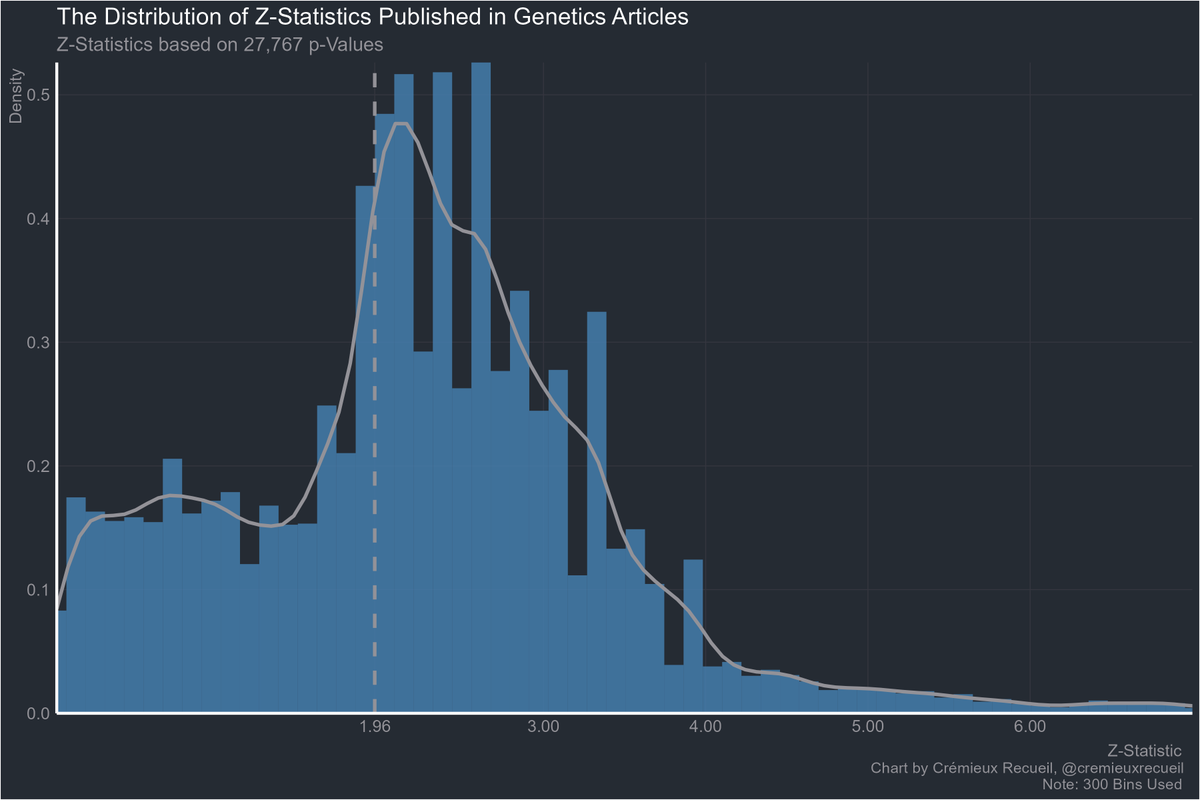
Have you ever wondered how pervasive p-hacking is?
I have a new Substack post that provides an answer to and I even figured out which field does the least of it.
Here are 26 fields ranked in terms of the percentages of their p-values that are dubious.
cremieux.substack.com/p/ranking-fiel…
I have a new Substack post that provides an answer to and I even figured out which field does the least of it.
Here are 26 fields ranked in terms of the percentages of their p-values that are dubious.
cremieux.substack.com/p/ranking-fiel…

You've probably seen how this looks for economics before. There's a large excess of p-values that are just shy of the significance threshold.

But that's nothing. Economics hasn't committed anywhere near the level of sinning medicine has.
Medicine isn't even the worst offender and they're already this bad.
Medicine isn't even the worst offender and they're already this bad.

Since nutrition is what got me interested in this, here's how they fare:
Sorry about the scale, but that's just what p-hacking does. It's just that bad.
Sorry about the scale, but that's just what p-hacking does. It's just that bad.

Now part of this may be down to economists reporting way more tests, and way more values, so their literature doesn't look as bad. But they still tend to focus on the marginal results that pile up near 0.05 even if they publish a bunch of less dodgy p-values.
No field is safe.
No field is safe.
On the subject of p-hacking, this might be one of my favorite pictures showing how it works out: researchers don't report unless p < 0.05 and they prefer positive results.
https://twitter.com/Scientific_Bird/status/1334910800218238976
To avoid confusion from people reporting p-values as inequalities, I have updated the charts in the piece to only include exactly-reported p-values.
Here's medicine, nutrition, plant biology, and computer science.
Here's medicine, nutrition, plant biology, and computer science.




• • •
Missing some Tweet in this thread? You can try to
force a refresh