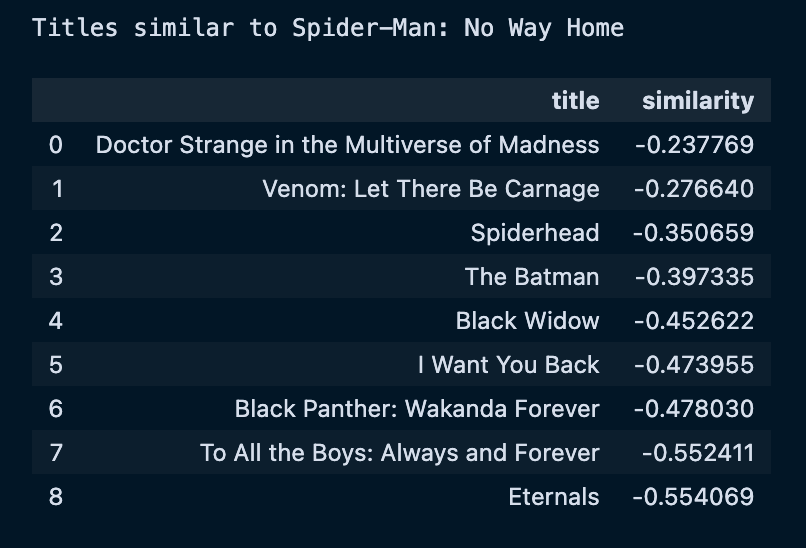
Now there are much smaller models that beat GPT-3, and some models that arguably (ARGUABLY) come close to GPT-3.5-turbo.
Now there are much smaller models that beat GPT-3, and some models that arguably (ARGUABLY) come close to GPT-3.5-turbo.






 The most common loss function in time-series models is MSE.
The most common loss function in time-series models is MSE.