Today we release LLaMA, 4 foundation models ranging from 7B to 65B parameters.
LLaMA-13B outperforms OPT and GPT-3 175B on most benchmarks. LLaMA-65B is competitive with Chinchilla 70B and PaLM 540B.
The weights for all models are open and available at research.facebook.com/publications/l…
1/n
LLaMA-13B outperforms OPT and GPT-3 175B on most benchmarks. LLaMA-65B is competitive with Chinchilla 70B and PaLM 540B.
The weights for all models are open and available at research.facebook.com/publications/l…
1/n

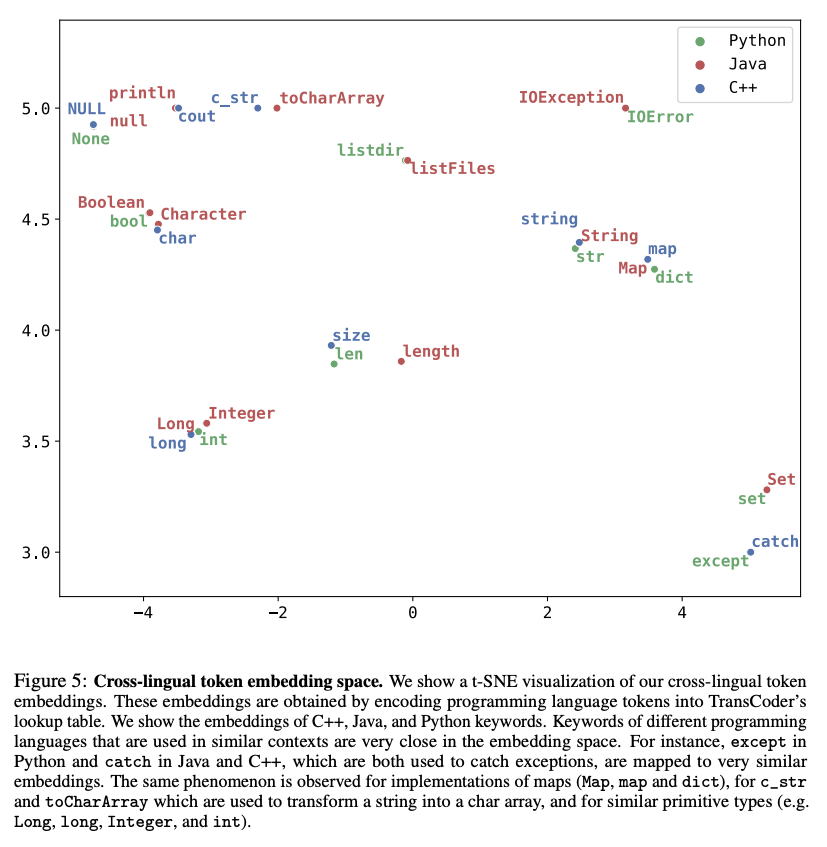
Unlike Chinchilla, PaLM, or GPT-3, we only use datasets publicly available, making our work compatible with open-sourcing and reproducible, while most existing models rely on data which is either not publicly available or undocumented.
2/n
2/n

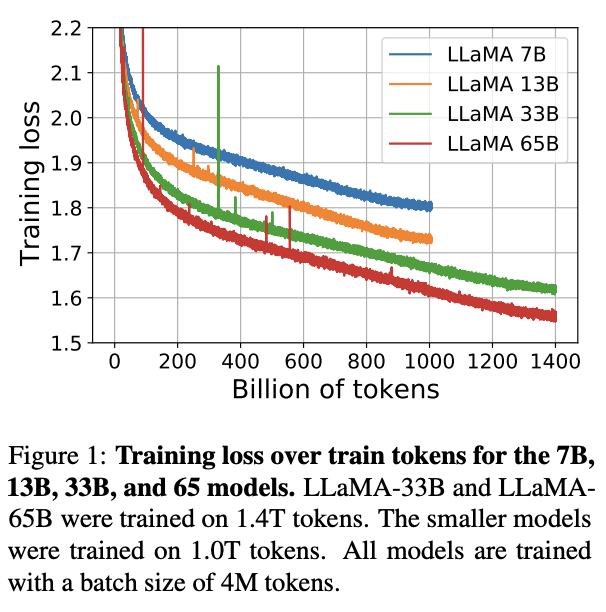
All our models were trained on at least 1T tokens, much more than what is typically used at this scale.
Interestingly, even after 1T tokens the 7B model was still improving.
3/n
Interestingly, even after 1T tokens the 7B model was still improving.
3/n


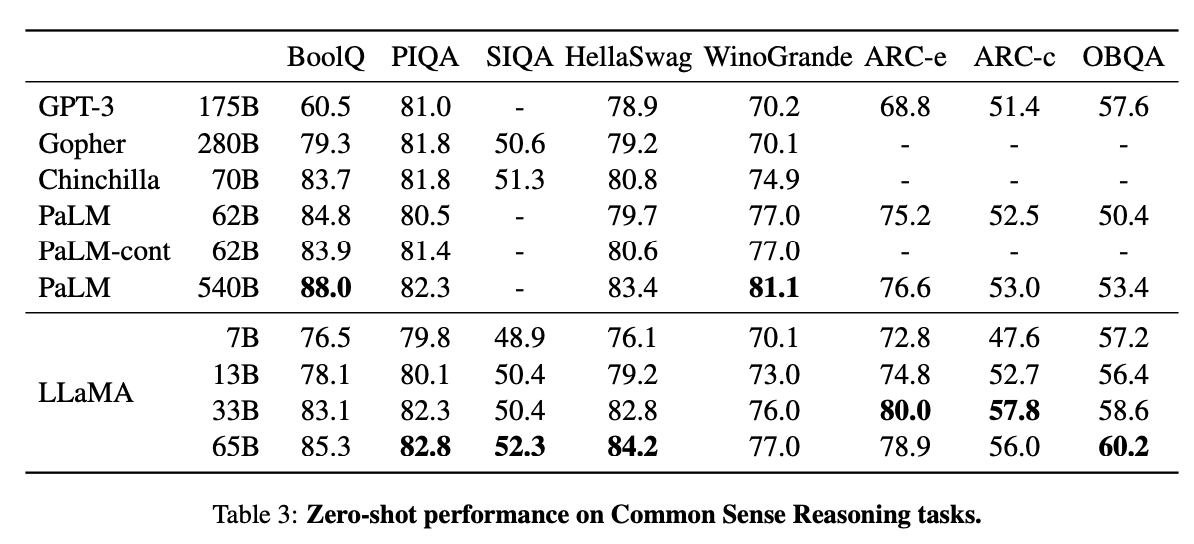
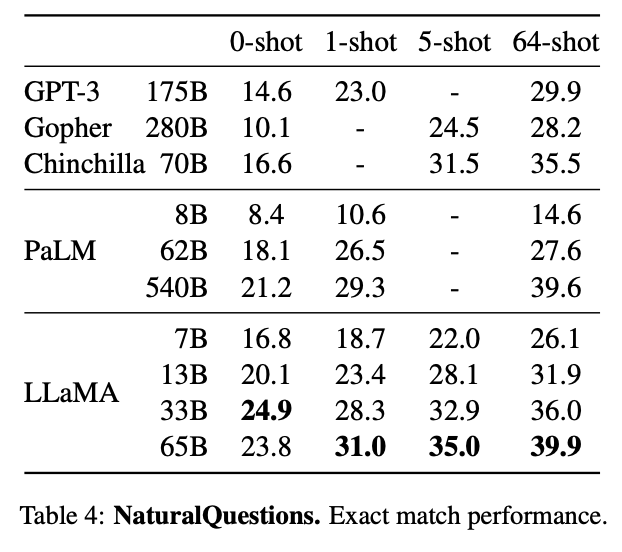
On Common Sense Reasoning, Closed-book Question Answering, and Reading Comprehension, LLaMA-65B outperforms Chinchilla 70B and PaLM 540B on almost all benchmarks.
4/n
4/n




LLaMA-65B outperforms Minerva-62B on GSM8k, even though it has not been fine-tuned on any mathematical dataset. On the MATH benchmark, it outperforms PaLM-62B (but is quite below Minerva-62B)
5/n
5/n

On code generation benchmarks, LLaMA-62B outperforms cont-PaLM (62B) as well as PaLM-540B.

We also briefly tried instruction finetuning using the approach of Chung et al. (2022).
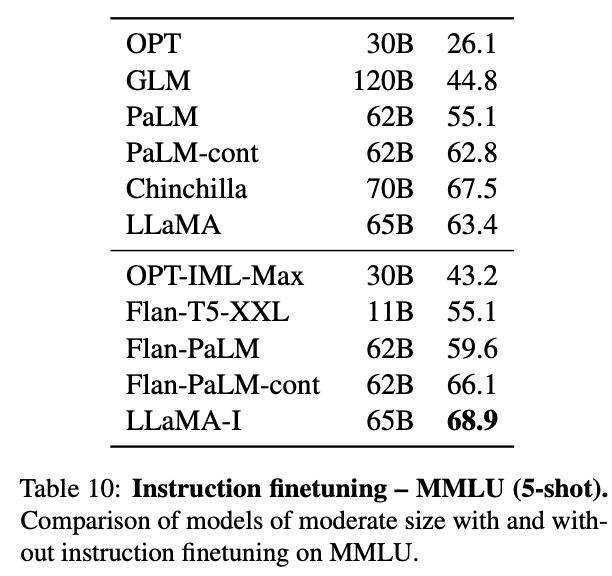
The resulting model, LLaMA-I, outperforms Flan-PaLM-cont (62B) on MMLU and showcases some interesting instruct capabilities.
7/n
The resulting model, LLaMA-I, outperforms Flan-PaLM-cont (62B) on MMLU and showcases some interesting instruct capabilities.
7/n



With @HugoTouvron, @LavrilThibaut, @gizacard, @javier_m, @MaLachaux, @tlacroix6, @b_roziere, @NamanGoyal21, Eric Hambro, Faisal Azhar, @AurR0d, @armandjoulin, @EXGRV
8/8
8/8
• • •
Missing some Tweet in this thread? You can try to
force a refresh