How can robots acquire fine-grained manipulation skills?
Introducing ACT: Action Chunking with Transformers 🤖
Key idea: Imitation, but predict actions in chunks instead of one at a time.
Here are results with only ~15min of demonstrations, running on low-cost arms:
Introducing ACT: Action Chunking with Transformers 🤖
Key idea: Imitation, but predict actions in chunks instead of one at a time.
Here are results with only ~15min of demonstrations, running on low-cost arms:
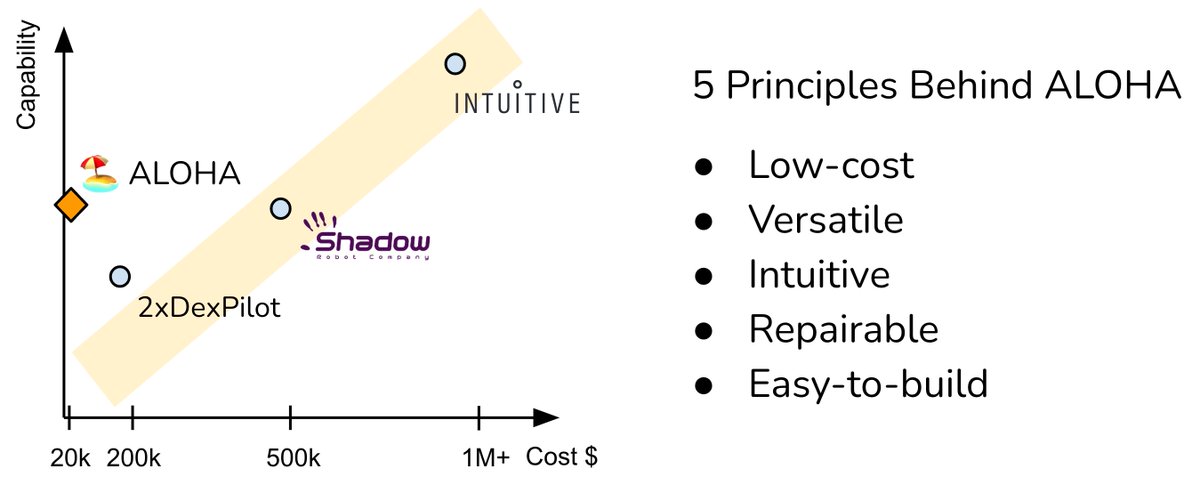
In case you missed ALOHA 🏖, the hardware we use for all these experiments, here is the thread!
https://twitter.com/tonyzzhao/status/1640393026341322754
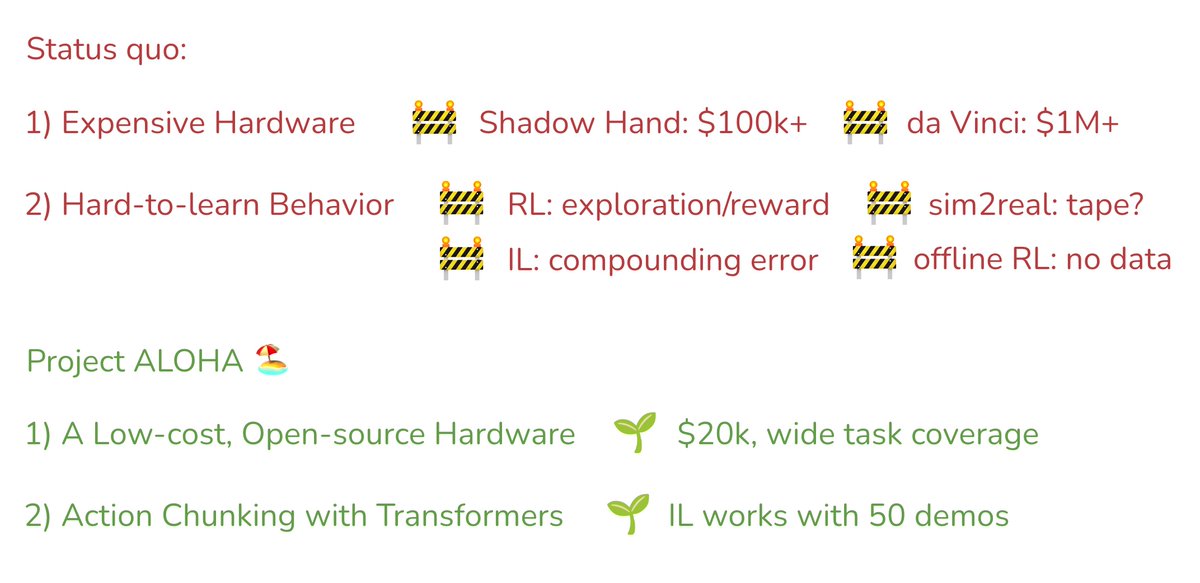
Fine manipulation is difficult: either from RL, Sim2Real, or Imitation.
- Hard exploration and sparse reward
- Large Sim2Real gap
- Compounding error for BC
- No large dataset
We introduce three important design choices behind ACT, an efficient imitation learning method:
- Hard exploration and sparse reward
- Large Sim2Real gap
- Compounding error for BC
- No large dataset
We introduce three important design choices behind ACT, an efficient imitation learning method:
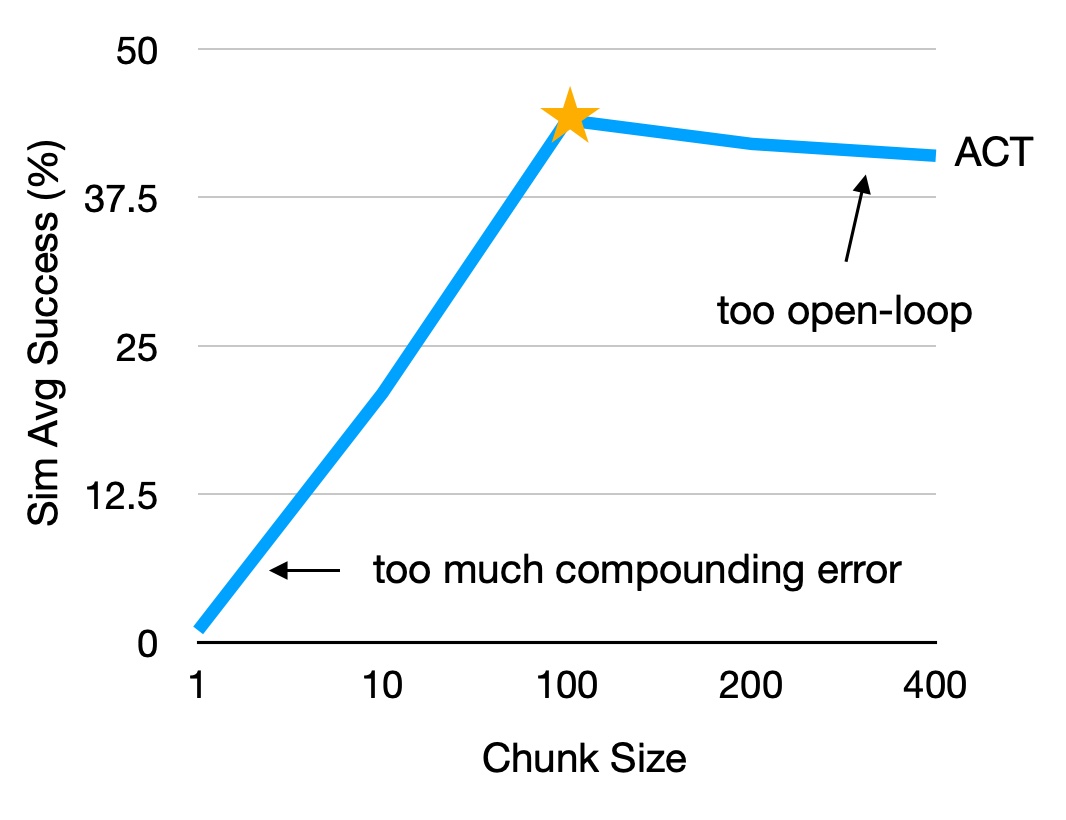
(1) Predict action sequence
Standard BC predicts one action at a time, while a fine manipulation task can have >1000 steps easily.
Predicting action in chunks slows down compounding error, and can better model non-stationary human behavior.
Standard BC predicts one action at a time, while a fine manipulation task can have >1000 steps easily.
Predicting action in chunks slows down compounding error, and can better model non-stationary human behavior.
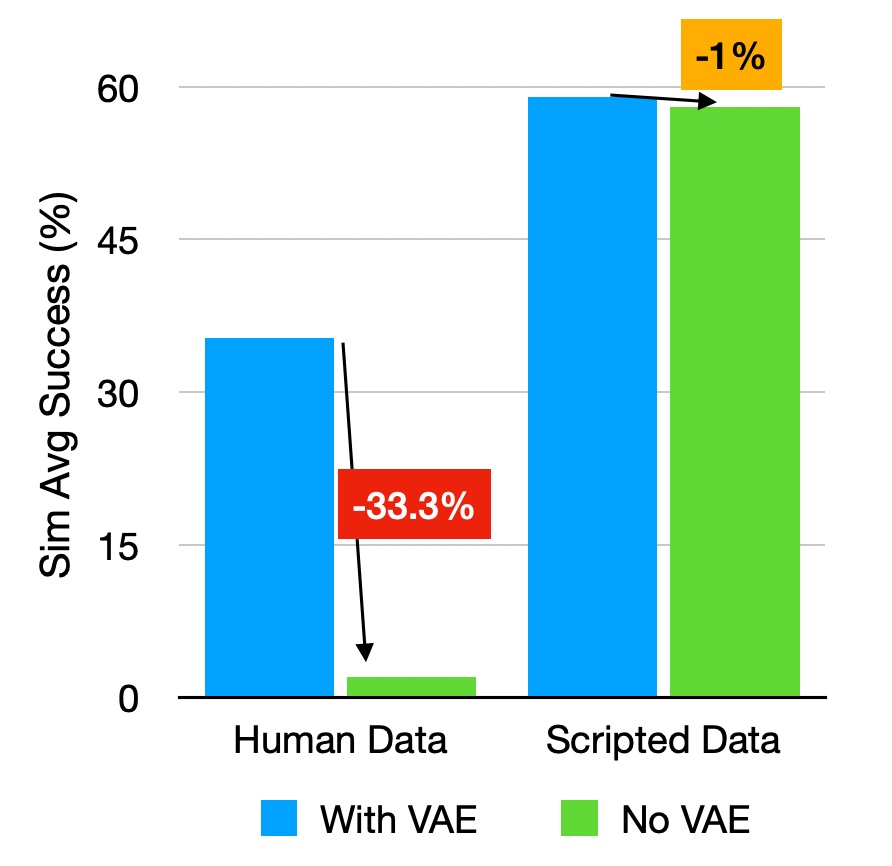
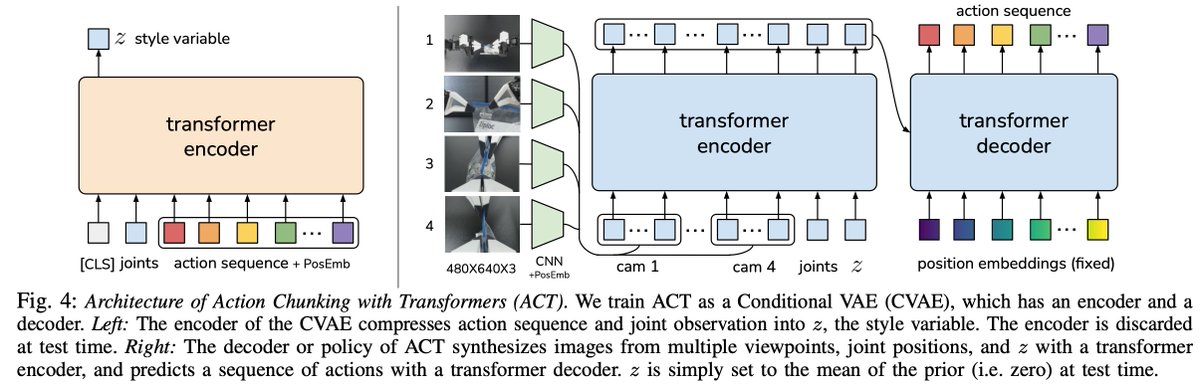
(2) Generative model policy
The policy is trained as the decoder of a VAE, reconstructing action chunks from latent z, 4 RGB images, and proprioception.
Intuitively, z extracts the “style” of the action chunk.
This is crucial when learning from human demos.
The policy is trained as the decoder of a VAE, reconstructing action chunks from latent z, 4 RGB images, and proprioception.
Intuitively, z extracts the “style” of the action chunk.
This is crucial when learning from human demos.
(3) Transformer
We modernize the VAE by using a BERT-like encoder and a DETR-like decoder, training end-to-end from scratch.
This transformer architecture benefits more from chunking than ConvNets and non-parametric methods.
We modernize the VAE by using a BERT-like encoder and a DETR-like decoder, training end-to-end from scratch.
This transformer architecture benefits more from chunking than ConvNets and non-parametric methods.
With all above, ACT obtains 64%, 96%, 84%, 92% success for 4 tasks shown, with objects randomized along the 15 cm line.
It does not just memorize the training data, and is able to react to external disturbances:
It does not just memorize the training data, and is able to react to external disturbances:
It is also robust to a certain level of distractor objects:
Similar to ALOHA, we open source ACT together with 2 simulated environments for reproducibility. You can find it in the project website: tonyzhaozh.github.io/aloha/
We hope ALOHA+ACT would be a helpful resource towards advancing fine-grained manipulation!
We hope ALOHA+ACT would be a helpful resource towards advancing fine-grained manipulation!
Personally, this is a challenging project to work on, spanning from hardware to ML.
It would certainly not be possible without my amazing advisor @chelseabfinn and collaboration from @svlevine @Vikashplus!
It would certainly not be possible without my amazing advisor @chelseabfinn and collaboration from @svlevine @Vikashplus!
• • •
Missing some Tweet in this thread? You can try to
force a refresh