
Been hands-on with the beta of Adobe's cutting-edge Generative AI tool, and I'm impressed! 🤯
Here's a taste of the power of #AdobeFirefly 🎇 and what sets it apart in the increasingly crowded world of #AI art.
Thread 🧵🎨
Here's a taste of the power of #AdobeFirefly 🎇 and what sets it apart in the increasingly crowded world of #AI art.
Thread 🧵🎨


For starters, Adobe Firefly isn't one thing. It encompasses multiple AI models. It's a portal for testing new capabilities with creators, and eventually graduating them into products like Photoshop & Premiere that creators know and love. Meeting users where they are, if you will:

If you've used any text-to-image product (e.g. Stable Diffusion or DALL-E) At first glance, Adobe Firefly will be immediately familiar.
But there's a few unique takes in Adobe's product experience.
Let's dig in...
But there's a few unique takes in Adobe's product experience.
Let's dig in...

Adobe is using a diffusion-based model (not GigaGAN as many of us suspected!), so needless to say you can get some pretty photorealistic results.


Adobe's trained this model using Adobe Stock, which means the provenance of the data is rock solid.
Adobe can't afford to alienate creators, so they have *not* trained models on Behance imagery yet, despite it being a treasure trove 💎
Will these moves woo AI art naysayers? 🤔
Adobe can't afford to alienate creators, so they have *not* trained models on Behance imagery yet, despite it being a treasure trove 💎
Will these moves woo AI art naysayers? 🤔

Firefly you can also generate text effects!
Pick a font, type in some text, describe your style and voila - a new logo for my creator brand.
I can totally see how this will be super useful inside photoshop or illustrator. No more complex layer effects to wrangle :)
Pick a font, type in some text, describe your style and voila - a new logo for my creator brand.
I can totally see how this will be super useful inside photoshop or illustrator. No more complex layer effects to wrangle :)

Adobe's Firefly UX is unique in that you can provide a prompt (which describes the contents of your scene), and then you can augment it with bunch of parameters like style, color and tone, lighting and composition. This makes it super easy to iterate:
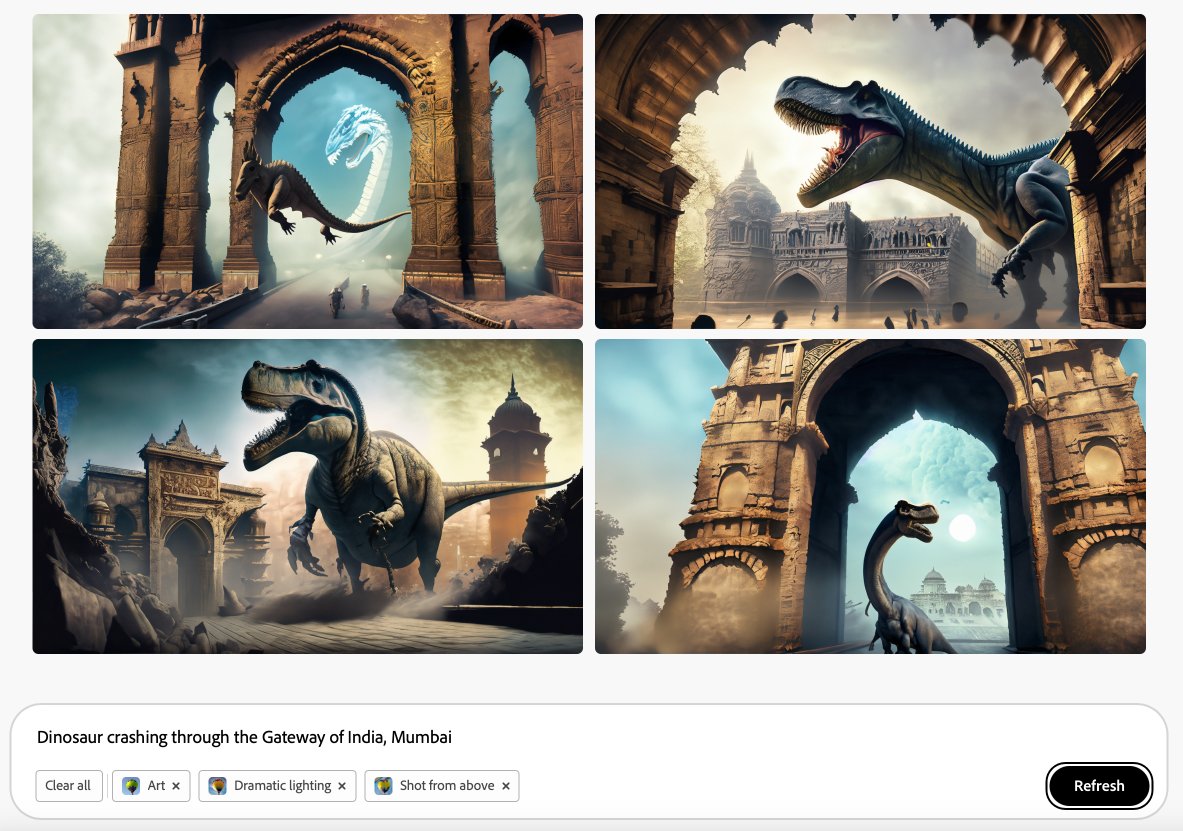
So let's say I like the the overall result, but I'm looking for a different camera angle, a slightly different aesthetic (e.g. low lighting, shot from below, cool tone). You can really dial in a look easily without futzing around with prompts. Pretty nice!


Stylized not your jam, and want to go back to a photorealistic result? As easy as clicking a button, and bam:

"Robot that toasts your bread and applies butter to it, in the style of rick and morty" produced some impressive results in Firefly:




You're probably wondering how hands look? Pretty coherent!
Even with a prompt like this:
Punjabi man in flannel shirt using AI voice dictation to create the client pitch deck while drinking espresso a cozy cabin, while wearing an Oculus VR headset, with a laptop on the table
Even with a prompt like this:
Punjabi man in flannel shirt using AI voice dictation to create the client pitch deck while drinking espresso a cozy cabin, while wearing an Oculus VR headset, with a laptop on the table

@ericsnowden made an awesome analogy about ingredients and taking decades of Adobe tech combined with these newer models to make amazing recipes. And I have to say, the dishes do look good! Case in point:


Adobe will be expanding access gradually -- so it won't exactly be a free-for-all. During the beta period, there are some noteworthy limitations worth being aware of -- critically commercial use is not allowed.
So what do you think of Adobe's entry? Share your thoughts below.
So what do you think of Adobe's entry? Share your thoughts below.

That's a wrap! If you enjoyed this deep dive on Adobe Firefly (adobe.com/firefly):
- RTing the thread below to share with your audience
- Follow @bilawalsidhu to stay tuned for more creative tech magic
- Subscribe to get these right to your inbox: creativetechnologydigest.substack.com
- RTing the thread below to share with your audience
- Follow @bilawalsidhu to stay tuned for more creative tech magic
- Subscribe to get these right to your inbox: creativetechnologydigest.substack.com
https://twitter.com/227528138/status/1638172373244411906
• • •
Missing some Tweet in this thread? You can try to
force a refresh







