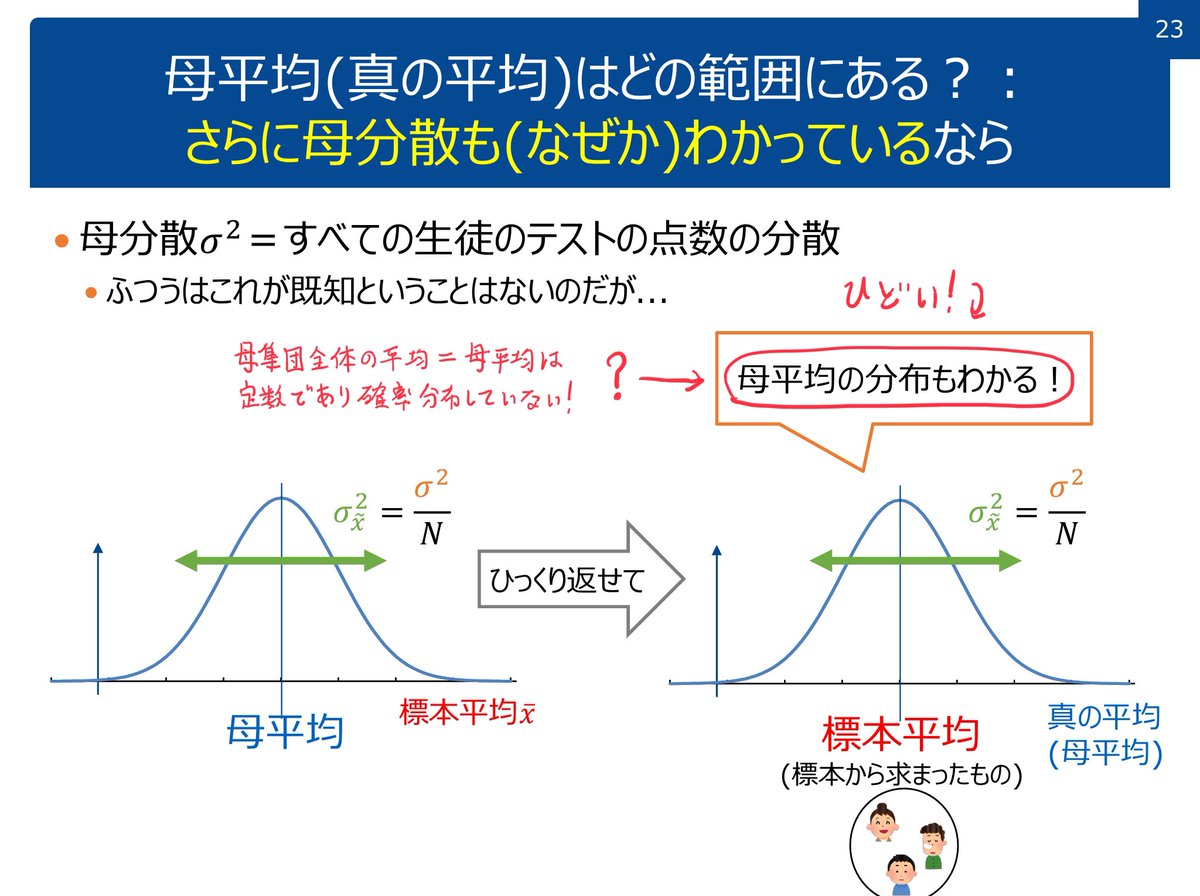
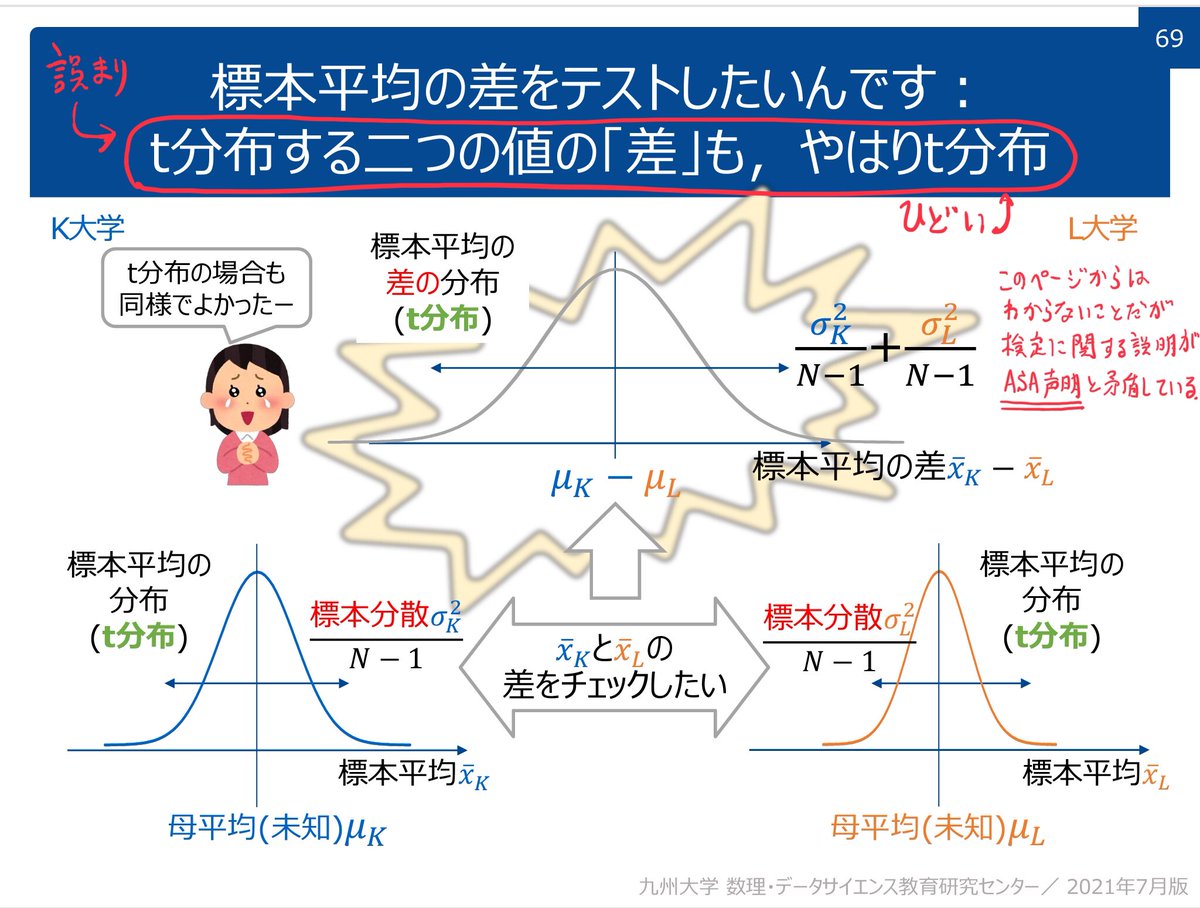
#統計 speakerdeck.com/taka88/pzhi-fa… のp.7からp.8への流れは、natureの記事の内容を誤解させるような、よろしくない解説の仕方だと思いました。
「差がない」という特別な帰無仮説の検定だけで勝負を決めようとすることへの批判をP値そのものへの批判とみなすことは、よく見る杜撰な考え方です。続く
「差がない」という特別な帰無仮説の検定だけで勝負を決めようとすることへの批判をP値そのものへの批判とみなすことは、よく見る杜撰な考え方です。続く
https://twitter.com/Shuntarooo3/status/1628297493007192064


#統計 実際、natureの記事 nature.com/articles/d4158… ではcompati{ble,bility}が重要キーワードになっており、P値が
データ、モデル、パラメータ値のcompatibility(相性の良さ、両立性)の指標の1つ
とみなされることを詳しく説明しています。
この部分に触れずにこの記事を引用しても無意味。続く
データ、モデル、パラメータ値のcompatibility(相性の良さ、両立性)の指標の1つ
とみなされることを詳しく説明しています。
この部分に触れずにこの記事を引用しても無意味。続く

#統計 natureのその記事を読んでいるならば、P値のcompatibilityとしての解釈について知り、添付画像のように、ダメな考え方と正しい考え方を区別できるようになっているはずなのです。
否定するべき対象にP値そのものが含まれていないことに注目!
続く
否定するべき対象にP値そのものが含まれていないことに注目!
続く
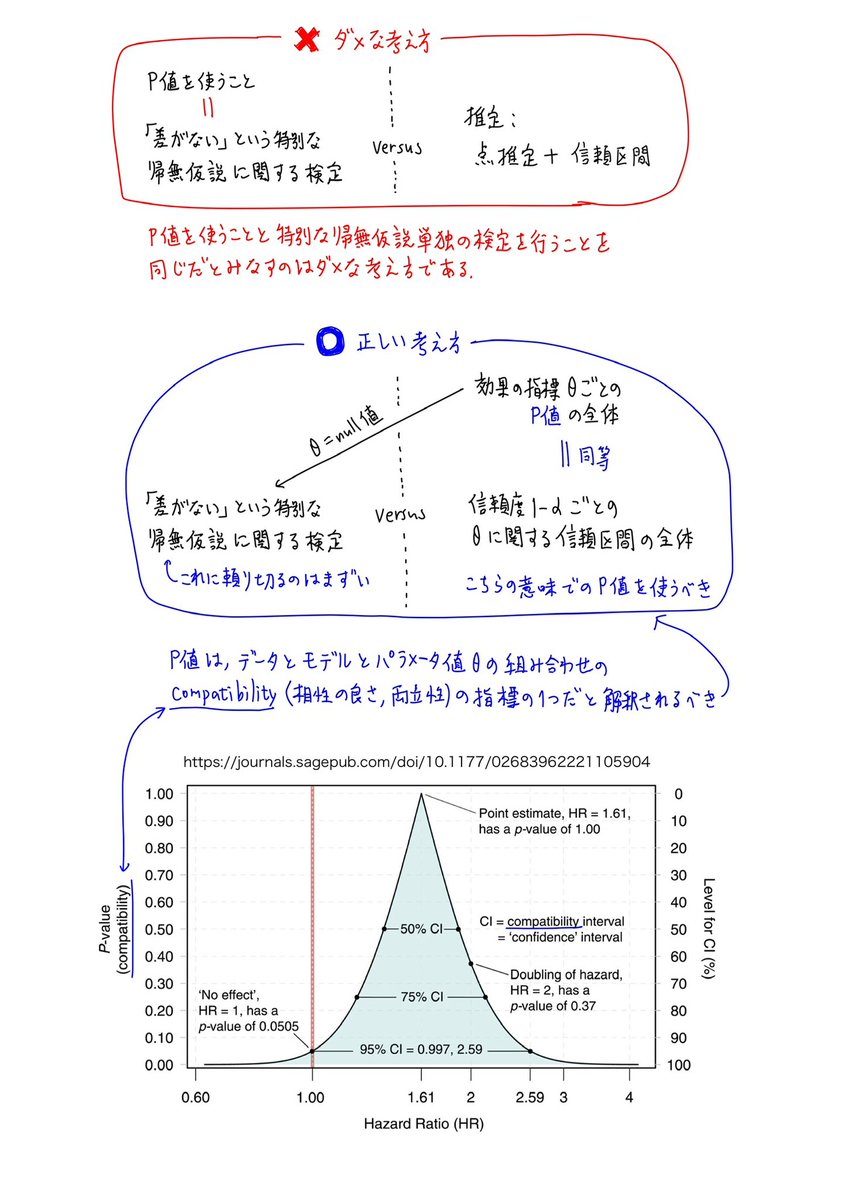
#統計 「効果がない」という特別な帰無仮説に関する単独のP値や検定だけで勝負を決めようとする態度を否定する常識的な考え方と、「P値や検定自体が否定されている」のような杜撰な考え方では大違いです。
後者は統計学教育の観点から有害なので、きちんと否定して行く必要があると思います。
後者は統計学教育の観点から有害なので、きちんと否定して行く必要があると思います。
#統計 教育面での危惧は『統計的有意性とP値に関するASA声明』の翻訳者の佐藤俊哉さんも
jstage.jst.go.jp/article/jjb/38…
の最後の段落で表明しています(添付画像)。
検定と信頼区間の理論が表裏一体であることは多くの数理統計学の教科書で解説されている常識の1つだと思います(無知な人達に注意)。続く
jstage.jst.go.jp/article/jjb/38…
の最後の段落で表明しています(添付画像)。
検定と信頼区間の理論が表裏一体であることは多くの数理統計学の教科書で解説されている常識の1つだと思います(無知な人達に注意)。続く

#統計 P値や検定の全体を否定して、信頼区間の方を使うべきだ、と述べている人達は、基本的なことをよく理解せずに、統計学教育的に有害な意見を述べていることになります。
否定するべきなのは、特別な帰無仮説のP値や検定だけで勝負を決しようとする科学的に非常識な態度の方です。
否定するべきなのは、特別な帰無仮説のP値や検定だけで勝負を決しようとする科学的に非常識な態度の方です。
#統計 「効果はない」という特殊な帰無仮説の検定を特別に重視する非常識な考え方を常識的に否定しつつ、P値や信頼区間の健全な使い方について知りたい人には次の短い論文がお勧めです。
これの著者は既出のnatureの記事の著者3人のうちの2人です。
journals.sagepub.com/doi/10.1177/02…
これの著者は既出のnatureの記事の著者3人のうちの2人です。
journals.sagepub.com/doi/10.1177/02…
#統計 さらにそのnatureの記事のもう1人の著者とゲルマンさんの共著の次の論文もお勧めです。
stat.columbia.edu/~gelman/resear…
それらのどこでもP値の使用自体は否定されていません。
件のnarureの記事をろくに読まずに、統計学教育的に有害な言説を拡散する行為には明瞭に批判的であるべきだと思います。
stat.columbia.edu/~gelman/resear…
それらのどこでもP値の使用自体は否定されていません。
件のnarureの記事をろくに読まずに、統計学教育的に有害な言説を拡散する行為には明瞭に批判的であるべきだと思います。
#統計 おまけの余談
Greenlandさん達は信頼区間をcompatibility intervalと呼ぶことを提案しているのですが、McElreathさんはStatistical Rethinkingでベイズ信用区間もcompatibility intervalと呼んでおり、私もその考え方に賛成です。続く
Greenlandさん達は信頼区間をcompatibility intervalと呼ぶことを提案しているのですが、McElreathさんはStatistical Rethinkingでベイズ信用区間もcompatibility intervalと呼んでおり、私もその考え方に賛成です。続く
#統計 余談続き
ベイズ統計での事後分布も、P値と同様に、
データの数値
モデル(事前分布を含む)
パラメータの値
の相性の良さ(compatibility, 両立性)の指標を与えているとみなせます。モデルに事後分布が含まれる点がP値の場合とは違っているが、考え方は同様で良い。
ベイズ統計での事後分布も、P値と同様に、
データの数値
モデル(事前分布を含む)
パラメータの値
の相性の良さ(compatibility, 両立性)の指標を与えているとみなせます。モデルに事後分布が含まれる点がP値の場合とは違っているが、考え方は同様で良い。
#統計 Statistical Rethinkingの2nd editionの1,2章はネットで公開されている。
xcelab.net/rmpubs/sr2/sta…
さらに講義の動画とスライドがGitHubで公開されている。
2022年
github.com/rmcelreath/sta…
2023年
github.com/rmcelreath/sta…
統計的因果推論入門になっている部分が多い。冗談が非常に多い!
xcelab.net/rmpubs/sr2/sta…
さらに講義の動画とスライドがGitHubで公開されている。
2022年
github.com/rmcelreath/sta…
2023年
github.com/rmcelreath/sta…
統計的因果推論入門になっている部分が多い。冗談が非常に多い!
#統計
統計的有意性とP値に関するASA声明の日本語版
biometrics.gr.jp/news/all/ASA.p…
翻訳者による講義動画
ocwcentral.com/subjects/01GB4…
統計的有意性とP値に関するASA声明の日本語版
biometrics.gr.jp/news/all/ASA.p…
翻訳者による講義動画
ocwcentral.com/subjects/01GB4…
• • •
Missing some Tweet in this thread? You can try to
force a refresh