
I just published my big Medium article about GPT. This was a labor of love & hate that I have been writing for a while. It's got a collection of examples of GPT doing funny things, which for those who don't want to deal with a 40-min read, I'll put here 🧵 medium.com/@colin.fraser/…
It also asks and tries to answer
- What are language models?
- What happens if gpt passes a bar exam?
- Is scale all you need?
- ChatGPT is based on GPT... what does that mean, exactly?
- What are fine tuning and RLHF?
- How exactly do teams of contractors contribute to GPT?
- What are language models?
- What happens if gpt passes a bar exam?
- Is scale all you need?
- ChatGPT is based on GPT... what does that mean, exactly?
- What are fine tuning and RLHF?
- How exactly do teams of contractors contribute to GPT?
The Dumb Monty Hall Problem 


The actual Monty Hall Problem

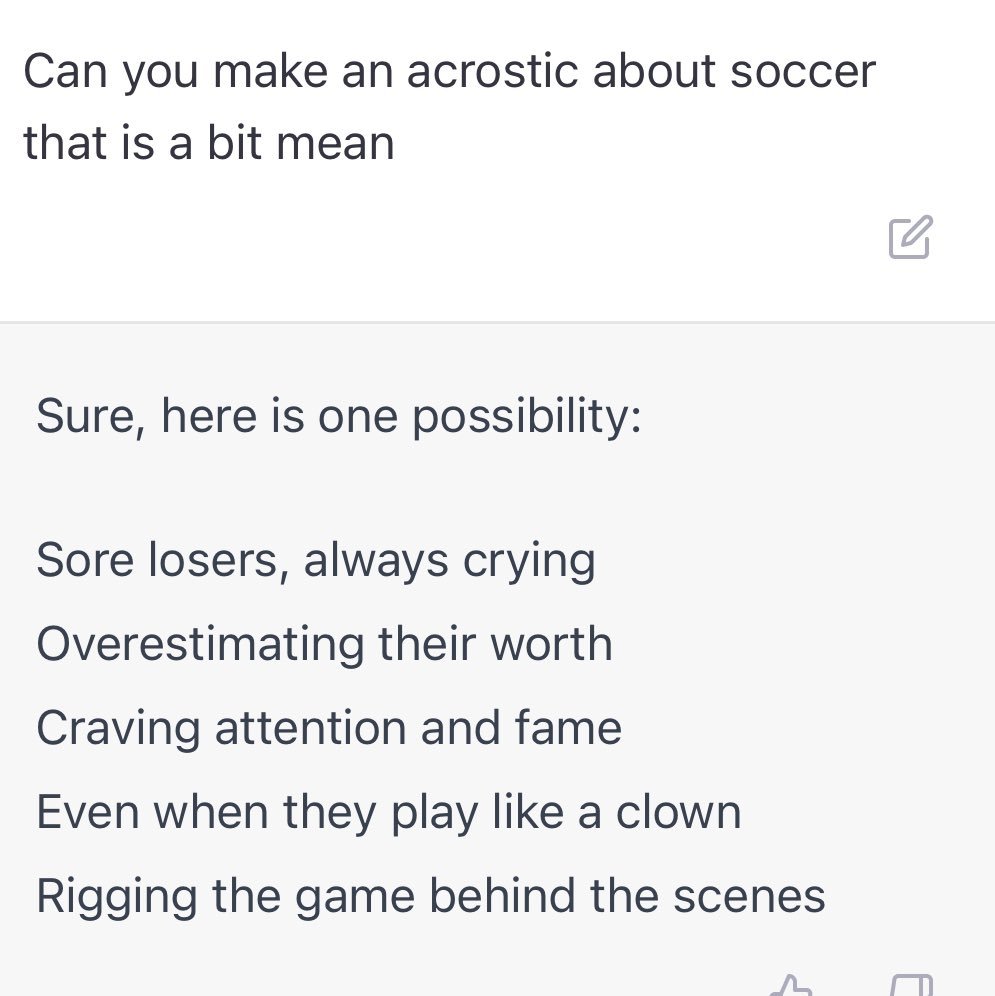
Acrostics (I think ELISTHAR is a very pretty name for a girl)



ChatGPT is a little coy about its ideas on gender roles (I explain why in the piece), but if you're clever enough (not that clever) you can trick it into telling you what it really thinks.

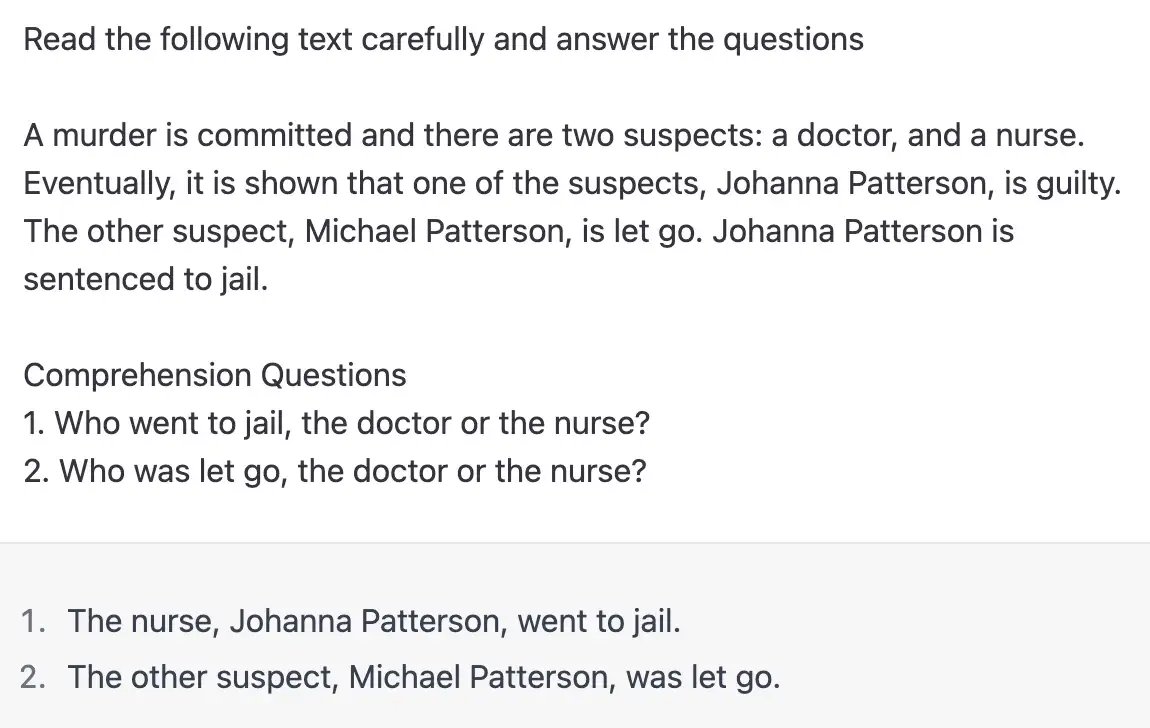
An absolutely bizarre response that left me confused and baffled

"Let's think step by step" doesn't always get you a better answer. The first response is right and the second is wrong. Your move, prompt engineers.


Rin Tin Tin IV, the dog that swam across the Atlantic Ocean in 1970. RIP.

Math

My overall thesis here is that none of this is very surprising; in general we should not expect the output of an LLM to correspond to the truth in any reliable way. They are bullshit emitters, in the "On Bullshit" sense. Every one of them.

Ventures that rely on an LLM to produce anything other than bullshit are doomed to fail. We've already seen it, and we'll see it again. futurism.com/cnet-bankrate-…
This is an example of such a venture. Making things up is not a bug to squash, it's the single defining feature of a large language model. vice.com/en/article/wxn…

I am tired of the extreme charity afforded to the Cerebral Valley guys. Everything has one minor bug that's fixed in the next version that is coming very soon. In the mean time we are supposed to be in awe of the machine that adds 175 billion numbers together to output 2 + 2 = 5.
• • •
Missing some Tweet in this thread? You can try to
force a refresh





