の私は思っています。
とにかく、その辺は色々ひどくこじれてしまっている。続く
#統計 「うわっ!こんなにこじれているのか!」と思ったのは、「ゲルマンはルービンの元弟子なので、この件についてはフェアでバランスのとれた評価はできない」という極めて失礼な匿名発言までされている場面を見たときです。
quora.com/Why-is-there-a… の6を参照。
滅茶苦茶怖い。😱
quora.com/Why-is-there-a… の6を参照。
滅茶苦茶怖い。😱
#統計 しかし、その失礼発言を否定している別の匿名の人による次の指摘は正しいように思えました。
「ゲルマンさんは、よく理解されている問題について、パールの方法を検証し、ルービンの方法と比較することを拒否している」
これの最初の方
↓
quora.com/Why-is-there-a…
続く
「ゲルマンさんは、よく理解されている問題について、パールの方法を検証し、ルービンの方法と比較することを拒否している」
これの最初の方
↓
quora.com/Why-is-there-a…
続く
#統計 ゲルマンさんとパールさん達の2009年のやりとりは以下で読める。
2009-07-05
statmodeling.stat.columbia.edu/2009/07/05/dis…
2009-07-08
causality.cs.ucla.edu/blog/index.php…
2009-07-09
statmodeling.stat.columbia.edu/2009/07/09/mor…
2009-07-05
statmodeling.stat.columbia.edu/2009/07/05/dis…
2009-07-08
causality.cs.ucla.edu/blog/index.php…
2009-07-09
statmodeling.stat.columbia.edu/2009/07/09/mor…
#統計
2009-07-05 statmodeling.stat.columbia.edu/2009/07/05/dis… でのゲルマンさんの第一声は「私はパールの表記法を理解できませんでした」😅なので、パールvs.ルービンの話題に適切なコメントはちょっと期待できない感じ。
それから13年半後の現在でも「パールの表記法」を理解できていない専門家はいるのでしょうか?
2009-07-05 statmodeling.stat.columbia.edu/2009/07/05/dis… でのゲルマンさんの第一声は「私はパールの表記法を理解できませんでした」😅なので、パールvs.ルービンの話題に適切なコメントはちょっと期待できない感じ。
それから13年半後の現在でも「パールの表記法」を理解できていない専門家はいるのでしょうか?
#統計 もしかしたら、「表記法」の話題の前に、
* モデルを変えるべきときには変えなければいけない。
* 変更後のモデルに関する結果が変更前のモデルに関する結果から得られる場合がある。
という当たり前の話から始めていれば、もっと理解者が増えていた可能性があったのではないか?
* モデルを変えるべきときには変えなければいけない。
* 変更後のモデルに関する結果が変更前のモデルに関する結果から得られる場合がある。
という当たり前の話から始めていれば、もっと理解者が増えていた可能性があったのではないか?
https://twitter.com/genkuroki/status/1618002371585671174
#統計 ゲルマンさんのブログも、regression discontinuity (所謂RDまたはRDD)のような統計的因果推論の道具がひどい使われ方をしている場合をフルボッコにしている場面は、注意しなければいけないことが分かってためになります。
https://twitter.com/genkuroki/status/1606520450598965248
#統計 do(X)は単に元のモデルからXに向けての矢線をすべて削除したモデルにおけるXによる条件付けに過ぎません。
do(X)は「Xに向けての矢印削除」というモデルの改変の話に過ぎない。
パール『因果推論の科学』第9章では「媒介」を扱うときにはdo(X)だけで済まないことが強調されています。続く
do(X)は「Xに向けての矢印削除」というモデルの改変の話に過ぎない。
パール『因果推論の科学』第9章では「媒介」を扱うときにはdo(X)だけで済まないことが強調されています。続く
https://twitter.com/genkuroki/status/1617574350835838976
#統計 続き。しかし、媒介(もしくは間接効果)も「想定する状況に合わせてモデルを変える必要がある」という当たり前の考え方に戻れば、do(X)の話の単なる拡張形としてクリアに理解できます。
それを1枚で解説してみました。
↓
それを1枚で解説してみました。
↓

#統計 Pearl 2009 web.cs.ucla.edu/~kaoru/r348.pdf (既出)経由で、Rubin 2009 onlinelibrary.wiley.com/doi/10.1002/si… を見てみました。
パールさんが指摘しているように、第2節の最初に滅茶苦茶なことが書いてあって、びっくりしました(引用は次のツイートで)。
ルービン先生はこの件では大恥をかいていると思いました。
パールさんが指摘しているように、第2節の最初に滅茶苦茶なことが書いてあって、びっくりしました(引用は次のツイートで)。
ルービン先生はこの件では大恥をかいていると思いました。
#統計 ルービン先生はこれを書いた時点では、パールさん達が繰り返し解説してくれている「へたに条件付けするとバイアスを増やす場合がある」という因果推論における基本的なことを全然理解していないように見えました。
確かにこれは酷い。
Rubin 2009 onlinelibrary.wiley.com/doi/10.1002/si…
確かにこれは酷い。
Rubin 2009 onlinelibrary.wiley.com/doi/10.1002/si…

#統計 2009年の時点でルービン先生が全く理解できなかった「Mバイアス」の話はパール『因果推論の科学』の第4章で読めます。

#統計 媒介分析の話の解説は以下のリンク先にもあります。
https://twitter.com/genkuroki/status/1614012096865513472
#統計 再度まとめ:
* 元のモデルの設定とは異なる変数の値の設定の仕方に対応する改変されたモデルを考える。
* 改変されたモデルにおける結果を元のモデルに関する結果から導ける場合がある。
* 以上の非常にもっともな考え方で、do(X)、反事実のモデル化、媒介分析をすべて理解できる。
* 元のモデルの設定とは異なる変数の値の設定の仕方に対応する改変されたモデルを考える。
* 改変されたモデルにおける結果を元のモデルに関する結果から導ける場合がある。
* 以上の非常にもっともな考え方で、do(X)、反事実のモデル化、媒介分析をすべて理解できる。
#統計 次世代の統計学教育は以下のリンク先で紹介したルービン先生によるパールさん達への態度に悪影響を受けないようにして行かないとまずいと思いました。
まずはパールさん達が言っている初歩的な話題程度は理解してから論争してくれないと不毛の極致。
まずはパールさん達が言っている初歩的な話題程度は理解してから論争してくれないと不毛の極致。
https://twitter.com/genkuroki/status/1618325453823152134
#統計 あと、すでに述べたようにパールさんによる批判対象の名前が「統計学者」になっているケースもみんな決して真似しないように気を付けるべき。
後の世代にとっては非常に迷惑なこじれ方をしている。
論理的にクリアに理解することのみを目指すべきだと思われる。
後の世代にとっては非常に迷惑なこじれ方をしている。
論理的にクリアに理解することのみを目指すべきだと思われる。
#統計 以下「確率的に決まる」を「決まる」と略す。
* YはX,M,Cから決まる。
* XはCから決まる。
* MはXとCから決まる。
というモデルMを扱っているとき、do(X)は
* Xの値をCと無関係に決める
というモデルの設定の改変を行う話になっており、続く
* YはX,M,Cから決まる。
* XはCから決まる。
* MはXとCから決まる。
というモデルMを扱っているとき、do(X)は
* Xの値をCと無関係に決める
というモデルの設定の改変を行う話になっており、続く
https://twitter.com/genkuroki/status/1618320378857918465

#統計 続き、媒介分析では、
* Cと無関係に、Yを決めるXとMを決めるXを互いに異なる値に決められるようにする。
というモデルの設定の改変が必要。
モデルの改変は「想定する状況を変えるのだから、モデルも変える必要がある」という意味で非常に自然な考え方。ある意味、当たり前の考え方。
* Cと無関係に、Yを決めるXとMを決めるXを互いに異なる値に決められるようにする。
というモデルの設定の改変が必要。
モデルの改変は「想定する状況を変えるのだから、モデルも変える必要がある」という意味で非常に自然な考え方。ある意味、当たり前の考え方。

#統計 観測データに関するモデルから同条件で次にどのような値が観測されるかを予測するときには、観測データに関するモデルの設定をそのまま使えばよい。
観測データに関するモデルに関する結果から、観測の状況とは異なる設定でどうなっていたか(いるか)を知りたい場合にはそれではすまない。続く
観測データに関するモデルに関する結果から、観測の状況とは異なる設定でどうなっていたか(いるか)を知りたい場合にはそれではすまない。続く
#統計 観測の状況とは異なる設定でどうなっていたか(いるか)を知りたい場合には、そのための別のモデルを作って使う必要があることは私には自明だと思われます。
その辺は統計学的因果推論の場合にはすでにそういうモデルの作り方が分かっているという話。続く
その辺は統計学的因果推論の場合にはすでにそういうモデルの作り方が分かっているという話。続く
#統計 パールさんも強調しているように、以上のように「欠損値の問題」という見方をするよりも、概念的により自然な
現実とは異なる状況についてのモデル構成問題
という見方をした方が分かり易いし、誤用も減るような気がします。
現実とは異なる状況についてのモデル構成問題
という見方をした方が分かり易いし、誤用も減るような気がします。
#統計 そう思った理由。欠損値に関する専門家でもあるルービン先生が2009年の段階で「Mバイアス」について見事に何も理解できていなかったように見えることの悪印象はかなり強かった。
ルービン先生でさえそうなのだから、「欠損値」ではなく、「モデル」に注目する見方の方が安心な感じがします。
ルービン先生でさえそうなのだから、「欠損値」ではなく、「モデル」に注目する見方の方が安心な感じがします。
#統計 モデル改変の立場では、ルービン先生的な潜在的アウトカム変数は元のモデルにシンプルな方法で変数を追加することによって作れます。(誤解していたら指摘して下さい。)
これ、見てもらえれば分かることですが、おっそろしくシンプルであり、「自明である」と言いたくなる類のものです。続く
これ、見てもらえれば分かることですが、おっそろしくシンプルであり、「自明である」と言いたくなる類のものです。続く

#統計 分布としてではなく個人単位で潜在アウトカム変数を扱いたい場合にはこうする。
この辺についてはパール『因果推論の科学』の第8章の「欠損データは「因果推論の根本的な問題」なのか?」「モデルのない手法の問題点」「構造的因果モデルの場合」を参照。
この辺についてはパール『因果推論の科学』の第8章の「欠損データは「因果推論の根本的な問題」なのか?」「モデルのない手法の問題点」「構造的因果モデルの場合」を参照。

#統計 添付画像のように潜在結果変数Yₖをシンプルに定義してやれば、一致性は定義から自明で、条件付き交換可能性もほぼ自明に出て来る。
これを知っていれば、ルービン流の因果推論も「必要に応じてモデルをどのように改変するかを明瞭に述べるスタイル」の立場から理解できる。
これを知っていれば、ルービン流の因果推論も「必要に応じてモデルをどのように改変するかを明瞭に述べるスタイル」の立場から理解できる。

#統計 観察される変数達に関する次のモデルを考える:treatment Z = 1,0と交絡因子XからYが確率的に決まり、さらにZの値はXの値から確率的に決まる。
観察される値Z,Xと無関係に仮想的にZの値をkとしたときのYをYₖと書き(Yₖはpotential outcome変数)、上のモデルに追加している。
↓
観察される値Z,Xと無関係に仮想的にZの値をkとしたときのYをYₖと書き(Yₖはpotential outcome変数)、上のモデルに追加している。
↓

#統計 Y,Z,X,Y₁,Y₂は確率変数になる。Y,Z,Xは観測値のモデルで、Yₖは潜在結果のモデル。
Zの実現値がkのときY=Yₖとなる(一致性)。
Xで条件付けるとZとYₖは独立になることも容易に示せる。
添付画像のようにYₖを定義しておくと、Yₖが何であるかは論理的に完璧にクリアになる。
Zの実現値がkのときY=Yₖとなる(一致性)。
Xで条件付けるとZとYₖは独立になることも容易に示せる。
添付画像のようにYₖを定義しておくと、Yₖが何であるかは論理的に完璧にクリアになる。

#統計 統計的因果推論の解説で Yₖ や Yᶻ⁼ᵏ のような記号法が出て来てよく分からなくなった人は、このツイートのすぐ上の方を見れば論理的に曖昧に見えた点を解消できるかも。
現実に観察される状況と異なる状況を仮想的に想定するにはそのためのモデルの設定が必要。単にそれだけの話。
現実に観察される状況と異なる状況を仮想的に想定するにはそのためのモデルの設定が必要。単にそれだけの話。
#統計 潜在アウトカム変数 Yₖ=Yᶻ⁼ᵏについて「データの数表中の空いている項目」=「欠損値」的なイメージで説明されてしまうと、潜在的なアウトカムをどのようにモデル化しているかが見え難くなり、非常に分かり難くなると私は思います。
モデルの設定をクリアに説明してくれると非常に助かる。
モデルの設定をクリアに説明してくれると非常に助かる。
#統計 統計学入門の段階から、どのようなモデルを設定して分析を行なっているかの理解を軽視させるような教え方が伝統的にあって大問題だと思っています。
t検定やWilcoxonの順位和検定のあたりで相当にまずいことになっている。
そういう傾向を統計的因果推論に持ち込みたくないです。
t検定やWilcoxonの順位和検定のあたりで相当にまずいことになっている。
そういう傾向を統計的因果推論に持ち込みたくないです。
#統計 他にも色々気になることがあって、統計学の文脈では、
確率変数Yの期待値 E[Y]
と
サンプルY¹,…,Yⁿの平均 (1/n)Σ_{i=1}^n Yⁱ
を厳密に区別して欲しいと思います。後者は前者の推定値(確率変数とみなすときは推定量)でしかない。
この辺で問題のある因果推論の解説はアウト。
確率変数Yの期待値 E[Y]
と
サンプルY¹,…,Yⁿの平均 (1/n)Σ_{i=1}^n Yⁱ
を厳密に区別して欲しいと思います。後者は前者の推定値(確率変数とみなすときは推定量)でしかない。
この辺で問題のある因果推論の解説はアウト。
• • •
Missing some Tweet in this thread? You can try to
force a refresh