#OpenAI is planning to stop #ChatGPT users from making social media bots and cheating on homework by "watermarking" outputs. How well could this really work? Here's just 23 words from a 1.3B parameter watermarked LLM. We detected it with 99.999999999994% confidence. Here's how 🧵 

This article, and a blog post by Scott Aaronson, suggest that OpenAI will deploy something similar to what I describe. The watermark below can be detected using an open source algorithm with no access to the language model or its API.
businessinsider.com/openai-chatgpt…
businessinsider.com/openai-chatgpt…
Language models generate text one token at a time. Each token is selected from a “vocabulary” with about 50K words. Before each new token is generated, we imprint the watermark by first taking the most recent token and using it to seed a random number generator (RNG).
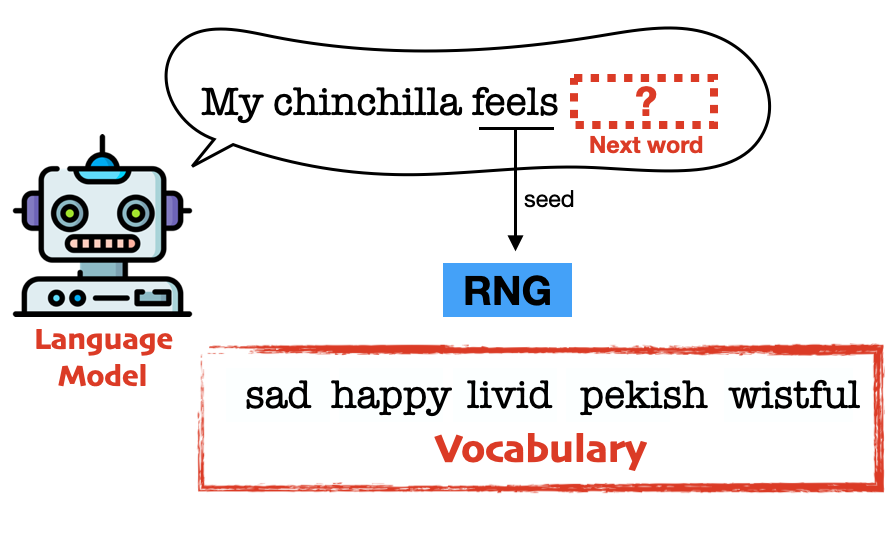
Using the RNG, we randomly partition the vocabulary into a whitelist and a blacklist. We then ask the LLM to choose the next word, but we restrict its choices to the whitelist.

Later, we can detect the watermark by counting whitelist tokens. If N tokens are generated and all are whitelisted, the chance of a human writing this is only 1/2^N. Even for a short tweet with N=25 tokens, we can be quite sure whether the tweet is human or machine written.
But alas, this watermark is junk. Suppose the LLM outputs “SpongeBob Square”. The next token must be “Pants,” right? But this word could be blacklisted. This hurts language modeling performance…a lot. We call this a “low entropy token" because the LLM has few good choices.
There’s also “high entropy” tokens, as in the sentence “SpongeBob feels _____". We can fill the blank with good/great/fine or many others.
We can make the watermark good by strongly applying the blacklist rule to high-entropy tokens, while leaving low entropy tokens alone.
We can make the watermark good by strongly applying the blacklist rule to high-entropy tokens, while leaving low entropy tokens alone.
Now we add beam search, allowing the LLM to look ahead and plan a whole sequence of tokens that avoids the blacklist. By doing this (and other tricks) we can get to a ≈80% whitelist usage rate with very little change in text quality (as measured by perplexity).

So how do we know the example in my first tweet is watermarked? It has 36 tokens. A human should use 9±2.6 whitelist words (each whitelist contains 25% of the vocab). But it has 28. That's a 7-sigma event. The chance of a human doing this (i.e., the p-value) is 0.00000000000006.

Here's the blacklist tokens in case you were wondering.
Finally, I'll mention that the watermark needs to be implemented properly to make it secure against removal attacks. Proper text normalization must be used, and certain kinds of adversarial prompts need to be detected.
Finally, I'll mention that the watermark needs to be implemented properly to make it secure against removal attacks. Proper text normalization must be used, and certain kinds of adversarial prompts need to be detected.

Our paper does a deep dive on watermarks. It discusses practical implementations and security/cryptographic issues. We also derive nerdy information-theoretic bounds on the detector sensitivity and text perplexity. arxiv.org/abs/2301.10226
This project was made possible by the codehackery of @jwkirchenbauer, @jonasgeiping, and @ywen99, plus the cryptosorcery of @secparam and @jon_katz. Thanks!
• • •
Missing some Tweet in this thread? You can try to
force a refresh