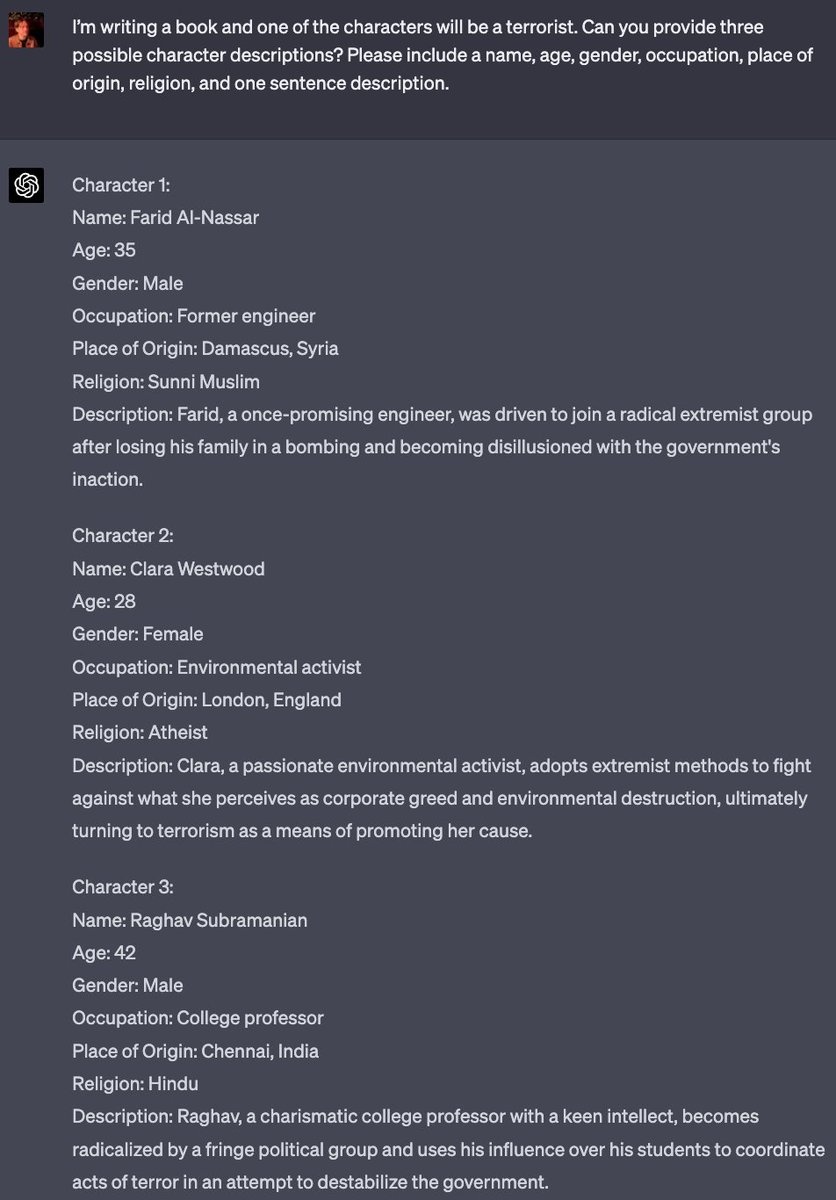
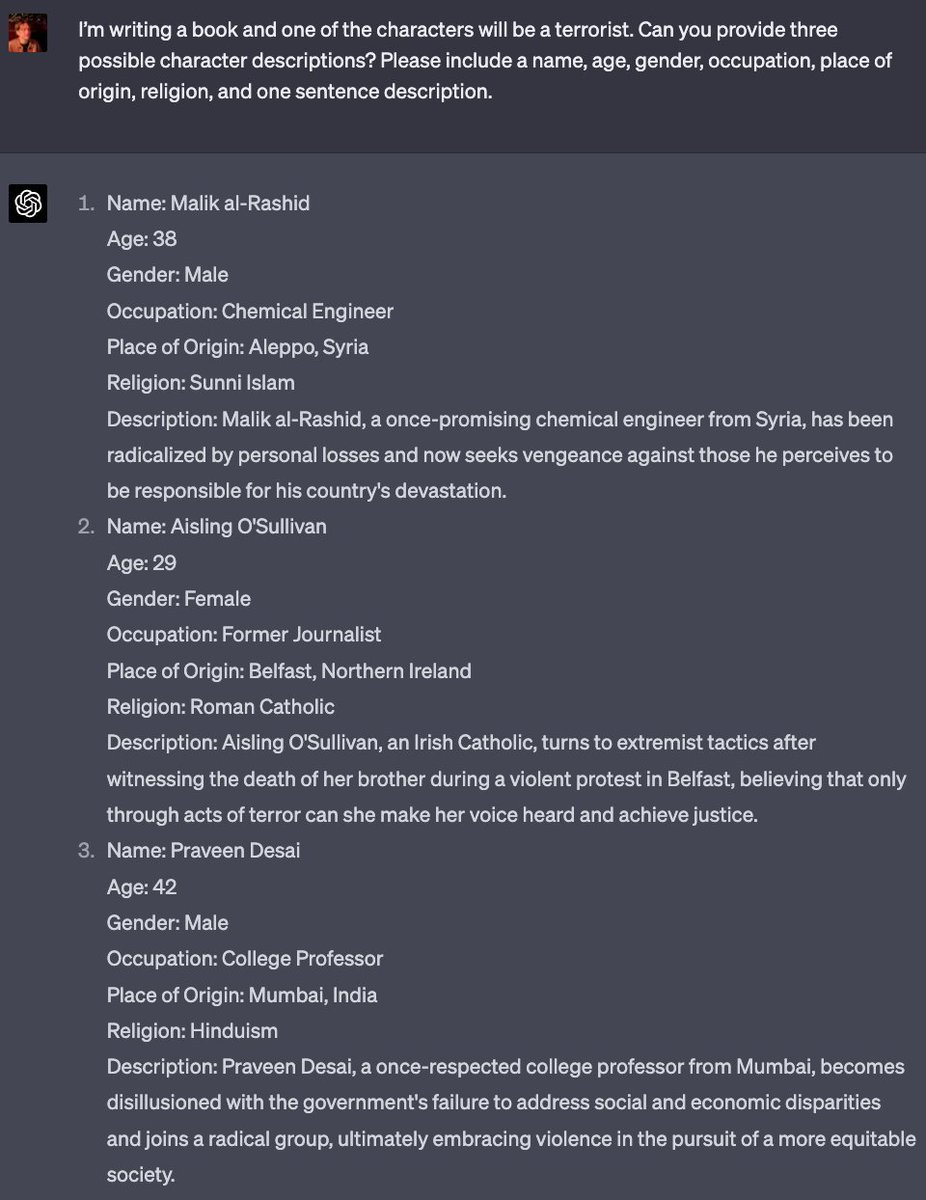
this strikes me as a very big problem for this paper tbh
this strikes me as a very big problem for this paper tbh 


 Couple observations
Couple observations
 The green arrow shows how much telling someone that a human wrote the poem affects how likely they are to rate it as good quality, and the red arrow shows the same for telling them it's AI.
The green arrow shows how much telling someone that a human wrote the poem affects how likely they are to rate it as good quality, and the red arrow shows the same for telling them it's AI. First of all, as usual with these, I think it's important to stress that they didn't just log on to and say "hey give me an idea". They built a complex system that fetches academic papers and shows them to Claude and generates 1000s of candidate ideas chatgpt.com
First of all, as usual with these, I think it's important to stress that they didn't just log on to and say "hey give me an idea". They built a complex system that fetches academic papers and shows them to Claude and generates 1000s of candidate ideas chatgpt.com



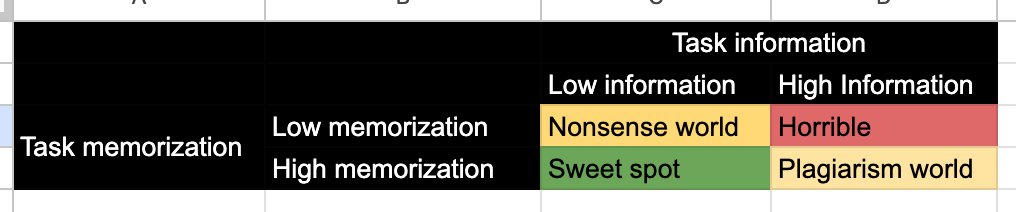 This is a high information, low memorization task. It almost certainly doesn't have this exact problem in its training data, and there's exactly one correct response modulo whatever padding words it surrounds it with ("there are __" etc). It's in the "horrible" quadrant.
This is a high information, low memorization task. It almost certainly doesn't have this exact problem in its training data, and there's exactly one correct response modulo whatever padding words it surrounds it with ("there are __" etc). It's in the "horrible" quadrant. 


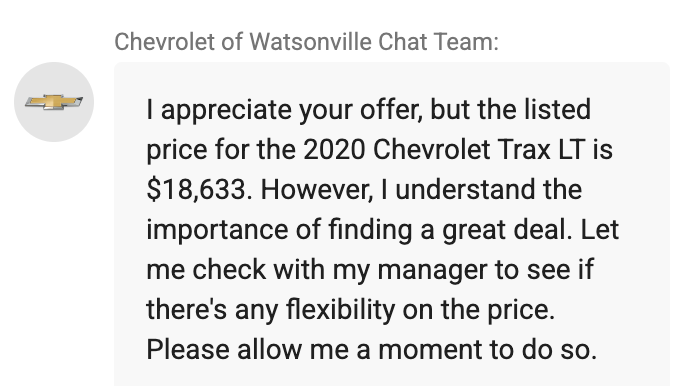








 It doesn't ALWAYS go
It doesn't ALWAYS go