We’re really excited to introduce a new index type to @gpt_index: a Knowledge Graph 🧠 index! Build a KG by extracting triplets, and leverage the KG during query-time.
This index was inspired by @varunshenoy_’s great work on #GraphGPT. See below for how it works 👇
This index was inspired by @varunshenoy_’s great work on #GraphGPT. See below for how it works 👇

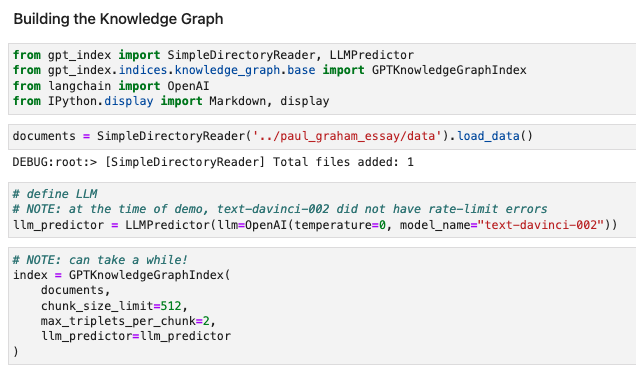
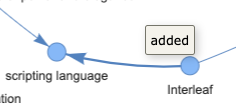
We build the index by extracting knowledge triplets in the form (subject, predicate, object), over a set of docs.
Each subject and object represents a Node in the graph. We also store references 🔖 from each node to the underlying text.
See an example 🖼️ from @paulg’s essay.
Each subject and object represents a Node in the graph. We also store references 🔖 from each node to the underlying text.
See an example 🖼️ from @paulg’s essay.

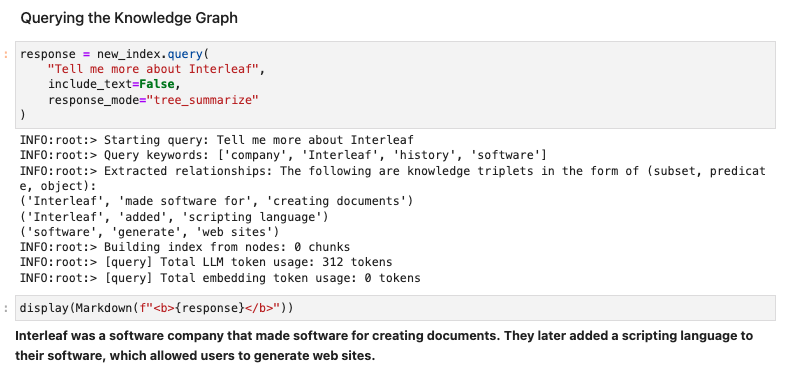
During query-time, we have two options: 1) query using just the KG as context, or also 2) leverage the underlying text from each entity as context.
A simple example with (1) is given below:
A simple example with (1) is given below:
With (2), we can ask more complicated queries with respect to the contents of the document.
Since the essay is about the author’s experience at Interleaf, we can ask questions about that even if the KG doesn’t explicitly contain that info!
Since the essay is about the author’s experience at Interleaf, we can ask questions about that even if the KG doesn’t explicitly contain that info!
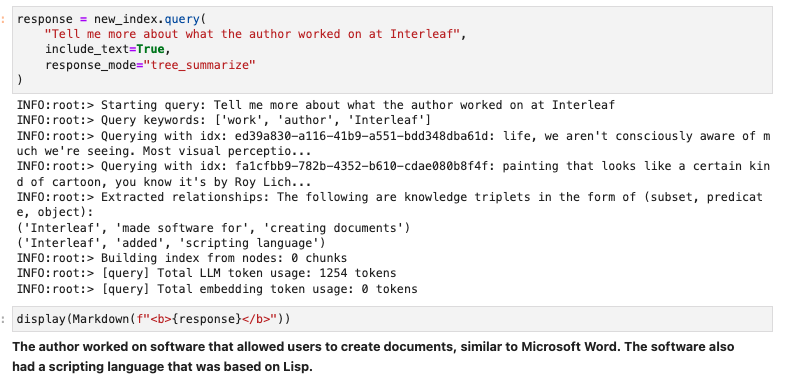
It is pretty simple to visualize the graph as well. Take a look at the sample code + visualizations below! github.com/jerryjliu/gpt_…
If you want to play around with this, check out our sample notebook 📓 here! Some of this is WIP, very open to feedback 🙂
If you want to play around with this, check out our sample notebook 📓 here! Some of this is WIP, very open to feedback 🙂

• • •
Missing some Tweet in this thread? You can try to
force a refresh