看到不少人推荐 #ChatPDF, 上传 PDF 文件后调用 ChatGPT 生成总结和问答。刚好我申请的微软 New Bing 也通过了,用同一份 PDF 做了下比较,结论如下:
1. New Bing: 总结能力惊艳(见下图),但限制了交互次数
2. ChatPDF: PDF上传方便,但总结能力一般
3. 都会瞎编内容
具体评测和使用地址👇
1/10
1. New Bing: 总结能力惊艳(见下图),但限制了交互次数
2. ChatPDF: PDF上传方便,但总结能力一般
3. 都会瞎编内容
具体评测和使用地址👇
1/10
1️⃣ New Bing
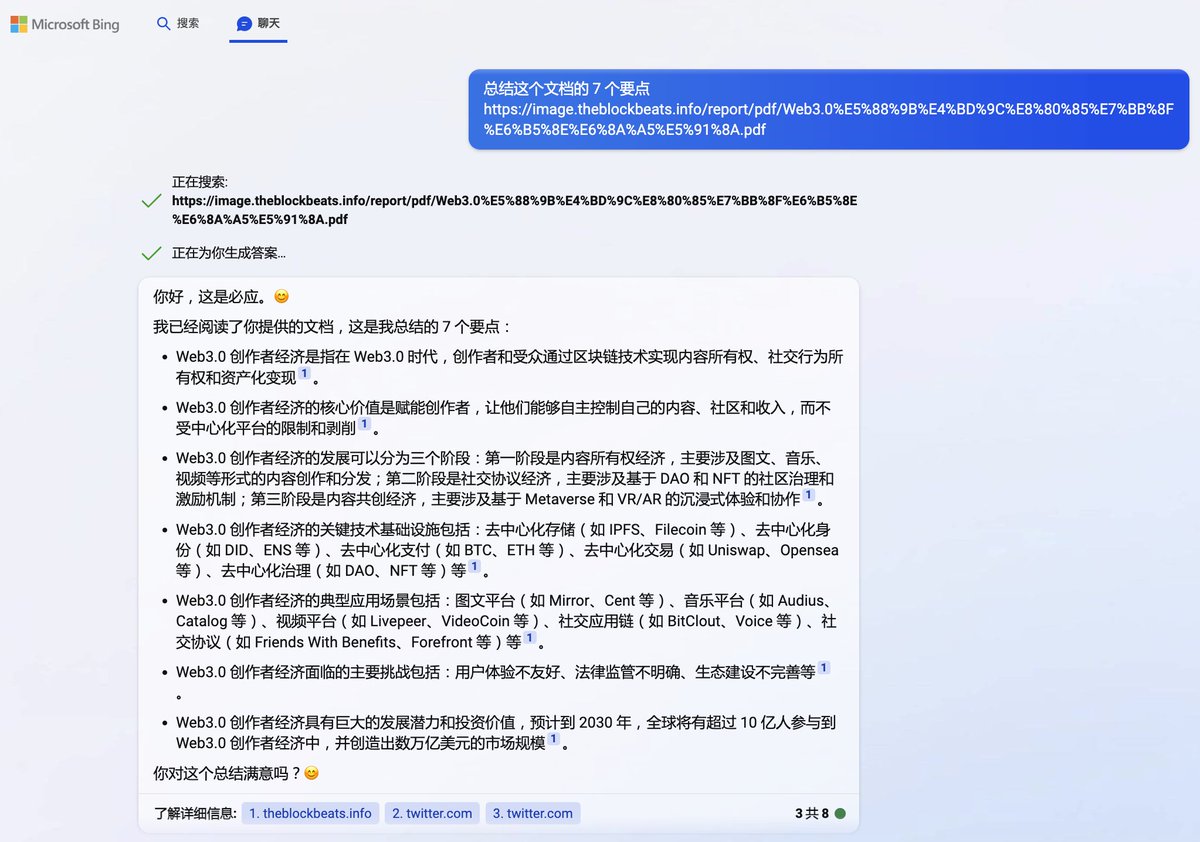
我用的 PDF 文件是《Web3.0创作者经济报告》by @BlockBeatsAsia
由于 mac 版本暂不支持 PDF 上传,于是我输入线上🔗代替。不得不说,这个总结和表达能力让我作为人类深深感受到了危机感
看到倒数第 3 条社交协议的时候发现有点不对,质问之后态度还算诚恳。btw最后一条也是瞎编的
2/10
我用的 PDF 文件是《Web3.0创作者经济报告》by @BlockBeatsAsia
由于 mac 版本暂不支持 PDF 上传,于是我输入线上🔗代替。不得不说,这个总结和表达能力让我作为人类深深感受到了危机感
看到倒数第 3 条社交协议的时候发现有点不对,质问之后态度还算诚恳。btw最后一条也是瞎编的
2/10

指定某个问题【总结音乐创作者的机会】,New Bing 回答的也不错
另外目前微软限制了一次对话最多 8 次交互,问题多的时候有点不方便,希望早日放开,增加广告版或收费版也可以接受
快速进入白名单小技巧:在注册 bing.com 时使用的微软账户,国家选为美国,3 天左右就通过了
3/10
另外目前微软限制了一次对话最多 8 次交互,问题多的时候有点不方便,希望早日放开,增加广告版或收费版也可以接受
快速进入白名单小技巧:在注册 bing.com 时使用的微软账户,国家选为美国,3 天左右就通过了
3/10

2️⃣ ChatPDF
地址 ChatPDF.com, 为了稳定使用 chatGPT, 仍然推荐使用自己的 API key,配置方法见下方引用的推文
4/10
地址 ChatPDF.com, 为了稳定使用 chatGPT, 仍然推荐使用自己的 API key,配置方法见下方引用的推文
4/10
https://twitter.com/starzqeth/status/1630036281848889344
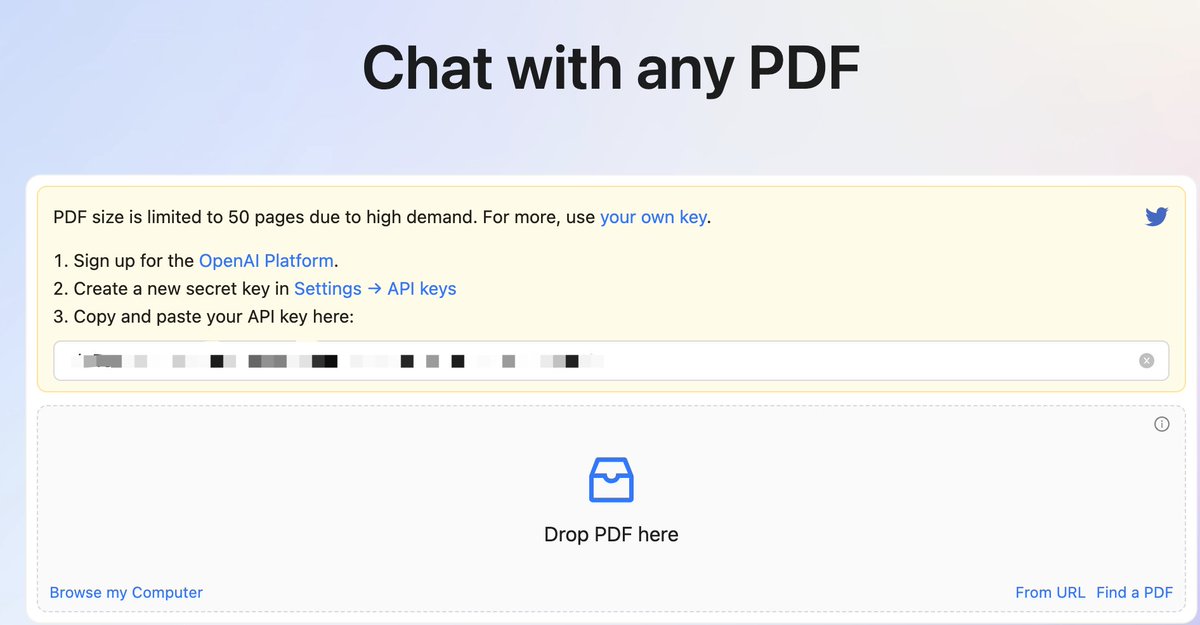
PDF 上传成功后,会自动生成总结,但的确质量不太行
5/10
5/10

ChatPDF 貌似对中文支持不太好,输入【将这份pdf总结为7个要点】后竟然报错,改为英文后正常输出
这次质量比默认的要好,但和 New Bing 相比还是云泥之别。看来 New Bing 基于的 GPT-3.5 的确要比普通的 ChatGPT 强大很多
6/10
这次质量比默认的要好,但和 New Bing 相比还是云泥之别。看来 New Bing 基于的 GPT-3.5 的确要比普通的 ChatGPT 强大很多
6/10
https://twitter.com/starzqeth/status/1624040006284365825

多问 ChatPDF 几个问题后也出现了瞎编的情况,看来目前基于 GPT 的应用都很难避免
7/10
7/10


总结一下
1. 由于使用了 GPT-3.5, New Bing 的总结能力远超 ChatPDF
2. 两者都会瞎编内容,需要小心使用
3. New Bing 限制了一次对话最多 8 次交互,问题多的时候有点不方便,希望早日放开,增加广告版或收费版也可以接受
另外我试了演示视频里的 GAP 和 lululemon Q3 财报比较,的确震撼
8/10
1. 由于使用了 GPT-3.5, New Bing 的总结能力远超 ChatPDF
2. 两者都会瞎编内容,需要小心使用
3. New Bing 限制了一次对话最多 8 次交互,问题多的时候有点不方便,希望早日放开,增加广告版或收费版也可以接受
另外我试了演示视频里的 GAP 和 lululemon Q3 财报比较,的确震撼
8/10
https://twitter.com/starzqeth/status/1623478890151960576

感兴趣的朋友可以亲自探索一下这 2 个工具,有更好的用法或者其他更好工具,也欢迎在第一条推下留言。这是一种用了之后再也回不去的体验
最后再推荐下 futurepedia 这个网站,有 1200+ AI 工具的分类和介绍,满足你的各种需求
futurepedia.io
9/10
最后再推荐下 futurepedia 这个网站,有 1200+ AI 工具的分类和介绍,满足你的各种需求
futurepedia.io
9/10

如果这条🧵对你有帮助
1. 请关注我@starzqeth,持续接收关于Web3、创作者经济、AI 和自我成长的干货内容
2. 请Retweet和Like第一条推文👇
10/10
1. 请关注我@starzqeth,持续接收关于Web3、创作者经济、AI 和自我成长的干货内容
2. 请Retweet和Like第一条推文👇
10/10
https://twitter.com/starzqeth/status/1632899880183296000
补充下,GPT 或者 LLM 出现的瞎编,Ted Jiang 称之为“精确的模糊”,可怕的点是习惯之后就会让人觉得是“正确”的,丧失辨别真伪的能力(有空分享下 Ted Jiang 这篇文章,特别有洞察 )
如何更好的使用这类 AI 工具,也是一个值得讨论的话题
如何更好的使用这类 AI 工具,也是一个值得讨论的话题
在 Web3 和 AI 的帮助下,每一位内容创作者都可以更好打造自己的品牌和 IP
如果你对以下话题感兴趣
· Web3 领域的品牌和 IP 发展
· NFT 和 AI 如何为企业、创作者和消费者带来改变
请订阅我的 newsletter, 我会定期分享案例与思考
web3brand.substack.com/?showWelcome=t…
如果你对以下话题感兴趣
· Web3 领域的品牌和 IP 发展
· NFT 和 AI 如何为企业、创作者和消费者带来改变
请订阅我的 newsletter, 我会定期分享案例与思考
web3brand.substack.com/?showWelcome=t…
• • •
Missing some Tweet in this thread? You can try to
force a refresh