基于OpenAI的Whisper的C/C++实现,完全可以离线使用。
🔗 github.com/ggerganov/whis…
- 没有外部依赖
- 不需要联网
- 内存使用率低
- 支持几乎所有的主流平台,Mac、iOS、Android、Windows、WebAssembly等
参考在 iPhone 13 设备上运行模型的视频——完全离线
基于它你可以轻松制作自己的离线语音助手应用
🔗 github.com/ggerganov/whis…
- 没有外部依赖
- 不需要联网
- 内存使用率低
- 支持几乎所有的主流平台,Mac、iOS、Android、Windows、WebAssembly等
参考在 iPhone 13 设备上运行模型的视频——完全离线
基于它你可以轻松制作自己的离线语音助手应用
之前有朋友留言问支不支持中文,支持的效果怎么样。答案是肯定的,那么效果怎么样呢?
先说明一下,在本地运行Whisper之前要先下载模型,从tiny到large,自然是体积越大效果越好。
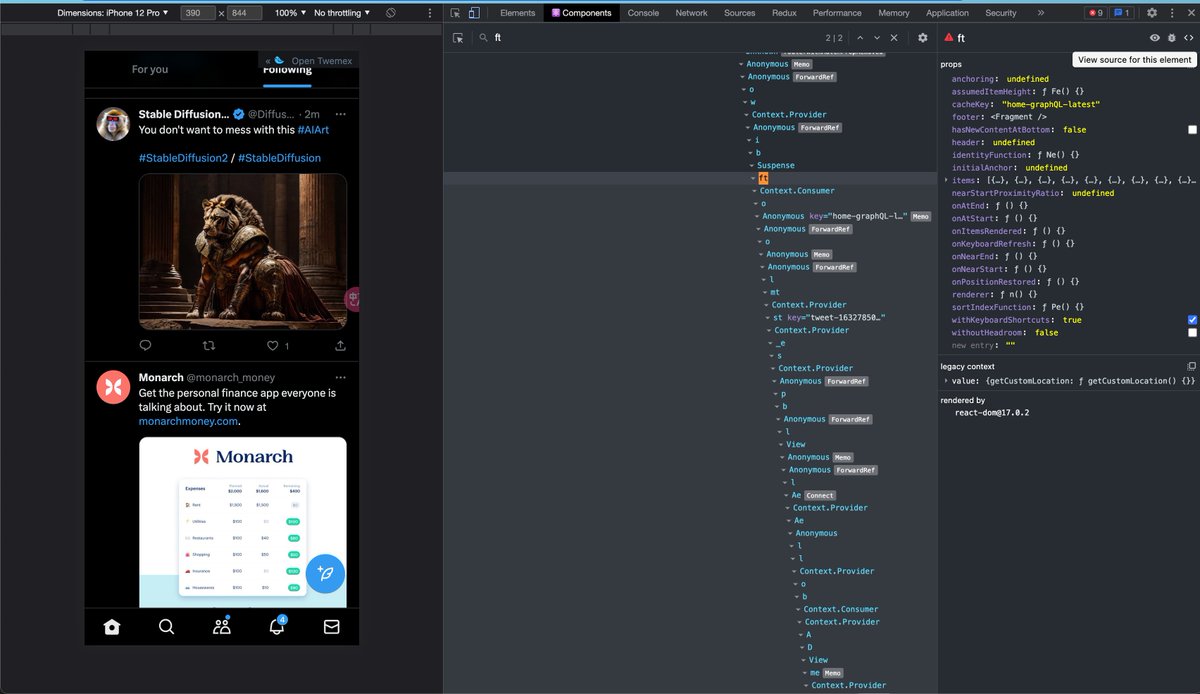
我拿王局的最新一期视频的第一分钟测试了一下,图一是base模型,图二是large,差别还是有一点的,large识别效果很好
先说明一下,在本地运行Whisper之前要先下载模型,从tiny到large,自然是体积越大效果越好。
我拿王局的最新一期视频的第一分钟测试了一下,图一是base模型,图二是large,差别还是有一点的,large识别效果很好

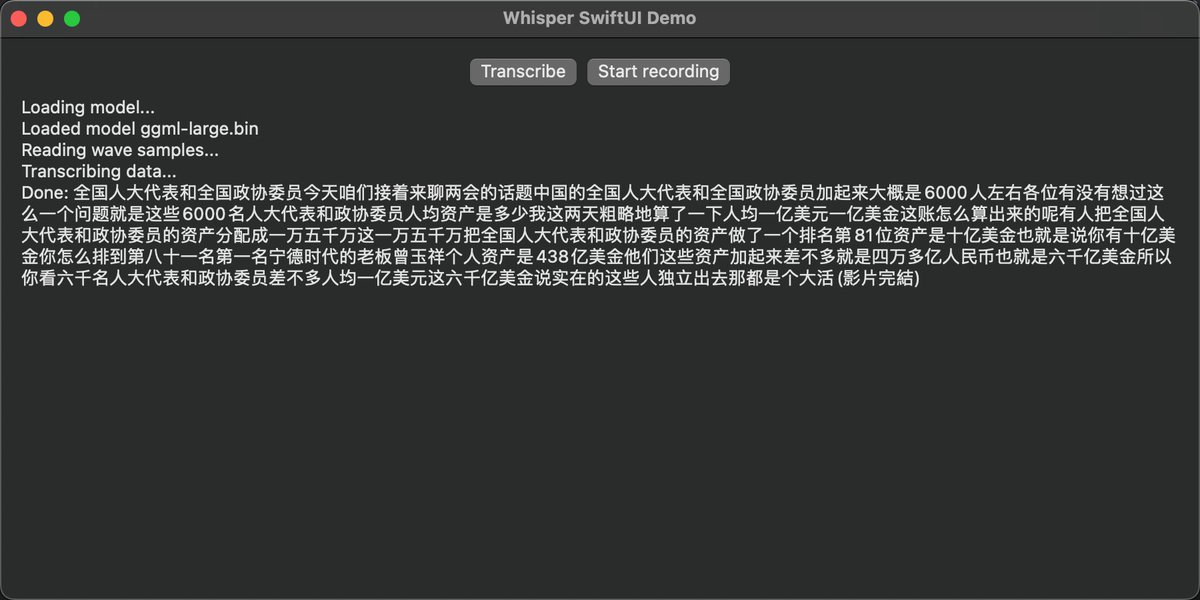

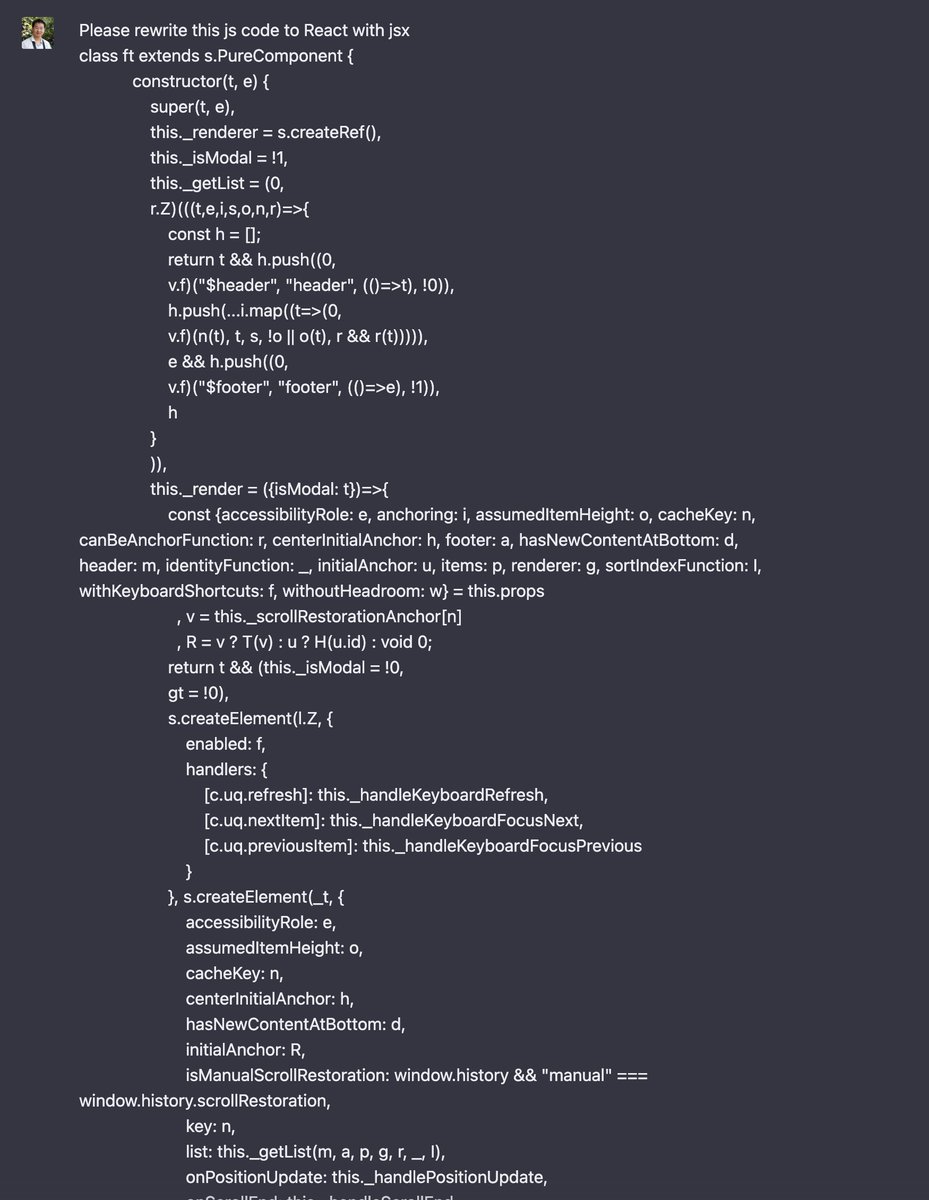
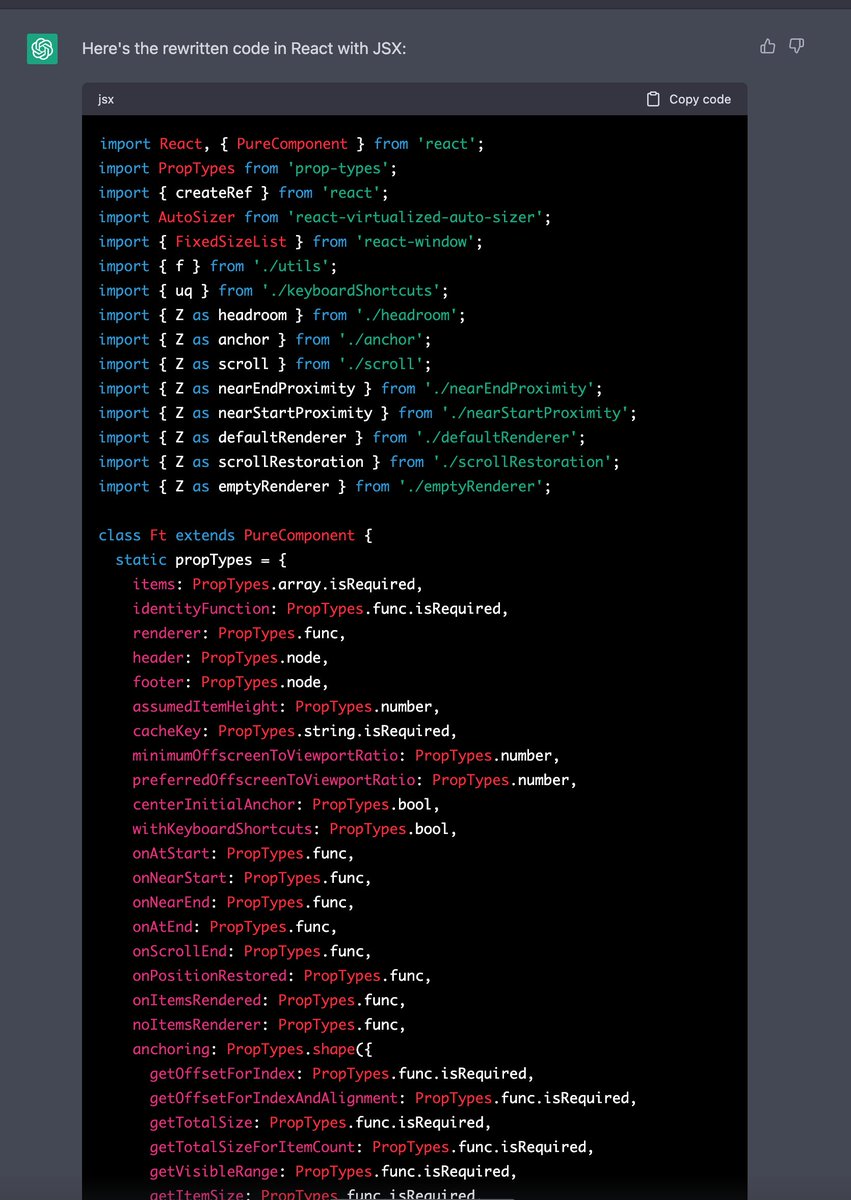
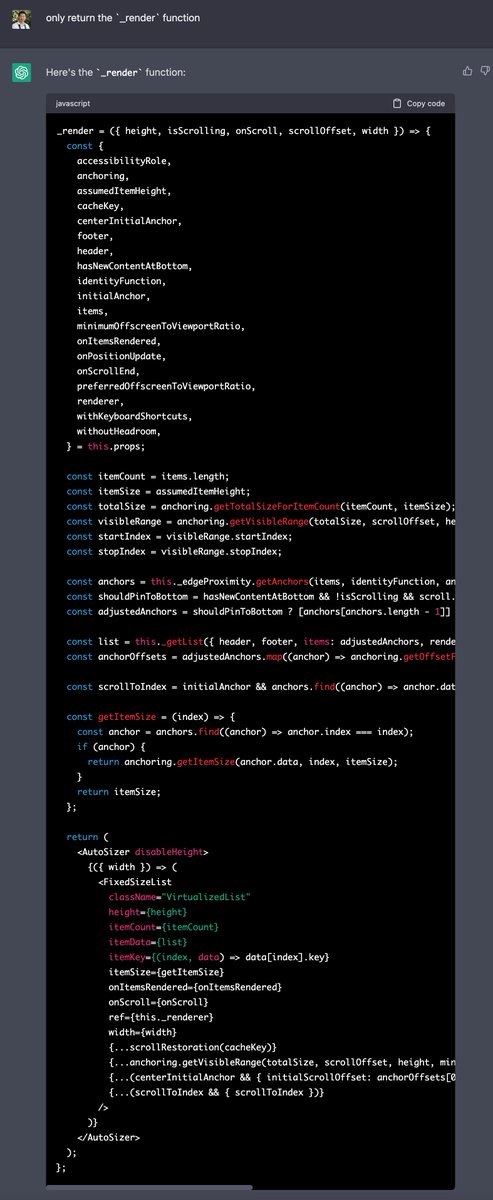
测试它的SwiftUI的那个Demo要注意
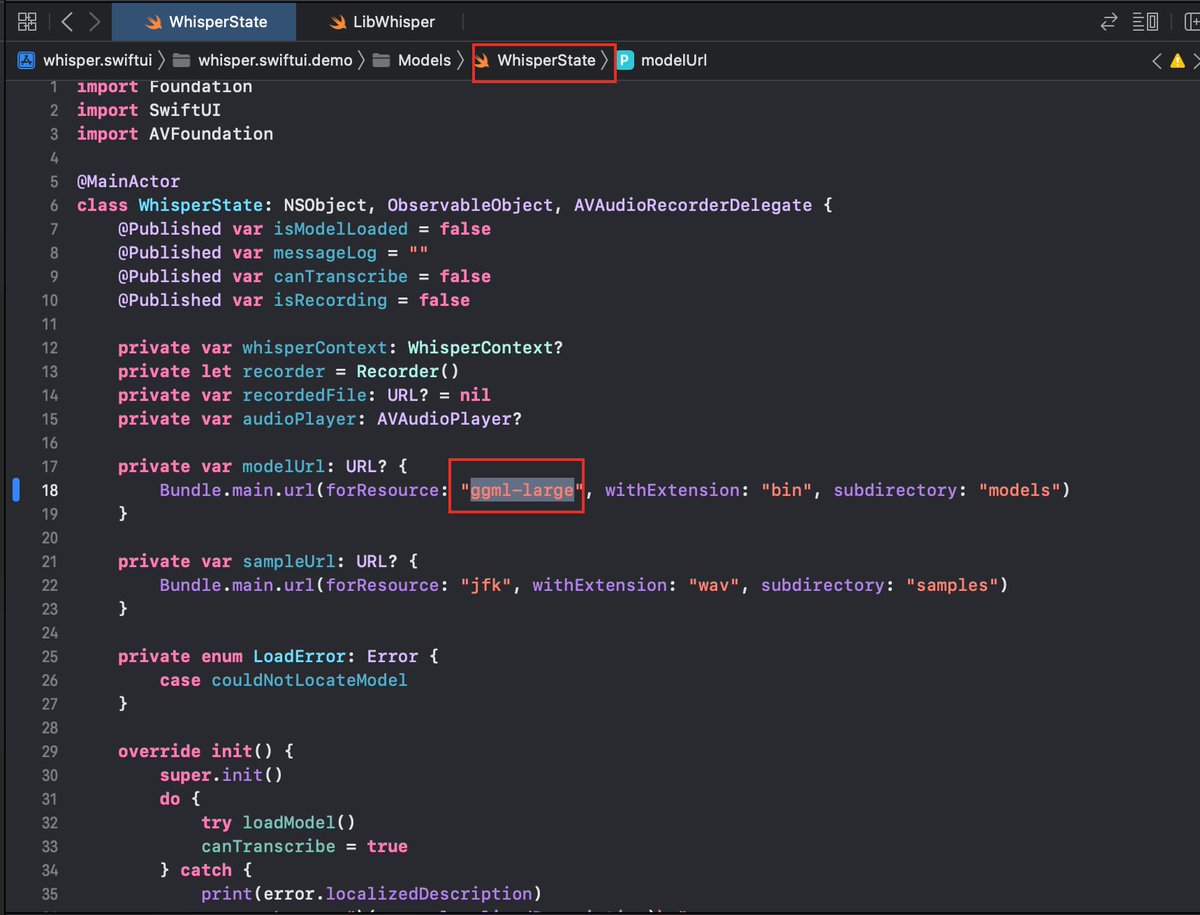
1. 先要下载好Model,然后放到SwiftUI项目的Resources/models目录下
2. WhisperState类下的模型文件名要修改成对应的模型文件
3. LibWhisper类中的”en”改成”zh”才能输出成中文结果
不建议用large测试,base就可以,Large虽然精度最高,但内存占用很高,解析速度很慢
1. 先要下载好Model,然后放到SwiftUI项目的Resources/models目录下
2. WhisperState类下的模型文件名要修改成对应的模型文件
3. LibWhisper类中的”en”改成”zh”才能输出成中文结果
不建议用large测试,base就可以,Large虽然精度最高,但内存占用很高,解析速度很慢

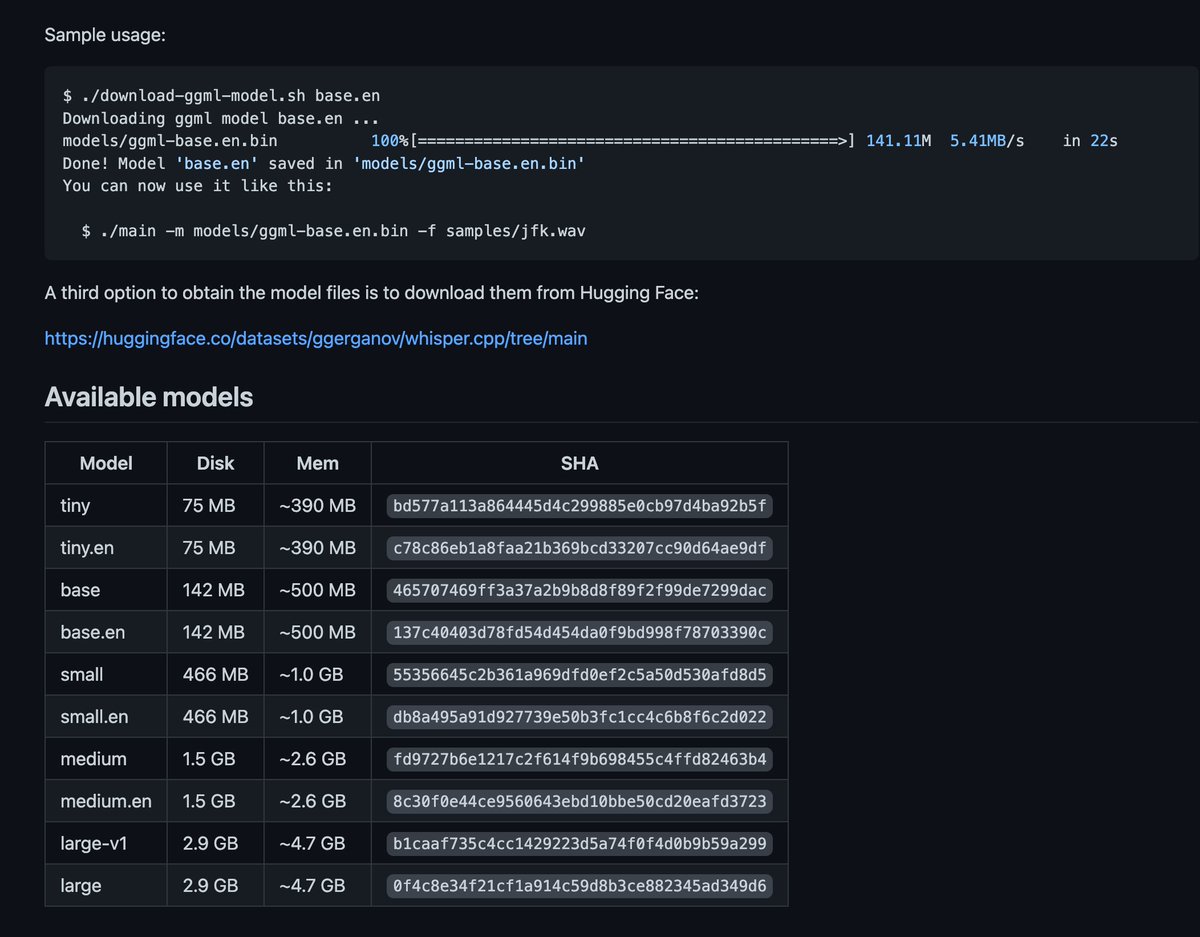
模型的安装在它的models目录下有说明:
github.com/ggerganov/whis…
终于明白为啥还是得花钱用OpenAI的Whisper API了,本地运行成本也不低,tiny或者base对中文的识别效果不怎么好,large模型的话,磁盘得占3G,内存得占5G,解析速度还慢!
github.com/ggerganov/whis…
终于明白为啥还是得花钱用OpenAI的Whisper API了,本地运行成本也不低,tiny或者base对中文的识别效果不怎么好,large模型的话,磁盘得占3G,内存得占5G,解析速度还慢!
• • •
Missing some Tweet in this thread? You can try to
force a refresh