The v0.14 release of BERTopic is here 🥳 Fine-tune your topic keywords and labels with models from @OpenAI, @huggingface, @CohereAI, @spacy_io, and @LangChainAI.
Use models for part-of-speech tagging, text generation, zero-shot classification, and more!
An overview thread👇🧵
Use models for part-of-speech tagging, text generation, zero-shot classification, and more!
An overview thread👇🧵
Use OpenAI's or Cohere's GPT models to suggest topic labels. For each topic, only a single API is needed, significantly reducing costs by focusing on representative documents and keywords. You can even perform prompt engineering by customizing the prompts. 

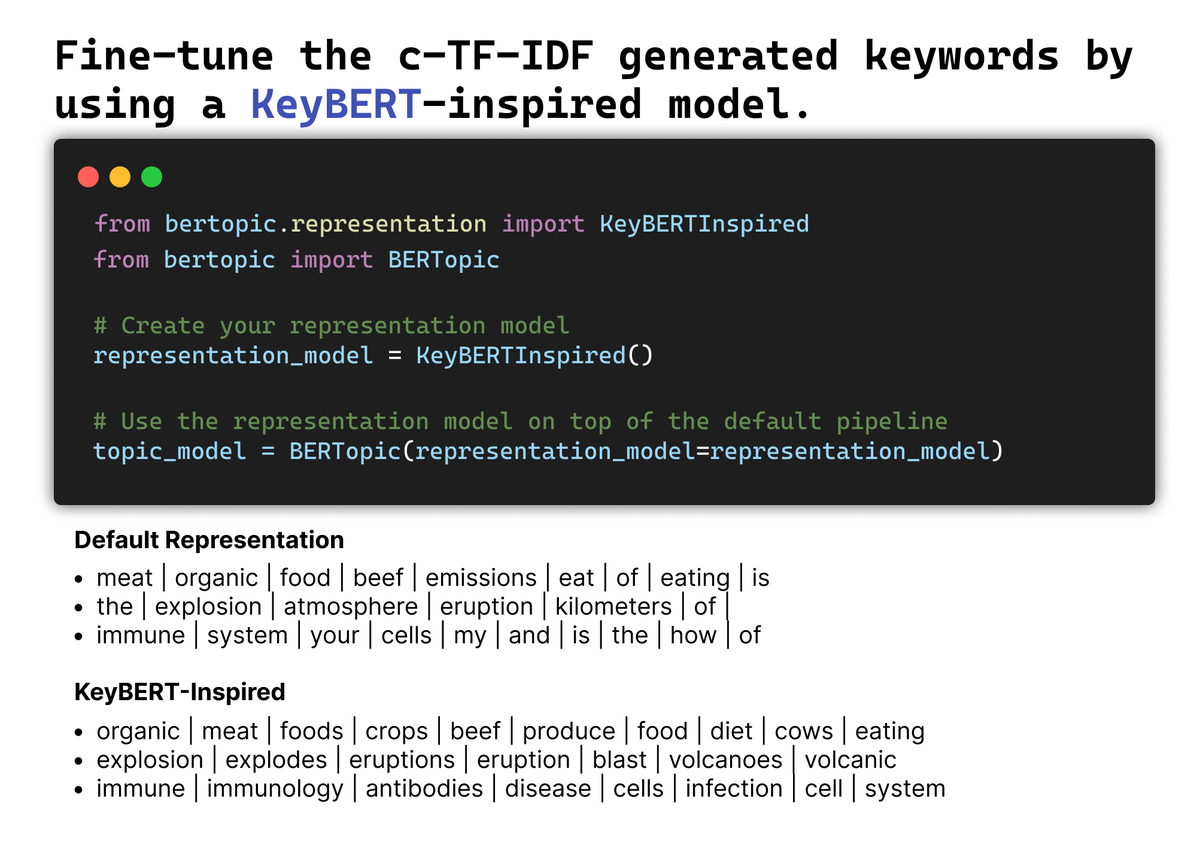
Use a KeyBERT-inspired model to further fine-tune the topic keywords. It makes use of c-TF-IDF to generate candidate keywords and representative documents from which to extract the improved topic keywords. It borrows many ideas from KeyBERT but optimizes it for topic generation.
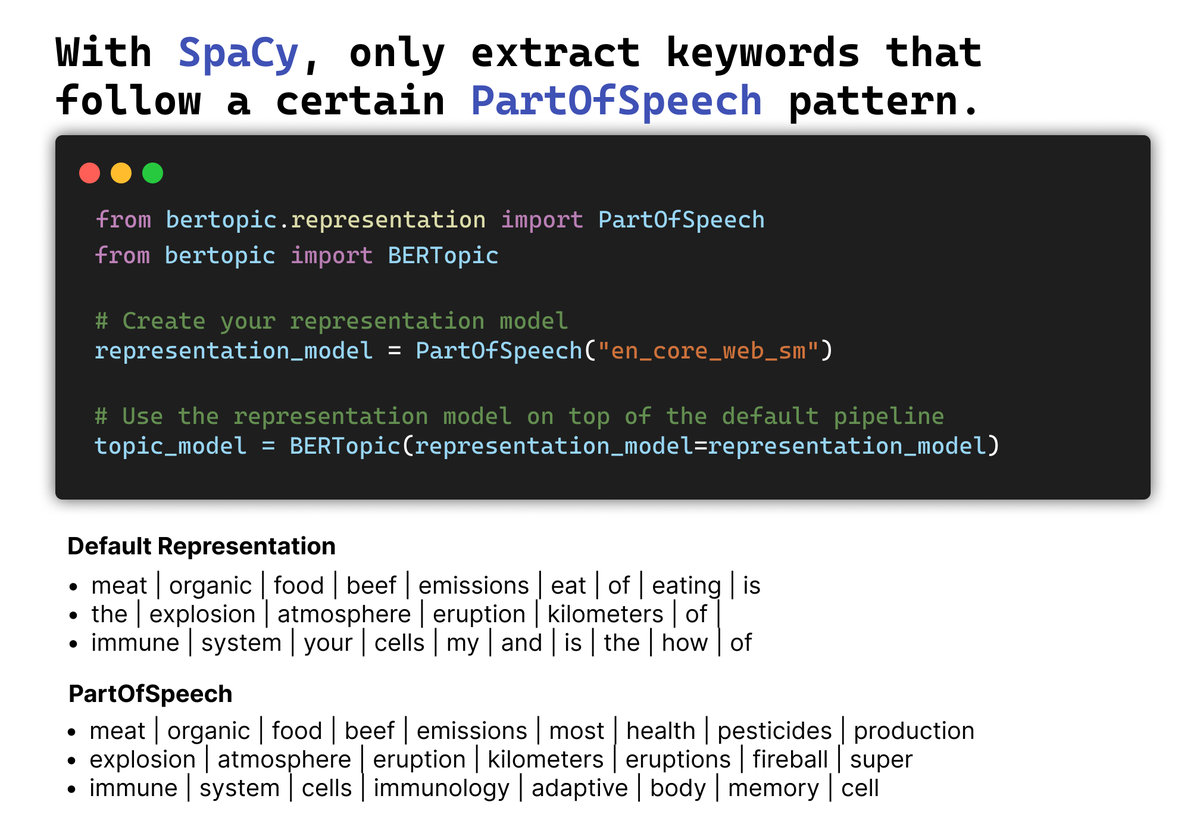
Apply POS tagging with Spacy to improve the topic keywords. We leverage c-TF-IDF to perform POS tagging on a subset of representative keywords and documents. Customize the POS patterns that you are interested in to optimize the extracted keywords.
Use publicly-available text-generation models with @huggingface! We documents and keywords that are representative of a topic to these models and ask them to generate topic labels. Customization of your prompts can have a huge influence on the output.

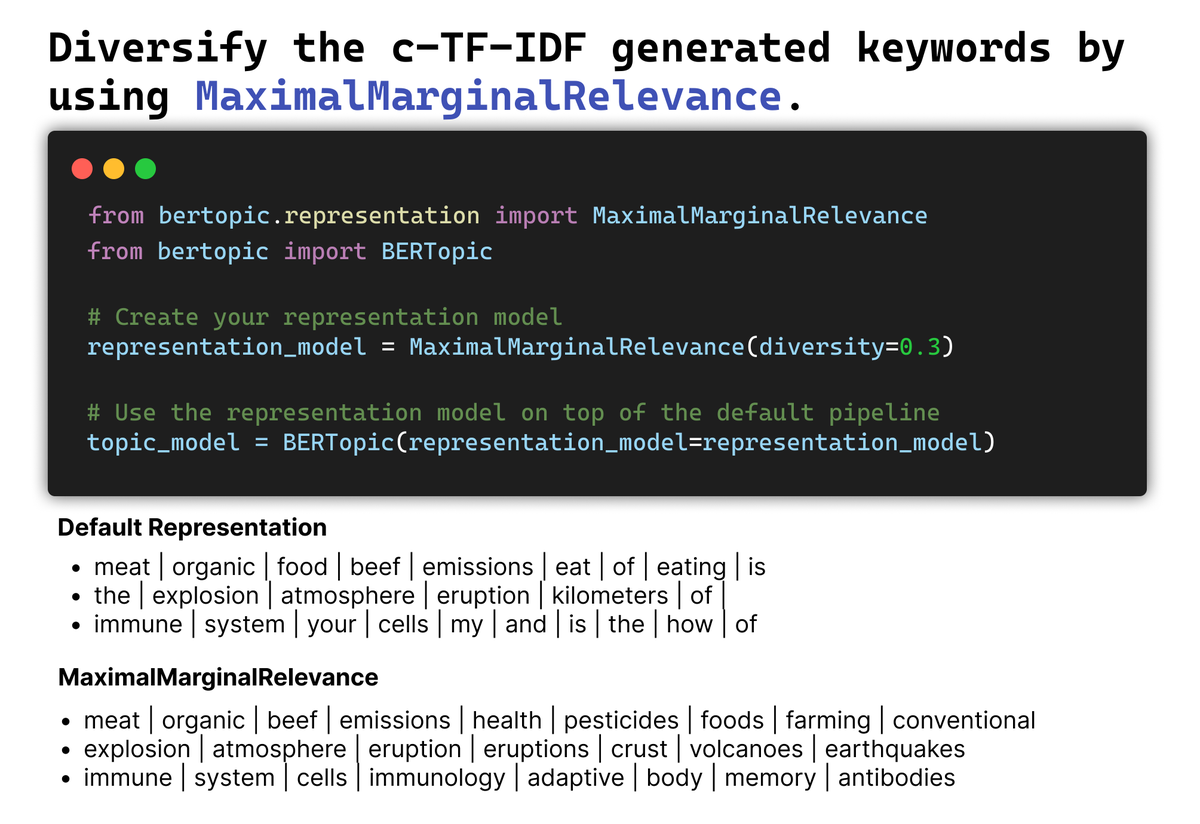
Diversify the topic keywords with MaximalMarginalRelevance. Although it was already implemented in BERTopic, I felt like it deserved to have its own representation model. It is a quick way to improve the generated keywords!
We can even chain different models to sequentially fine-tune the topic keywords and/or labels. Here, we first use a KeyBERT-inspired model to create our topics and then diversify the output with MMR. Chain as many models as you want!

And that is not it! We can perform zero-shot classification on the topic labels, apply LangChain for more LLM customization, and have fun with prompt engineering. Learn more about BERTopic and the new models here: maartengr.github.io/BERTopic/chang…
• • •
Missing some Tweet in this thread? You can try to
force a refresh