🤖Generative Agents🤖
Last week, Park et all released “Generative Agents”, a paper simulating interactions between tens of agents
We gave it a close read, and implemented one of the novel components it introduced: a long-term, reflection-based memory system
🧵
Last week, Park et all released “Generative Agents”, a paper simulating interactions between tens of agents
We gave it a close read, and implemented one of the novel components it introduced: a long-term, reflection-based memory system
🧵


If you haven’t read the paper, you absolutely should
Link: arxiv.org/abs/2304.03442
"We demonstrate through ablation that the components of our agent architecture—observation, planning, and reflection—each contribute critically to the believability of agent behavior"
Link: arxiv.org/abs/2304.03442
"We demonstrate through ablation that the components of our agent architecture—observation, planning, and reflection—each contribute critically to the believability of agent behavior"
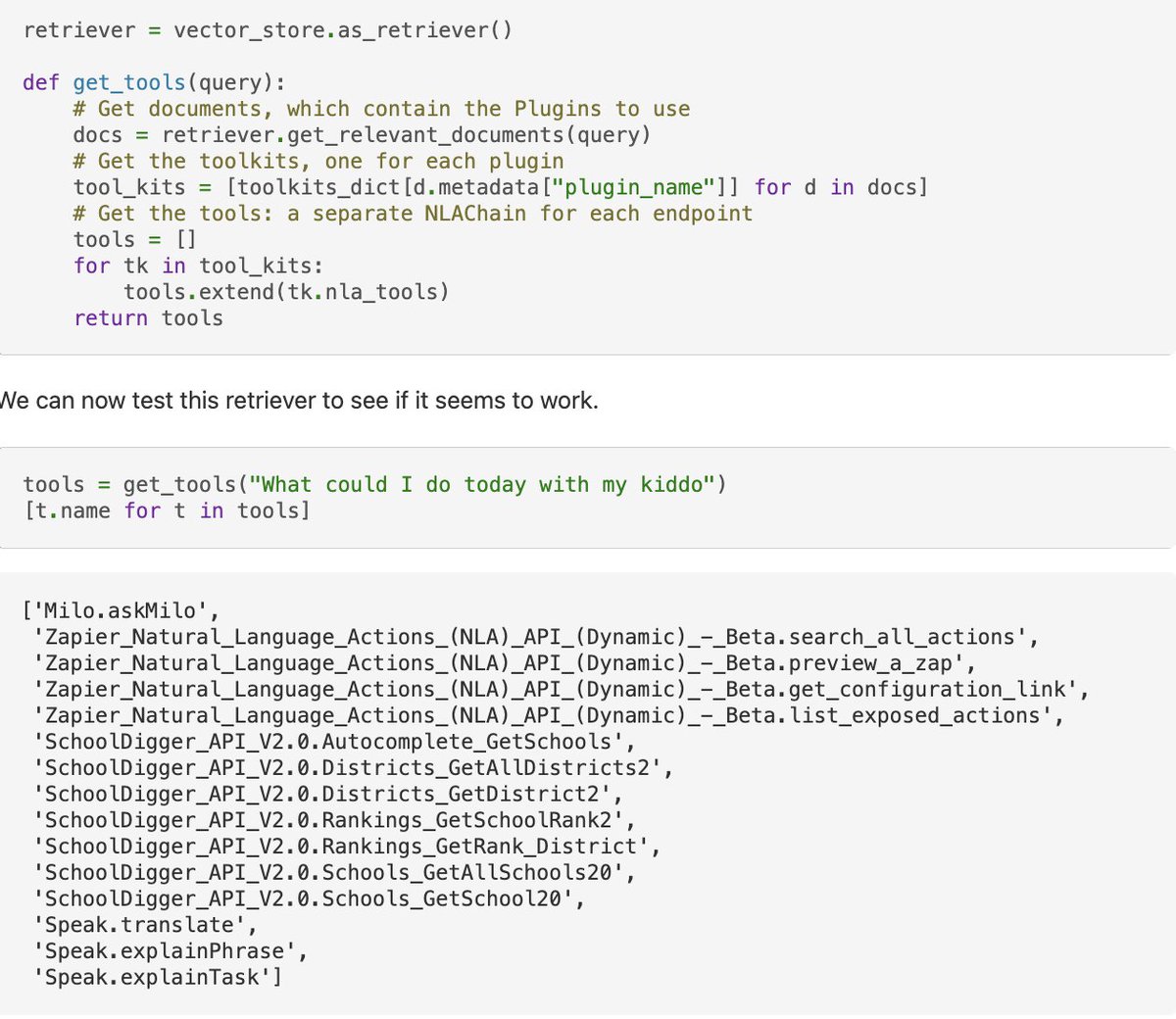
One of the novel components was a "architecture that makes it possible for generative agents to remember, retrieve, reflect, interact with other agents" - this is what we tried to recreate
Notebook here: python.langchain.com/en/latest/use_…
Notebook here: python.langchain.com/en/latest/use_…
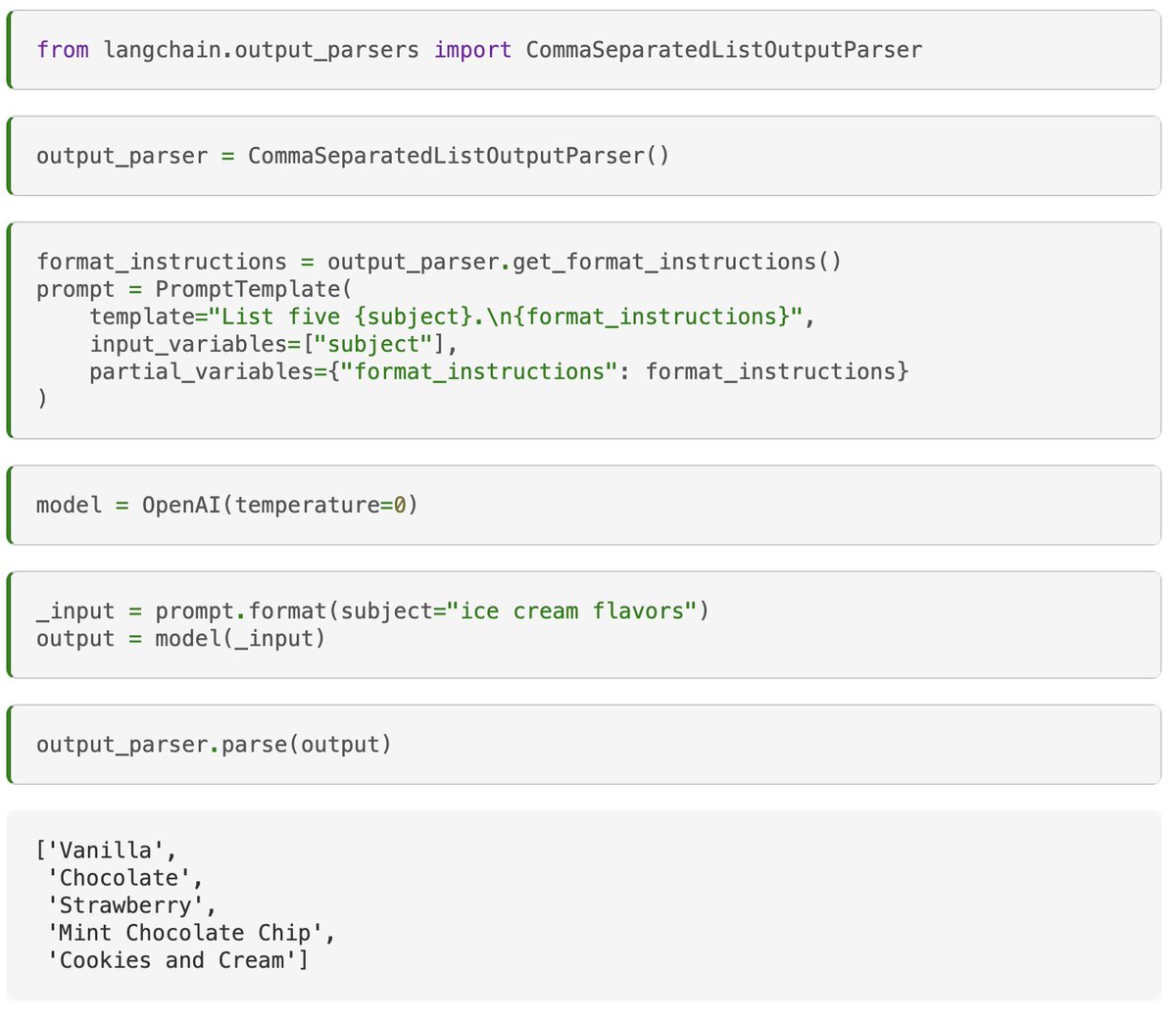
As shown below, there are a lot of parts. Two notable things:
🪞a reflection step
🎊a retrieval step
The reflections contribute to the agent's memory stream, which is then retrieved and used to act
🪞a reflection step
🎊a retrieval step
The reflections contribute to the agent's memory stream, which is then retrieved and used to act
Lets talk about retrieval first. We’ve introduced a lot of different retrievers over the past few weeks, how does the one used in this paper compare?
It can essentially be viewed as a "Time Weighted VectorStore Retriever" - a retriever than combines recency with relevance
It can essentially be viewed as a "Time Weighted VectorStore Retriever" - a retriever than combines recency with relevance
As such, we implemented a standalone TimeWeightedVectorStoreRetriever in LangChain
You can see below that you can specify a decay rate to adjust between recency and relevancy
Docs: python.langchain.com/en/latest/modu…
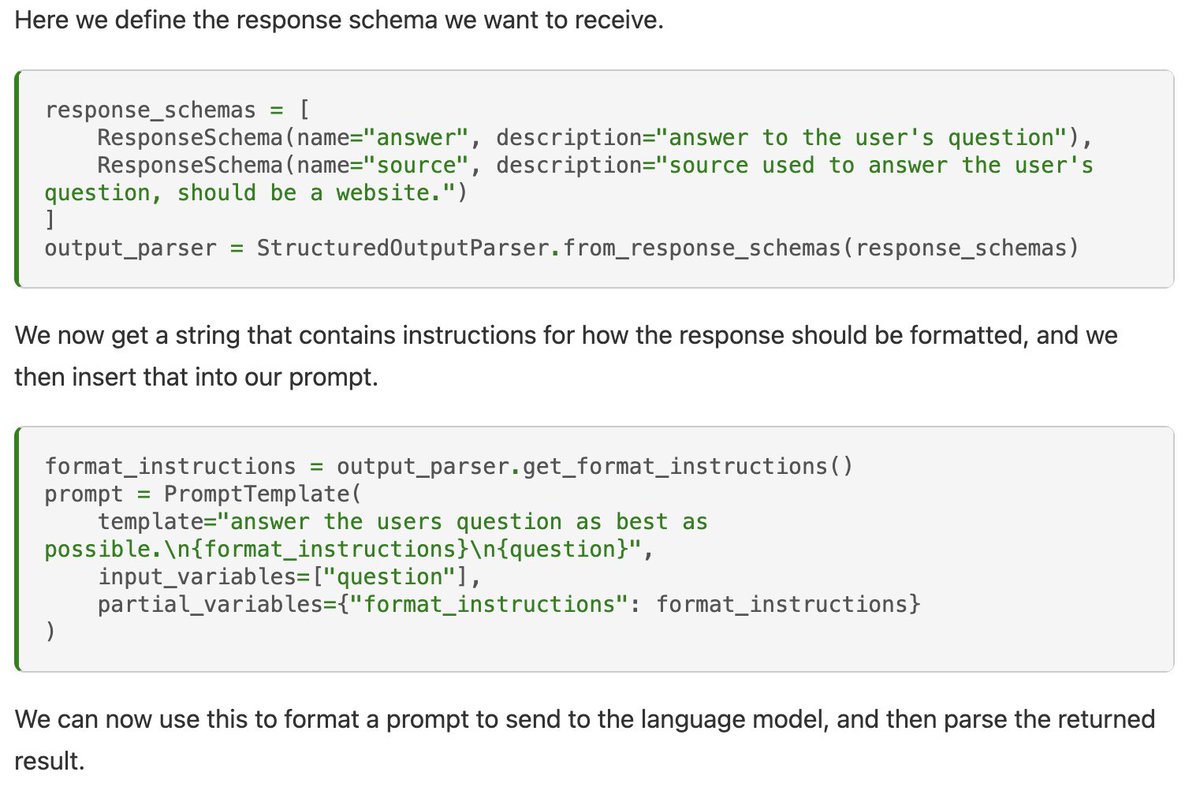
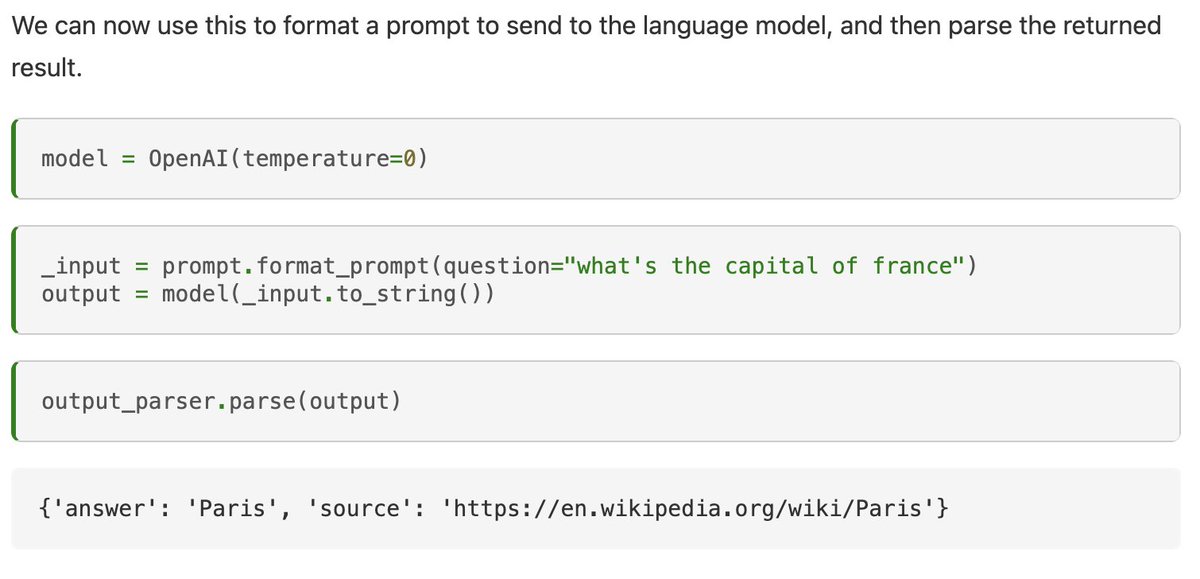
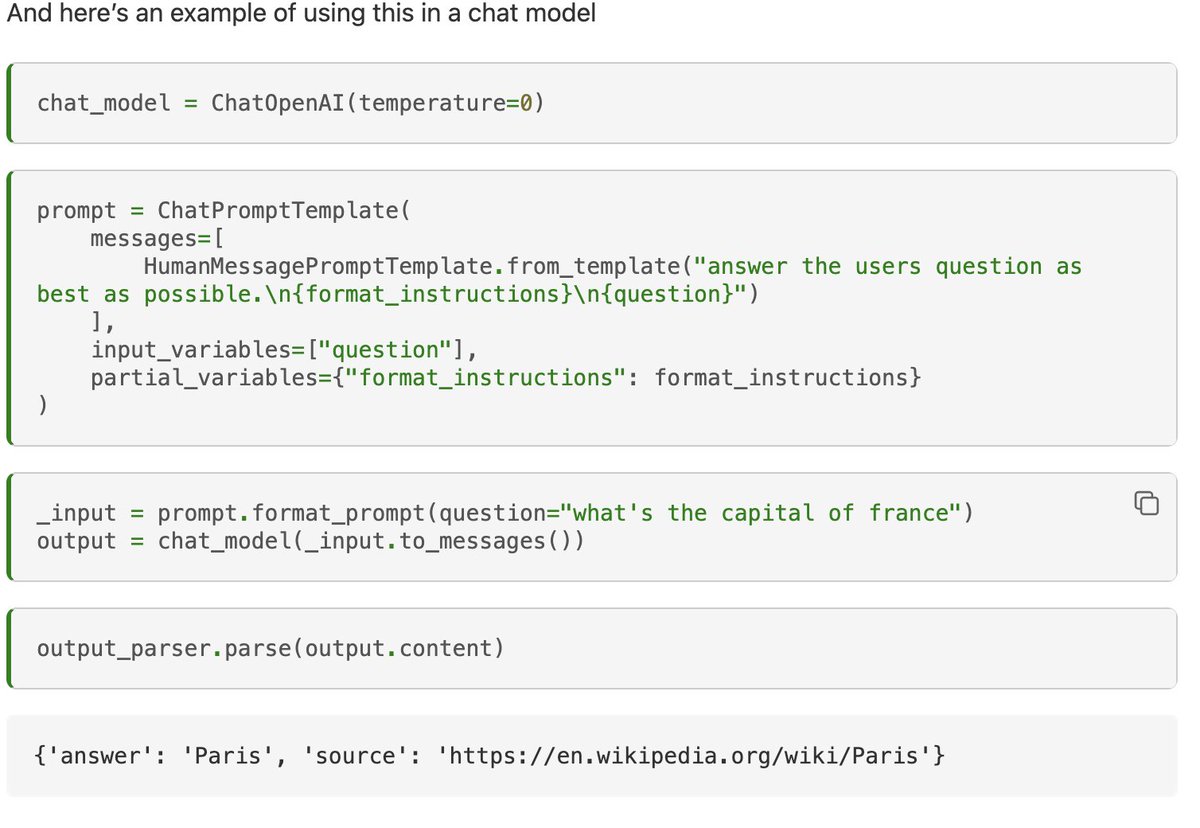
So now that we have this retriever, how is it used in memory?
You can see below that you can specify a decay rate to adjust between recency and relevancy
Docs: python.langchain.com/en/latest/modu…
So now that we have this retriever, how is it used in memory?


There are two key methods: `add_memory` and `summarize_related_memories`
When an agent makes an observation, it stores the memory:
1. a LLM scores the memory’s importance (1 for mundane, 10 for poignant)
2. Observation and importance are stored within the retrieval system
When an agent makes an observation, it stores the memory:
1. a LLM scores the memory’s importance (1 for mundane, 10 for poignant)
2. Observation and importance are stored within the retrieval system
When an agent responds to an observation:
1. Generates query(s) for retriever, which fetches documents based on salience, recency, and importance.
2. Summarizes the retrieved information
3. Updates the last_accessed_time for the used documents.
1. Generates query(s) for retriever, which fetches documents based on salience, recency, and importance.
2. Summarizes the retrieved information
3. Updates the last_accessed_time for the used documents.
So let’s now see this in action! We can simulate what happens by feeding observations to the agent and seeing how the summary of the agent is updated over time
Here we do a simple update of only a few observations
Here we do a simple update of only a few observations


We can take this to the extreme even more and update with ~20 or so observations (a full day’s worth)
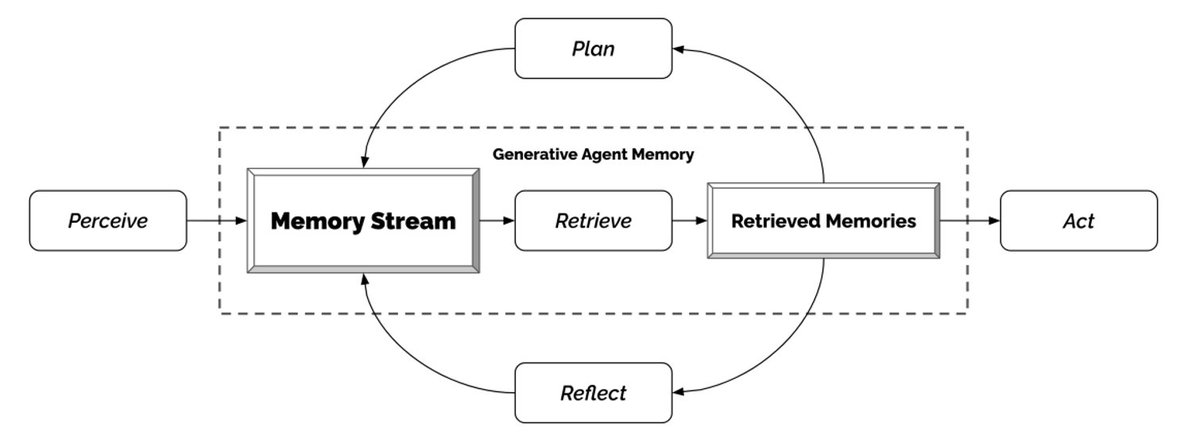
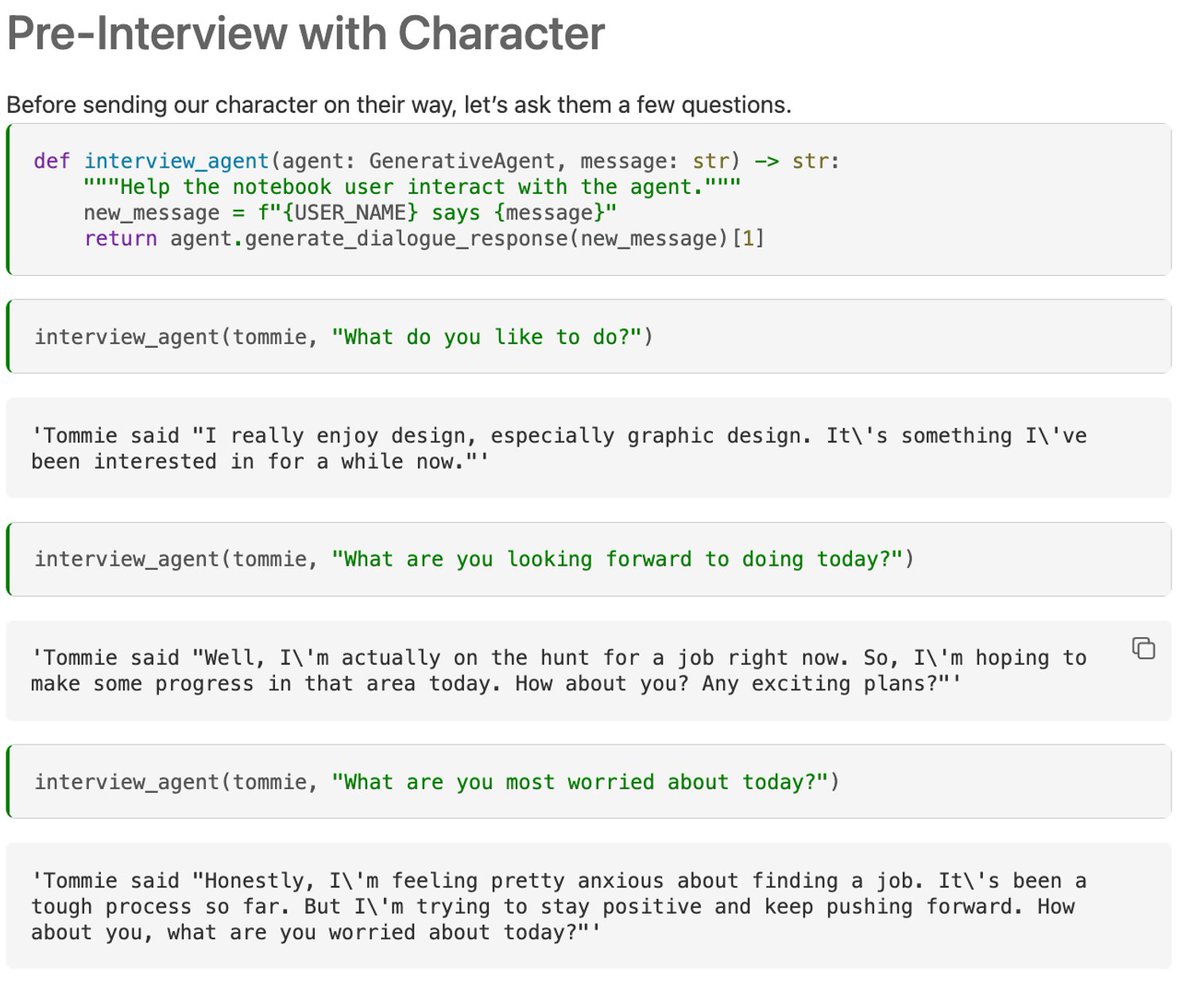
We can then “interview” the agent before and after the day - notice the change in the agent’s responses!
We can then “interview” the agent before and after the day - notice the change in the agent’s responses!

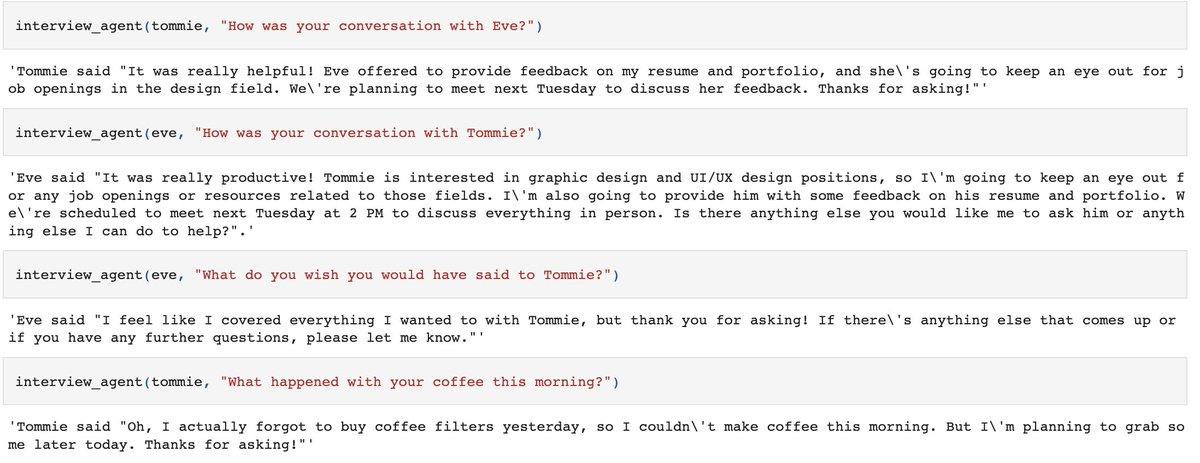
Finally, we can create a simulation of two agents talking to each other.
This is a far cry from the ~20 or so agents the paper simulated, but it's still interesting to see the conversation + interview them before and after
This is a far cry from the ~20 or so agents the paper simulated, but it's still interesting to see the conversation + interview them before and after


• • •
Missing some Tweet in this thread? You can try to
force a refresh