New paper: On the unreasonable effectiveness of LLMs for causal inference.
GPT4 achieves new SoTA on a wide range of causal tasks: graph discovery (97%, 13 pts gain), counterfactual reasoning (92%, 20 pts gain) & actual causality.
How is this possible?🧵
arxiv.org/abs/2305.00050
GPT4 achieves new SoTA on a wide range of causal tasks: graph discovery (97%, 13 pts gain), counterfactual reasoning (92%, 20 pts gain) & actual causality.
How is this possible?🧵
arxiv.org/abs/2305.00050
LLMs do so by bringing in a new kind of reasoning based on text & metadata. We call it knowledge-based causal reasoning, distinct from existing data-based methods.
Essentially, LLMs approximate human domain knowledge: a big win for causal tasks that often depend on human input.
Essentially, LLMs approximate human domain knowledge: a big win for causal tasks that often depend on human input.
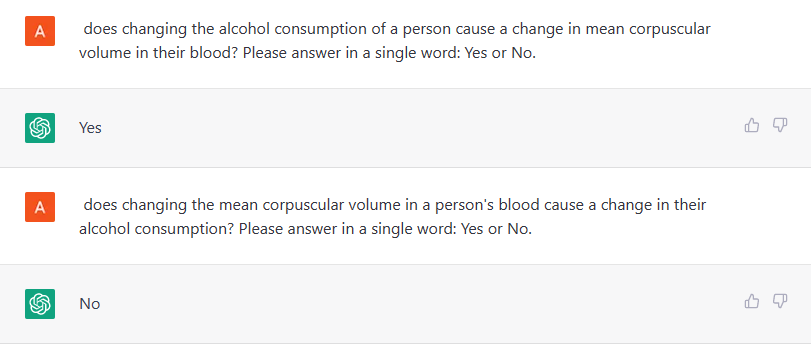
On pairwise causal discovery, LLMs like GPT3.5/4 obtain >90% accuracy on detecting causal direction (does A cause B?) on the Tubingen benchmark spanning physics, engg, medicine & soil science. The prompt uses variable names & asks the more likely causal direction. Prev SoTA: 83% 

We obtain similar high accuracies on a specialized medical dataset on neuropathic pain. Here the relationships are not at all obvious, yet GPT-4 obtains 96% accuracy in detecting the correct direction.
The choice of prompt has a big impact, as we describe in the paper.
The choice of prompt has a big impact, as we describe in the paper.

Let's move to a harder task: discovering the full causal graph. Prev. work on the medical dataset predicted LLMs won't work (low F1 score=0.1).
Not quite. With simple prompt tuning, F1 shoots up to 0.7. On an arctic science dataset, GPT-4 outperforms recent deep learning methods
Not quite. With simple prompt tuning, F1 shoots up to 0.7. On an arctic science dataset, GPT-4 outperforms recent deep learning methods
Of course, LLMs make silly errors too (e.g., answering that an abalone's diameter causes its age), and we wouldn't want to trust them yet for critical applications.
But the surprising part is how **few** such errors are, on datasets spanning a (good) range of human knowledge.
But the surprising part is how **few** such errors are, on datasets spanning a (good) range of human knowledge.

There is a big implication for causal effect inference: rather than relying on humans to provide the full graph, LLMs can be used to create candidate graphs or help critique graphs.
This is great, since building the graph is perhaps the most challenging part of causal analysis.
This is great, since building the graph is perhaps the most challenging part of causal analysis.
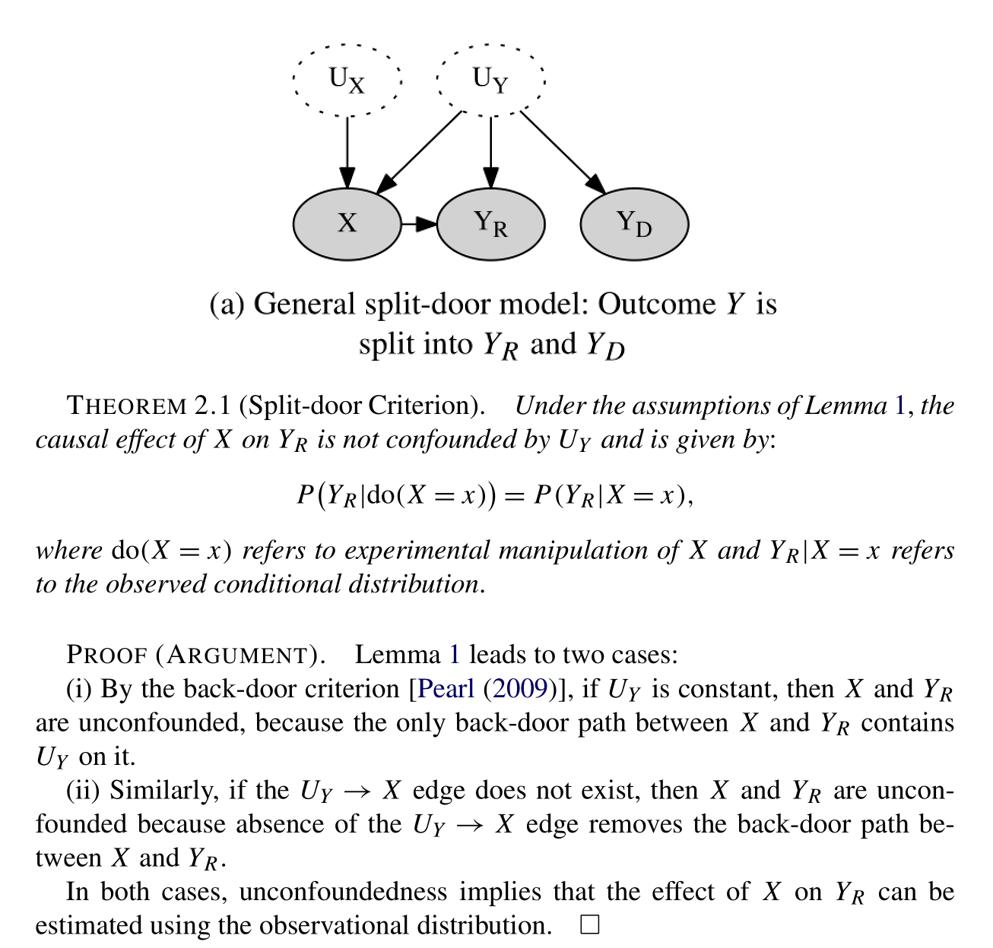
The second part of the paper focuses on counterfactual reasoning. Can LLMs infer cause and effect from natural language?
Relates to actual causality, a notoriously challenging task due to human factors in judging the relevant variables and their causal contribution.
Relates to actual causality, a notoriously challenging task due to human factors in judging the relevant variables and their causal contribution.
Here too, GPT3.5/4 outperform existing algorithms. On the CRASS benchmark on predicting outcomes under everyday counterfactual situations, GPT-4 obtains 92% accuracy, 20 pts higher than previous SoTA.
Ex.: "A woman sees a fire. What would happen if a woman had touched the fire?"
Ex.: "A woman sees a fire. What would happen if a woman had touched the fire?"
Next, can LLMs infer necessary and sufficient causes? We consider 15 challenging vignettes from actual causality lit. GPT3.5 fails here, but GPT4 still achieves 86% accuracy.
Remarkable, because we now have a tool that can go directly from messy, human text to causal attribution
Remarkable, because we now have a tool that can go directly from messy, human text to causal attribution
While LLMs can infer the relevant variables from text, assessing human factors (e.g., is an action considered normal or not?) remains a hard task for LLMs. GPT-3.5/4 obtain poor accuracy on a causal judgment task from Big Bench that requires an algorithm to match human intuition.
Overall, LLMs bring a fresh, new capability to causal inference, complementary to existing methods. We see a promising future for causality where LLMs can assist and automate various steps in causal inference, seamlessly transitioning between knowledge and data-based reasoning.

That said, LLMs are not perfect & have unpredictable failure modes. Robustness checks also show memorized causal relationships that partially explain performance.
So we still need principled causal algorithms. The upshot is that LLMs can be used to expand their reach & capability
So we still need principled causal algorithms. The upshot is that LLMs can be used to expand their reach & capability

Looking ahead, this work raises more questions than it answers. Many research questions on how LLMs can help reinvent or augment existing causal tasks, and how we can make LLMs reasoning more robust.
Paper: arxiv.org/abs/2305.00050
w/ @emrek @osazuwa @ChenhaoTan
Paper: arxiv.org/abs/2305.00050
w/ @emrek @osazuwa @ChenhaoTan
On a personal note, I was a wild skeptic when I started looking at LLMs. But frankly, the results are too good to ignore!
Welcome your feedback. Especially if you have ideas on which causal tasks/examples you expect LLMs to fail, do let us know. We can try them and add to paper.
Welcome your feedback. Especially if you have ideas on which causal tasks/examples you expect LLMs to fail, do let us know. We can try them and add to paper.
• • •
Missing some Tweet in this thread? You can try to
force a refresh