I built a ChatGPT app that lets you chat with any codebase!
99% of projects just copy/paste Langchain tutorials. This goes well beyond that.
Here's how I built it:
99% of projects just copy/paste Langchain tutorials. This goes well beyond that.
Here's how I built it:
I built it to work with the Twitter codebase, but it's effortless to swap in any other repository.
1. Embedding the code
2. Query + prompt the model
3. Pull in relevant context
4. Repeat steps 2+3
That's all created with a Pinecone vector DB and a FastAPI backend.
Let's start!
1. Embedding the code
2. Query + prompt the model
3. Pull in relevant context
4. Repeat steps 2+3
That's all created with a Pinecone vector DB and a FastAPI backend.
Let's start!
1. Embedding the code
It's 82 LOC, but it could probably be ~50-60.
In short, the process is:
1. Pull the codebase from GitHub
2. Iterate over the files, ignoring images, etc.
3. Split each file into chunks
4. Embed each chunk
Pretty standard, but I added a couple twists.
It's 82 LOC, but it could probably be ~50-60.
In short, the process is:
1. Pull the codebase from GitHub
2. Iterate over the files, ignoring images, etc.
3. Split each file into chunks
4. Embed each chunk
Pretty standard, but I added a couple twists.
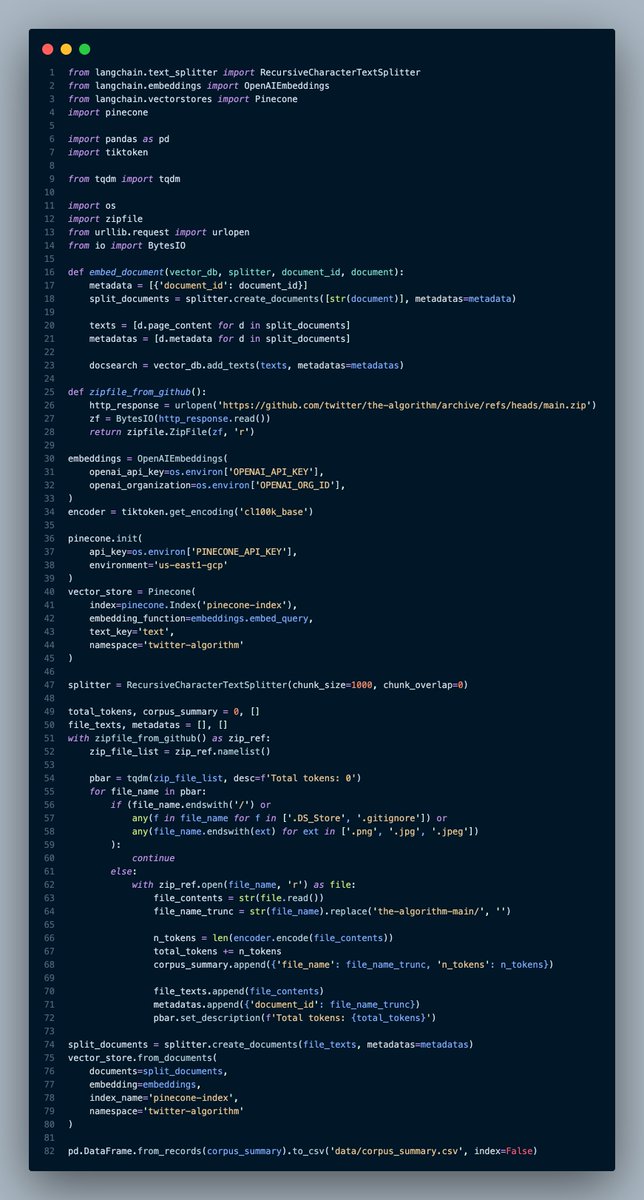
Rather than storing the code on disk, I just loaded it into memory and looped over the zip archive.
I also added a loading bar w/ token counting for cost estimation.
You could comment out the embedding if you just wanted the estimate.
Now we need to split the files.
I also added a loading bar w/ token counting for cost estimation.
You could comment out the embedding if you just wanted the estimate.
Now we need to split the files.
99% of tutorials just split on characters.
But, code is very structured and newline tokens are very useful to split on.
Langchain's RecursiveCharacterTextSplitter helps us with that.
But, code is very structured and newline tokens are very useful to split on.
Langchain's RecursiveCharacterTextSplitter helps us with that.
It prefers first to split on double newlines, then single newlines, and only breaking up words as a last resort.
That means that functions, variable groups, imports, and other "like" code usually stay together nicely without unnecessary breaks.
Now we need to embed the chunks.
That means that functions, variable groups, imports, and other "like" code usually stay together nicely without unnecessary breaks.
Now we need to embed the chunks.
I'm using OpenAI Ada embeddings.
There are *huge* tradeoffs with this.
Using an API is very advantageous because we don't have to manage/pay for the GPUs to run our own embeddings.
Even better, we don't have to manage a GPU server to embed queries using the same model.
But...
There are *huge* tradeoffs with this.
Using an API is very advantageous because we don't have to manage/pay for the GPUs to run our own embeddings.
Even better, we don't have to manage a GPU server to embed queries using the same model.
But...
Ada embeddings are notably inferior to purpose-built, encoder-only or encoder-decoder models.
Models like ColBERT and hybrid methods are the state-of-the-art (check out this thread for more
You have to decide what makes more sense for your application.
Models like ColBERT and hybrid methods are the state-of-the-art (check out this thread for more
https://twitter.com/marktenenholtz/status/1651194444631379969?s=20)
You have to decide what makes more sense for your application.
Finally, we throw those embeddings in a Pinecone index.
Some thoughts here:
1. You don't always need a vector DB. I just felt like using one here. np.array could be sufficient for you.
2. I chose to store metadata+full text in the vector DB. This is probably a bad idea (cont)
Some thoughts here:
1. You don't always need a vector DB. I just felt like using one here. np.array could be sufficient for you.
2. I chose to store metadata+full text in the vector DB. This is probably a bad idea (cont)
(cont) Instead, larger apps should store a UUID as a primary key and use that to query a traditional DB. Storage is precious!
3. I chose Pinecone b/c they have a free tier. Chroma for local embeddings or something else like DeepLake also works.
Now to #2: building the prompt.
3. I chose Pinecone b/c they have a free tier. Chroma for local embeddings or something else like DeepLake also works.
Now to #2: building the prompt.
First, we need to build a system message.
(full prompt in the code at the end)
This will guide the LLM and provide it with the most relevant context for the initial query.
We want to make sure that it doesn't use outside knowledge and that it properly formats any code.
(full prompt in the code at the end)
This will guide the LLM and provide it with the most relevant context for the initial query.
We want to make sure that it doesn't use outside knowledge and that it properly formats any code.

But, we don't just want to slap the most similar code to the question and call it a day.
We want to make sure that we tell ChatGPT where every code snippet comes from.
That lets the model reference its sources later on.
We want to make sure that we tell ChatGPT where every code snippet comes from.
That lets the model reference its sources later on.
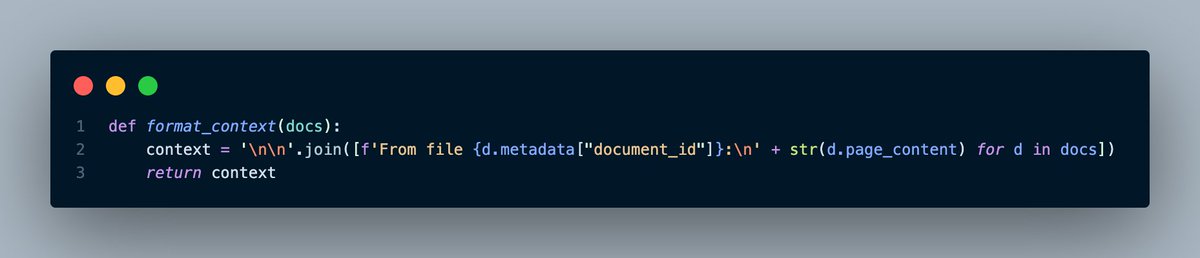
By default, I have it pulling 10 relevant code snippets to built the system message. That'll work well for the first message.
But remember, this is a chat application.
If a user asks a different follow-up question, we'll have to add more context (we'll see that later).
But remember, this is a chat application.
If a user asks a different follow-up question, we'll have to add more context (we'll see that later).
Great, we've done all 3 major steps!
Now we need to orchestrate it into a chatting function.
Here's the code I used:
Now we need to orchestrate it into a chatting function.
Here's the code I used:
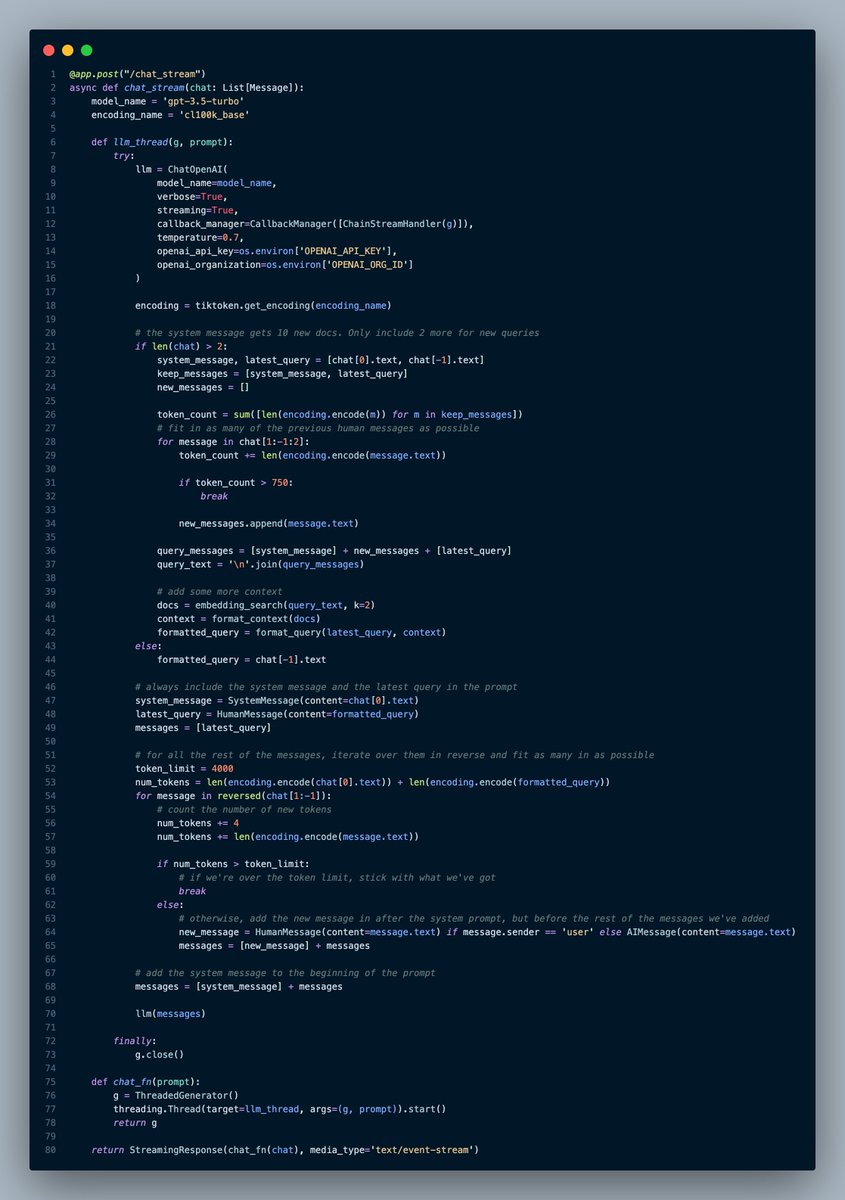
That looks like a lot, but it's only because of the complexity of building an asynchronous streaming endpoint.
(I wrote a whole thread on that here:
Let's go over just the important parts for prompting ChatGPT.
(I wrote a whole thread on that here:
https://twitter.com/marktenenholtz/status/1648657715940691969?s=20)
Let's go over just the important parts for prompting ChatGPT.
First, I decided to keep as many of the human questions as possible.
If we're just seeing the first question, then we only need to initial question from the user.
If not, we need to keep the system message and up to 750 tokens of user questions (token limits!).
But why?
If we're just seeing the first question, then we only need to initial question from the user.
If not, we need to keep the system message and up to 750 tokens of user questions (token limits!).
But why?
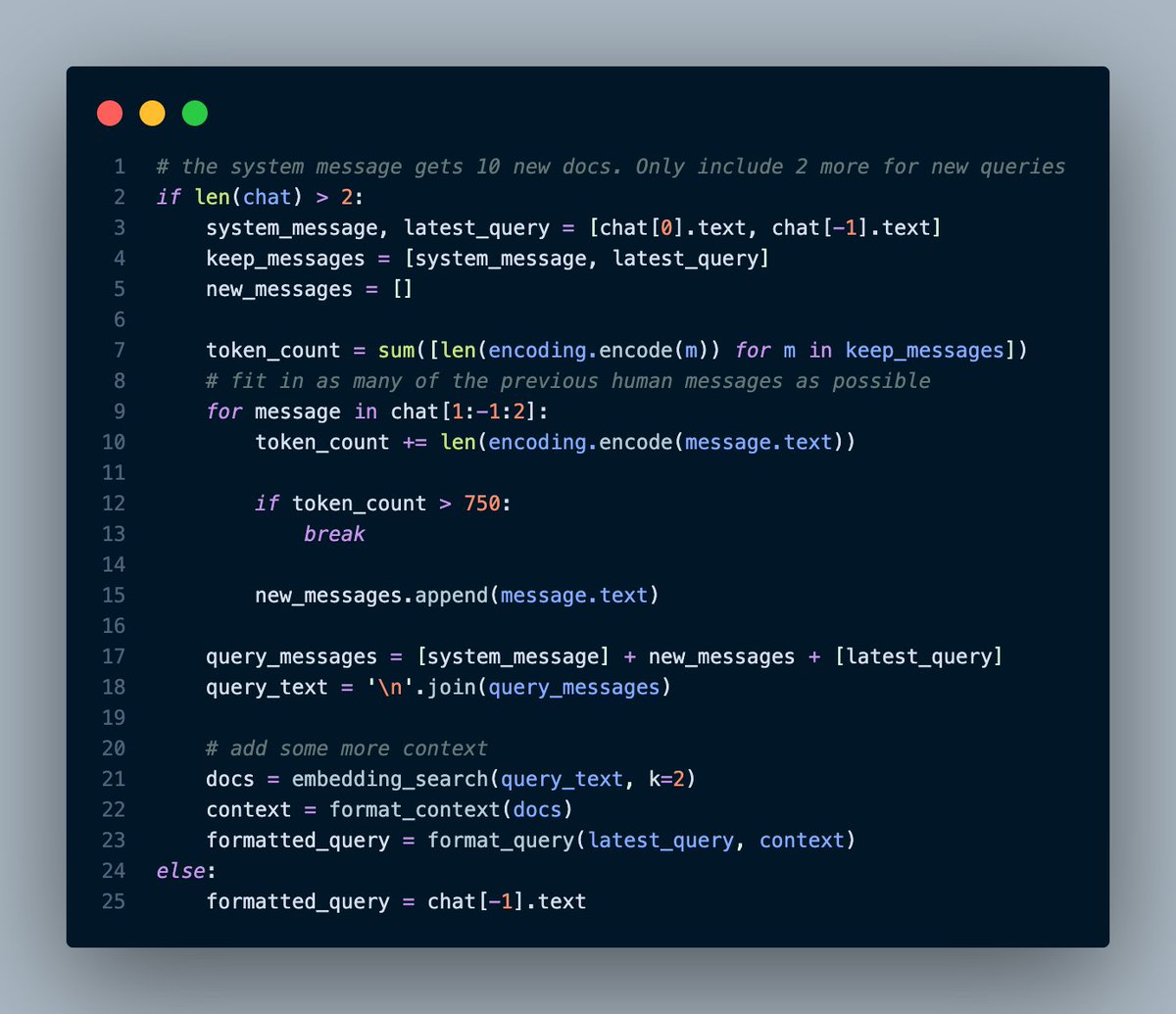
Well, we want to make sure that, in case the conversation changes directions, we always add more relevant code snippets to the conversation.
Adding the previous queries helps that by contextualizing the user question with more meaning.
This is a design decision, but it helped!
Adding the previous queries helps that by contextualizing the user question with more meaning.
This is a design decision, but it helped!
For clarity:
This just means that new code snippets are the ones that are most similar to the concatenation of all previous user queries, not just the most recent.
But, we won't necessarily use all of these messages for question answering.
That comes next!
This just means that new code snippets are the ones that are most similar to the concatenation of all previous user queries, not just the most recent.
But, we won't necessarily use all of these messages for question answering.
That comes next!
Now, we need to decide what context to keep for question answering.
Here's the code that determines which messages to include in our chat history.
We need to:
1. Not go over the token limit
2. Avoid losing important context
Here's the code that determines which messages to include in our chat history.
We need to:
1. Not go over the token limit
2. Avoid losing important context
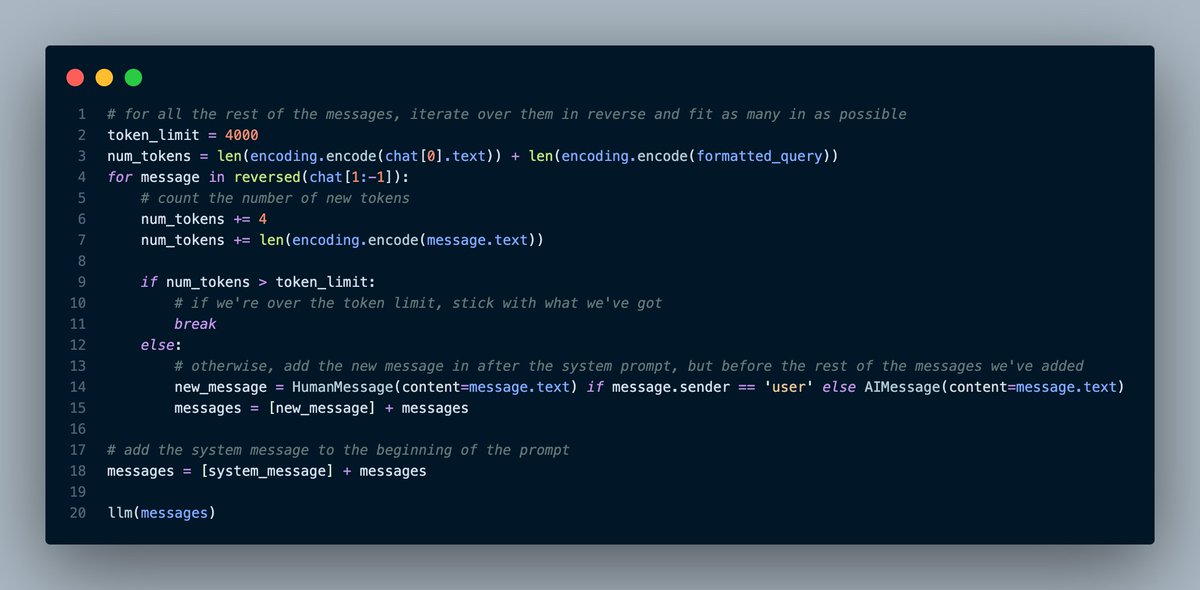
First, we need to figure out how many tokens are in the two messages that we *must* keep: the system message (with our initial code snippets) and the latest user question (with added context).
After that, we want to add in messages in the middle one at a time.
After that, we want to add in messages in the middle one at a time.
Honestly, there are a bunch of ways of doing this.
I chose to keep as many tokens worth of the most recent other messages (to leave room for the system message, query, and newly-added context). Our limit is ~4000 for gpt-3.5-turbo.
There are fancier ways to do this, though.
I chose to keep as many tokens worth of the most recent other messages (to leave room for the system message, query, and newly-added context). Our limit is ~4000 for gpt-3.5-turbo.
There are fancier ways to do this, though.
For instance, you could keep the most similar context to the newest question using embeddings.
This filtered chat history is what's actually fed into ChatGPT.
Finally, we call the OpenAI API, and we're off!
This filtered chat history is what's actually fed into ChatGPT.
Finally, we call the OpenAI API, and we're off!
The whole process repeats, never going over the token limit + never losing the system message.
If you're curious to see the full code, it's right here (in the backend directory): github.com/mtenenholtz/ch…
It's also hosted here: chat-twitter.vercel.app
Let me know what you think!
If you're curious to see the full code, it's right here (in the backend directory): github.com/mtenenholtz/ch…
It's also hosted here: chat-twitter.vercel.app
Let me know what you think!
• • •
Missing some Tweet in this thread? You can try to
force a refresh