
 🧠The idea of memory is tantalizing, but also really vague
🧠The idea of memory is tantalizing, but also really vague


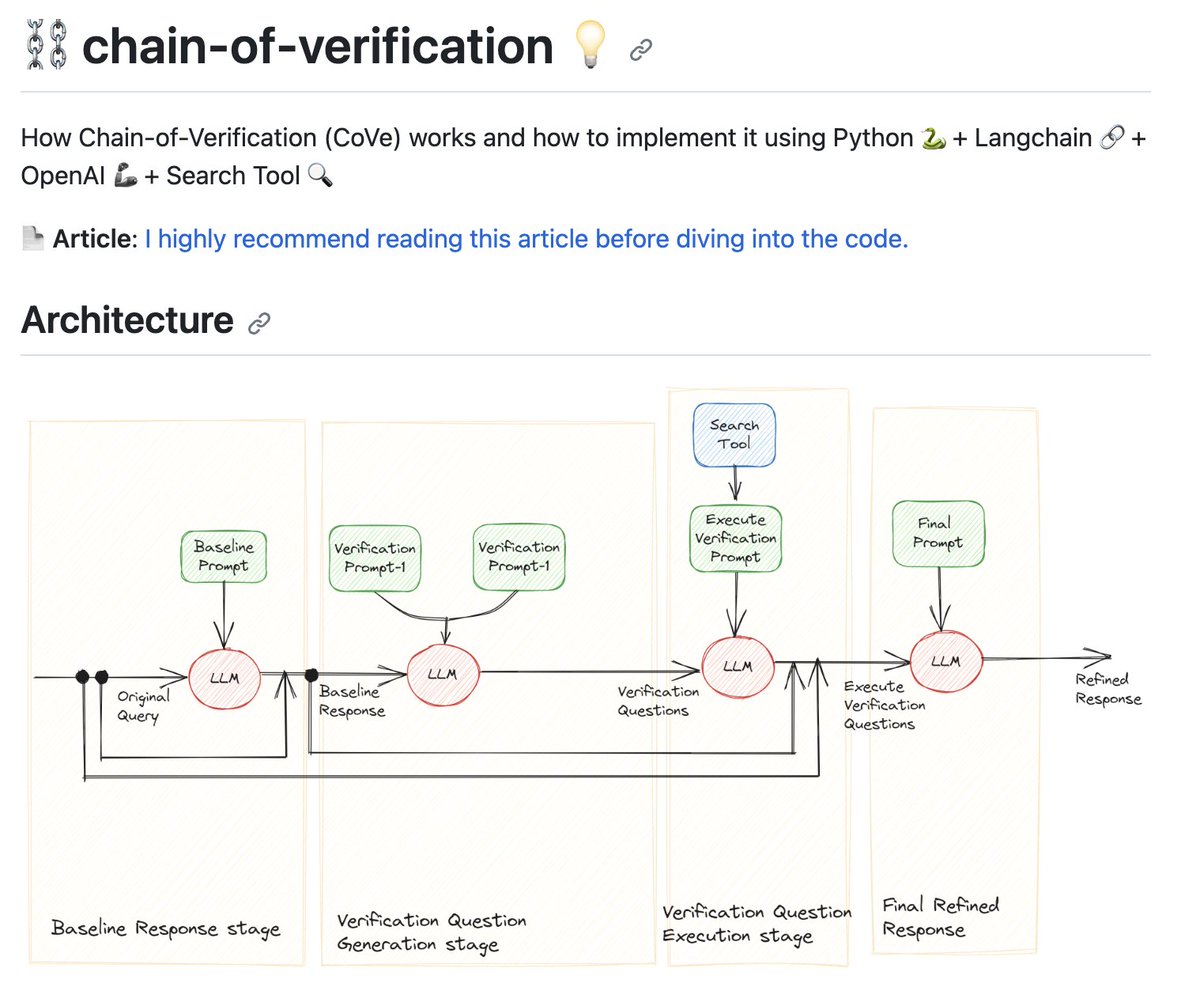 Most important link: the GitHub repo
Most important link: the GitHub repo
 If you want to jump right into it, we've updated the "Getting Started" page for agents to go over all the individual components
If you want to jump right into it, we've updated the "Getting Started" page for agents to go over all the individual components Language models are getting larger and larger context windows
Language models are getting larger and larger context windows Blog:
Blog:  I'll dive into details in this thread, but quick links:
I'll dive into details in this thread, but quick links:
 Before jumping in:
Before jumping in: 


 📄 `format_document`
📄 `format_document`

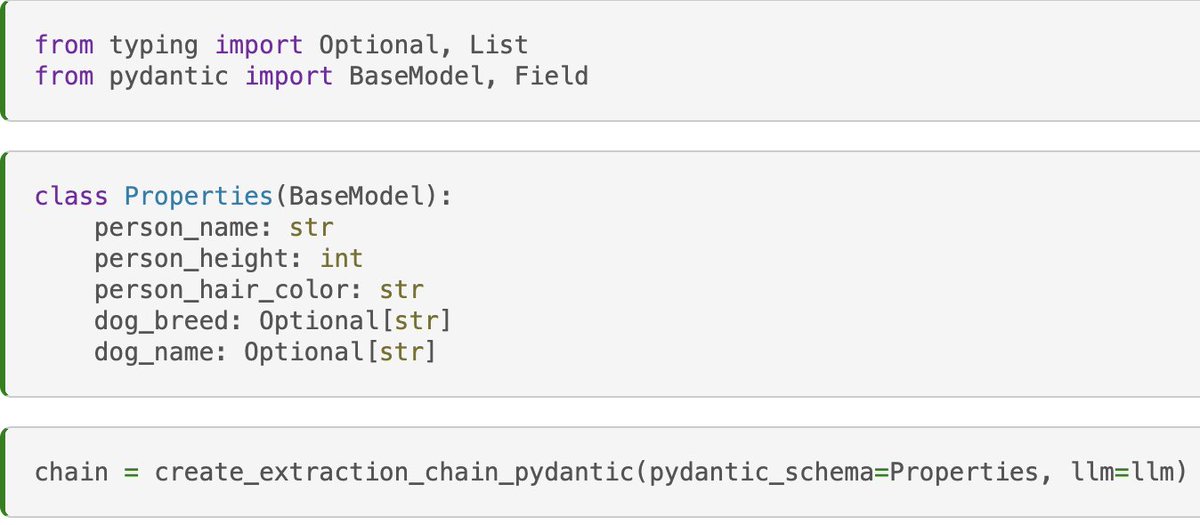


 The way this works is you define a `PipelinePrompt` with two components:
The way this works is you define a `PipelinePrompt` with two components:
 A underrated part of the preprocessing pipeline, proper splitting of text allows for maintaining semantically meaningful chunks
A underrated part of the preprocessing pipeline, proper splitting of text allows for maintaining semantically meaningful chunks Most "chat-your-data" applications involve three steps:
Most "chat-your-data" applications involve three steps:
 My biggest hurdle to using open source models is that I just want to access them behind an API to start
My biggest hurdle to using open source models is that I just want to access them behind an API to start

 Why add this?
Why add this?

 The basic idea of SelfQueryRetriever is simple: given a user query, use an LLM to extract:
The basic idea of SelfQueryRetriever is simple: given a user query, use an LLM to extract: