DeepSeek-V4 拥有百万字超长上下文,在 Agent 能力、世界知识和推理性能上均实现国内与开源领域的领先。模型按大小分为两个版本:
DeepSeek-V4 拥有百万字超长上下文,在 Agent 能力、世界知识和推理性能上均实现国内与开源领域的领先。模型按大小分为两个版本:


 Ralph Wiggum 插件:让 Claude Code “通宵干活”
Ralph Wiggum 插件:让 Claude Code “通宵干活” 但有一个大问题:生成的 Slides 是死图,文字不能改,内容不能动。
但有一个大问题:生成的 Slides 是死图,文字不能改,内容不能动。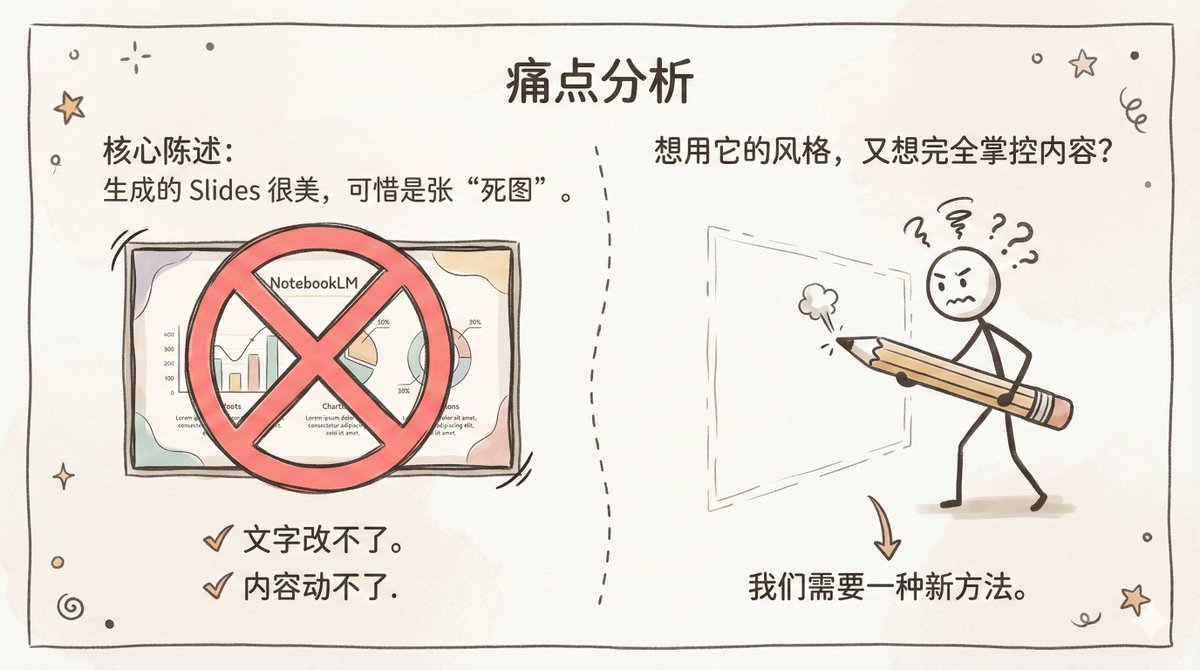
 Dynamically generate a current weather card based on a given city name. (date is optional)
Dynamically generate a current weather card based on a given city name. (date is optional) 网友作品
网友作品 
 注:图画创意原作者夏阿,只是尝试用 AI 重现
注:图画创意原作者夏阿,只是尝试用 AI 重现 
 可能有人还记得 2023 年 @DrJimFan 他们团队做的一个玩 Minecraft 的 Agent Voyager,就能把玩游戏的技能写成代码,保存起来后续使用,最终让 Agent 在 Minecraft 中做很多事。现在想想还是蛮超前的。
可能有人还记得 2023 年 @DrJimFan 他们团队做的一个玩 Minecraft 的 Agent Voyager,就能把玩游戏的技能写成代码,保存起来后续使用,最终让 Agent 在 Minecraft 中做很多事。现在想想还是蛮超前的。 Sora 或者 ChatGPT
Sora 或者 ChatGPT

 案例:解读《DeepSeek-OCR: Contexts Optical Compression》
案例:解读《DeepSeek-OCR: Contexts Optical Compression》

 另外也没办法真的 8 小时,Claude Code 会偷懒,执行一会就会自行中断,即使没用多少上下文,暂时还没解决这个问题,但是思路可以借鉴一下,如果有更好办法,欢迎留言交流。
另外也没办法真的 8 小时,Claude Code 会偷懒,执行一会就会自行中断,即使没用多少上下文,暂时还没解决这个问题,但是思路可以借鉴一下,如果有更好办法,欢迎留言交流。


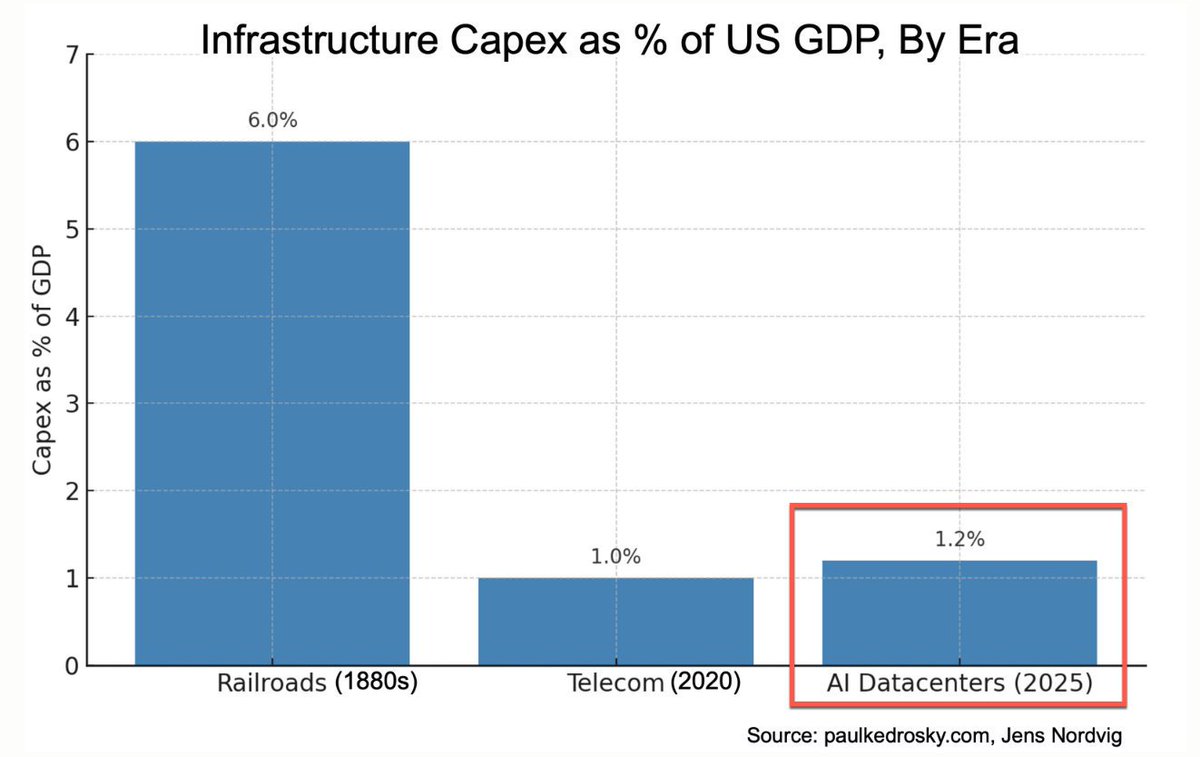
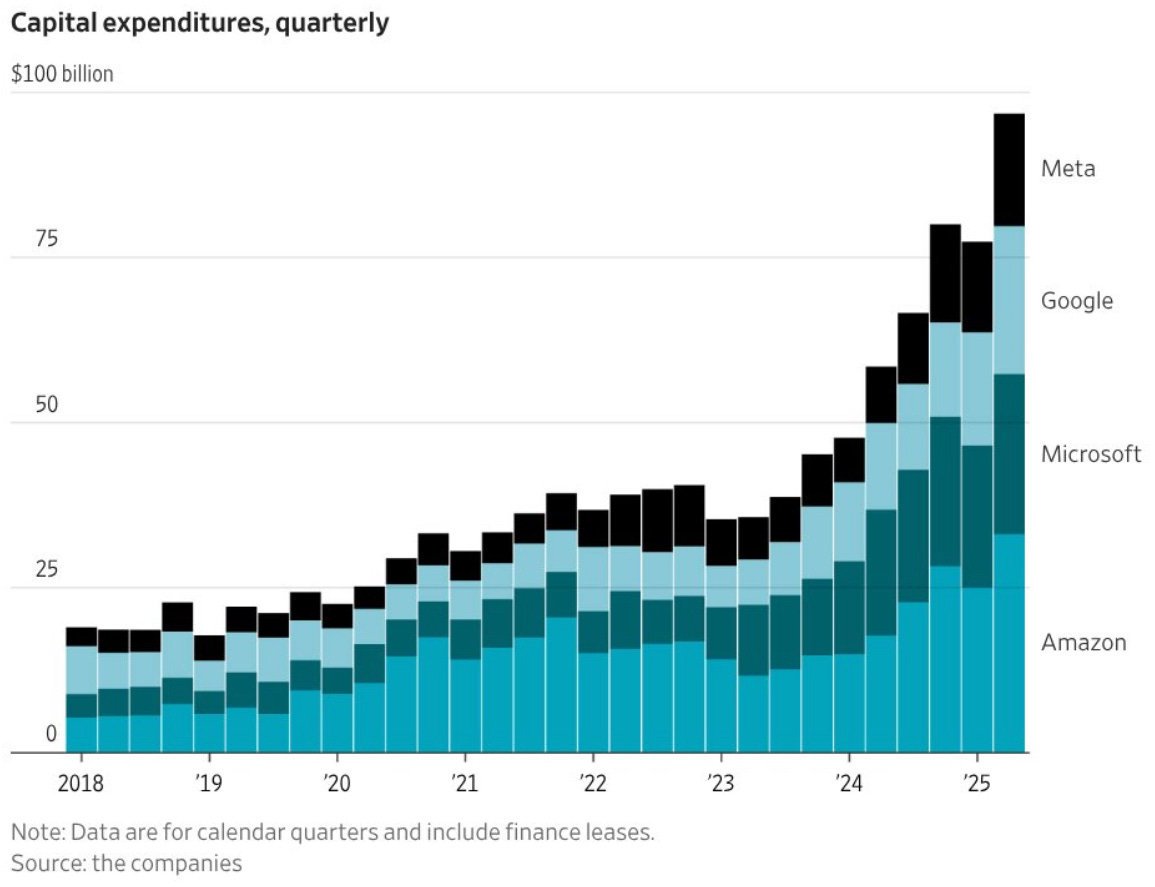 你能将这些数字置于历史背景中吗?
你能将这些数字置于历史背景中吗?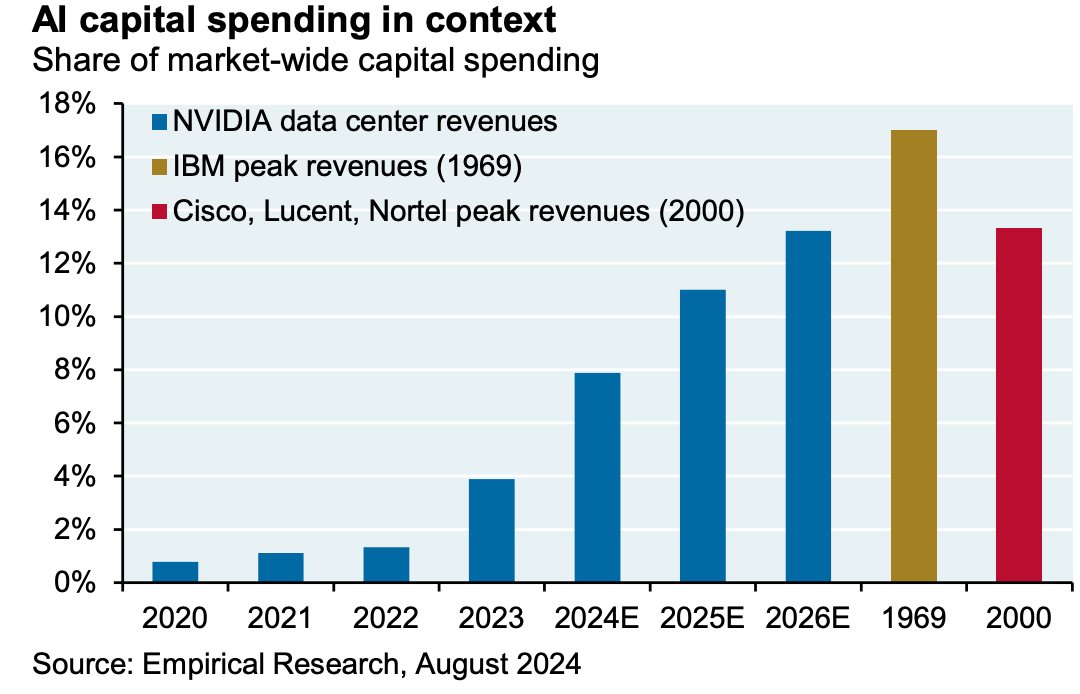



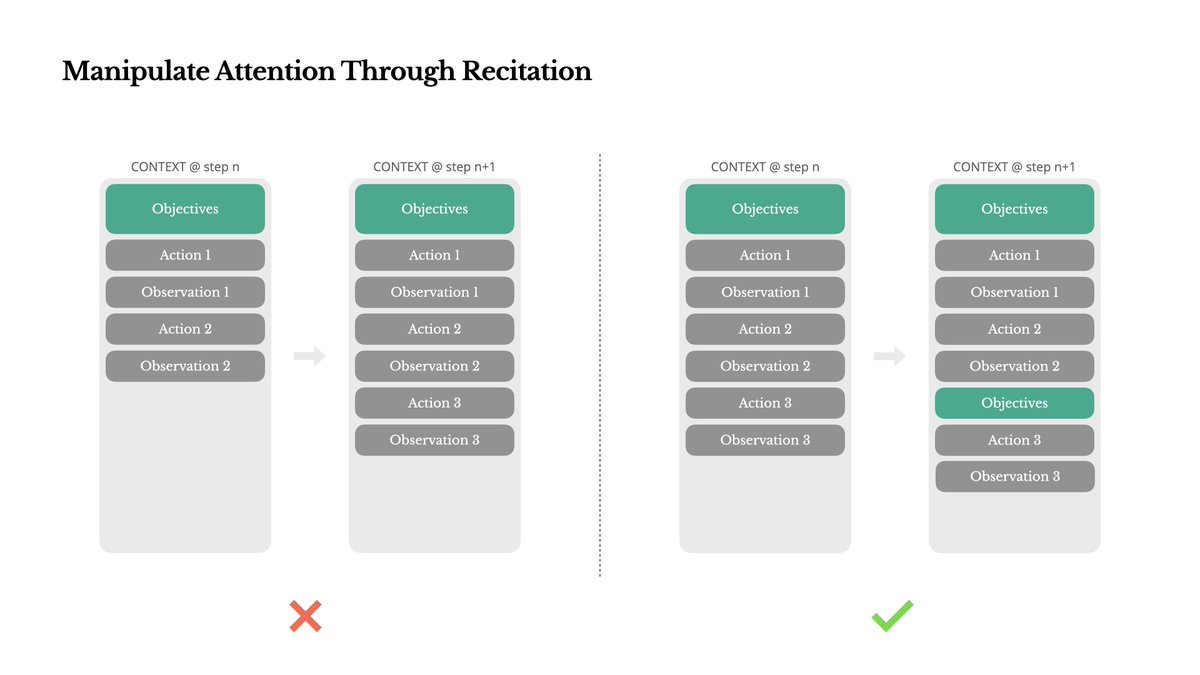
 5. 通过复述操控注意力
5. 通过复述操控注意力