
 Why can't we use regular LoRA for pre-training? Because it only does optimization in a small low-rank subspace of the model parameters. It is enough for fine-tuning, but you don't want to have rank restrictions during pre-training.
Why can't we use regular LoRA for pre-training? Because it only does optimization in a small low-rank subspace of the model parameters. It is enough for fine-tuning, but you don't want to have rank restrictions during pre-training.

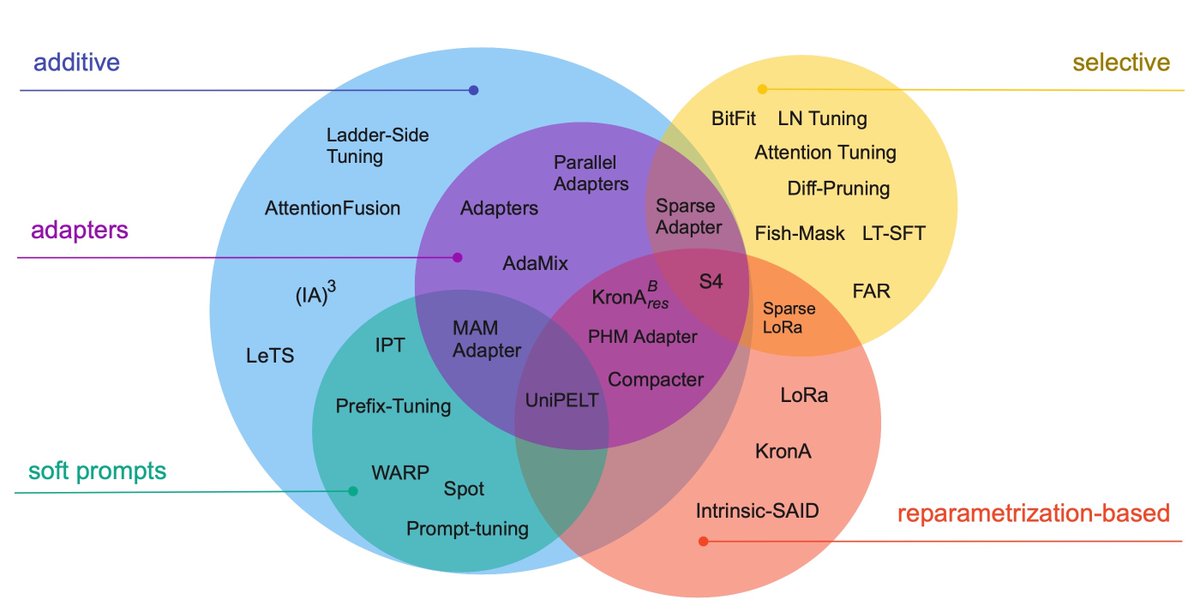 PEFT methods can target several things: storage efficiency, multitask inference efficiency, and memory efficiency are among them. We are interested in the case of fine-tuning large models, so memory efficiency is a must.
PEFT methods can target several things: storage efficiency, multitask inference efficiency, and memory efficiency are among them. We are interested in the case of fine-tuning large models, so memory efficiency is a must.