
How to RLHF #LLAMA if you don't have hundreds of GPUS? Do it in a parameter-efficient way.
I'm happy to finally share our parameter-efficient fine-tuning #PEFT survey! It took quite a bit more time to make than I expected, but I feel good about the result
arxiv.org/abs/2303.15647
I'm happy to finally share our parameter-efficient fine-tuning #PEFT survey! It took quite a bit more time to make than I expected, but I feel good about the result
arxiv.org/abs/2303.15647
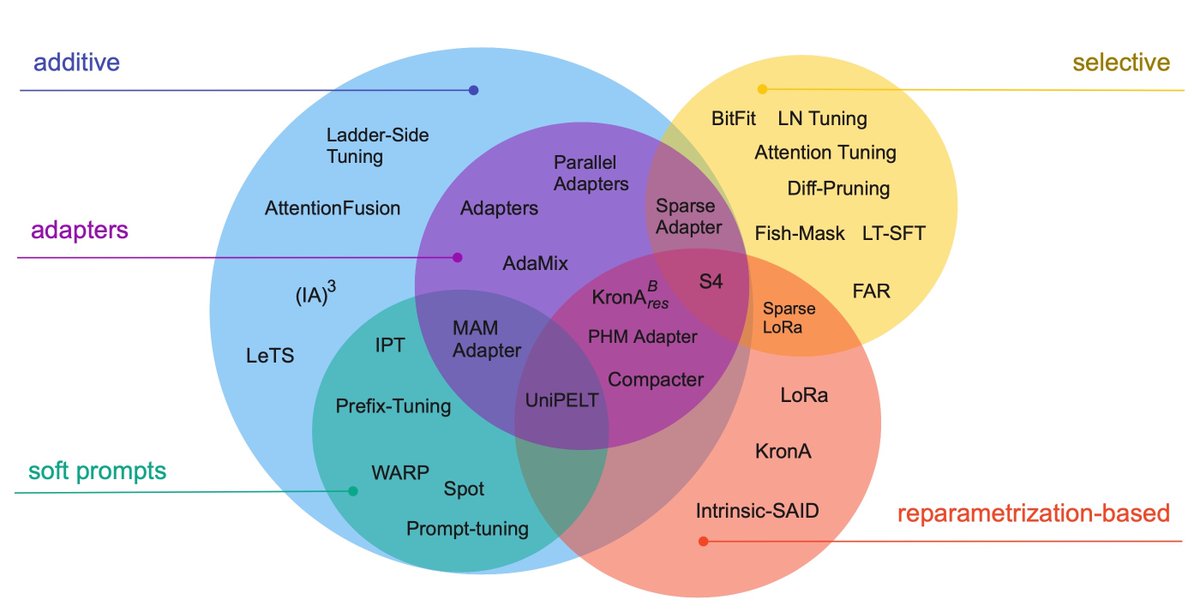
PEFT methods can target several things: storage efficiency, multitask inference efficiency, and memory efficiency are among them. We are interested in the case of fine-tuning large models, so memory efficiency is a must.
We distill over 40 PEFT papers, provide a taxonomy and comparison of 30 methods, and describe 20 methods in detail (with pseudocode!).

I feel like everyone knows about Adapters, BitFit, and LoRa, but there are even better methods out there! In the last two years, low-rank methods took off.
Compacter and KronA use a more rank-efficient way to get large matrices. Kronecker product is the new matmul for PEFT.
Compacter and KronA use a more rank-efficient way to get large matrices. Kronecker product is the new matmul for PEFT.

We dive into the details of 20 different PEFT methods in the paper. Still, because we understand not everyone has the time to read the full 15 pages, we highlight a one-sentence description of each method and provide a pseudocode!

Finally, parameter efficiency is... ugh, complicated. Different people see it differently: number of trainable parameters, number of updated parameters, and rank of the update. Also, it seems like the larger models get, the fewer parameters you need to fine-tune them.

I hope this paper helps people learn more about PEFT and highlight some of the amazing methods I think have been overlooked.
Joint work with @arumshisky and @VijetaDeshpande
@edwardjhu @neilhoulsby @KarimiRabeeh @blester125 @XiangLisaLi2 @ArmenAgha @liu_haokun @Yaqing_Wang @demi_guo_ @yuning_pro @yilin_sung @jiaao_chen Comments welcome!
• • •
Missing some Tweet in this thread? You can try to
force a refresh








