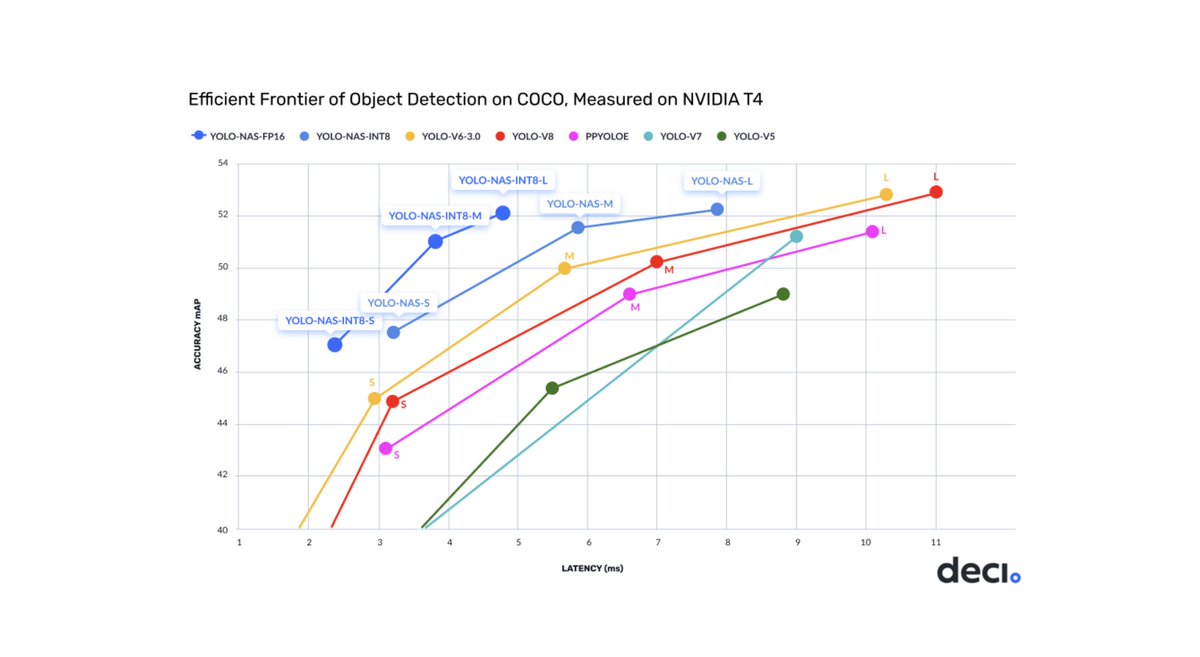
The recently-proposed YOLO-NAS object detector achieves a mean average-precision (mAP) of 52 on Microsoft COCO with <5 ms latency, while The YOLOv1 requires 30-50ms latency to achieve comparable mAP. Here are the three key ideas that make YoloNAS fast and performant… 🧵 [1/8] 
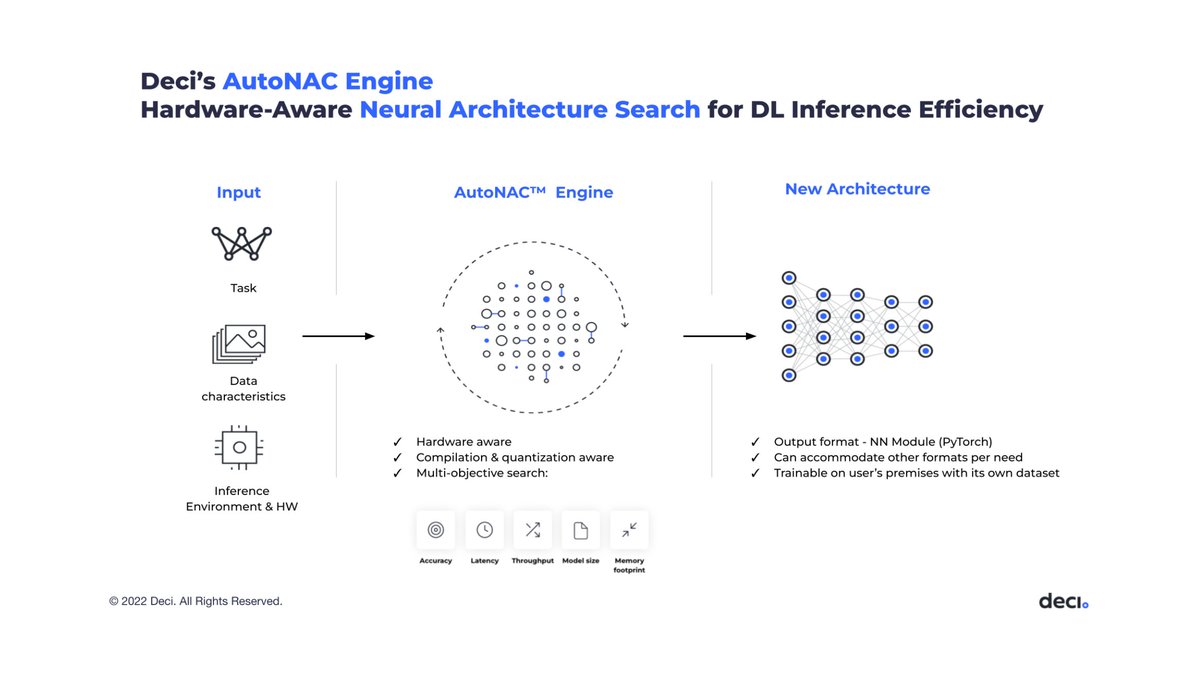
1. Neural Architecture Search (NAS)
Authors of YOLO-NAS define a space of 10^14 possible architecture configurations inspired by YOLO-v6/v8, then discover a suite of models with different performance/latency tradeoffs by using a hardware-aware NAS algorithm called AutoNAC. [2/8]
Authors of YOLO-NAS define a space of 10^14 possible architecture configurations inspired by YOLO-v6/v8, then discover a suite of models with different performance/latency tradeoffs by using a hardware-aware NAS algorithm called AutoNAC. [2/8]
2. Model Quantization
YOLO-NAS adopts a complex quantization strategy to minimize latency within the resulting model. First, YOLO-NAS adopts a quantization-aware structure within each of its layers and leverages quantization-aware training.
🔗: arxiv.org/abs/2212.01593
[3/8]
YOLO-NAS adopts a complex quantization strategy to minimize latency within the resulting model. First, YOLO-NAS adopts a quantization-aware structure within each of its layers and leverages quantization-aware training.
🔗: arxiv.org/abs/2212.01593
[3/8]
YOLO-NAS also adopts a hybrid/dynamic quantization strategy that avoids quantizing layers that damage performance. As a result, YOLO-NAS loses ~.5 mAP during post-training quantization, whereas most other models see a 1-2 point degradation in mAP. [4/8]
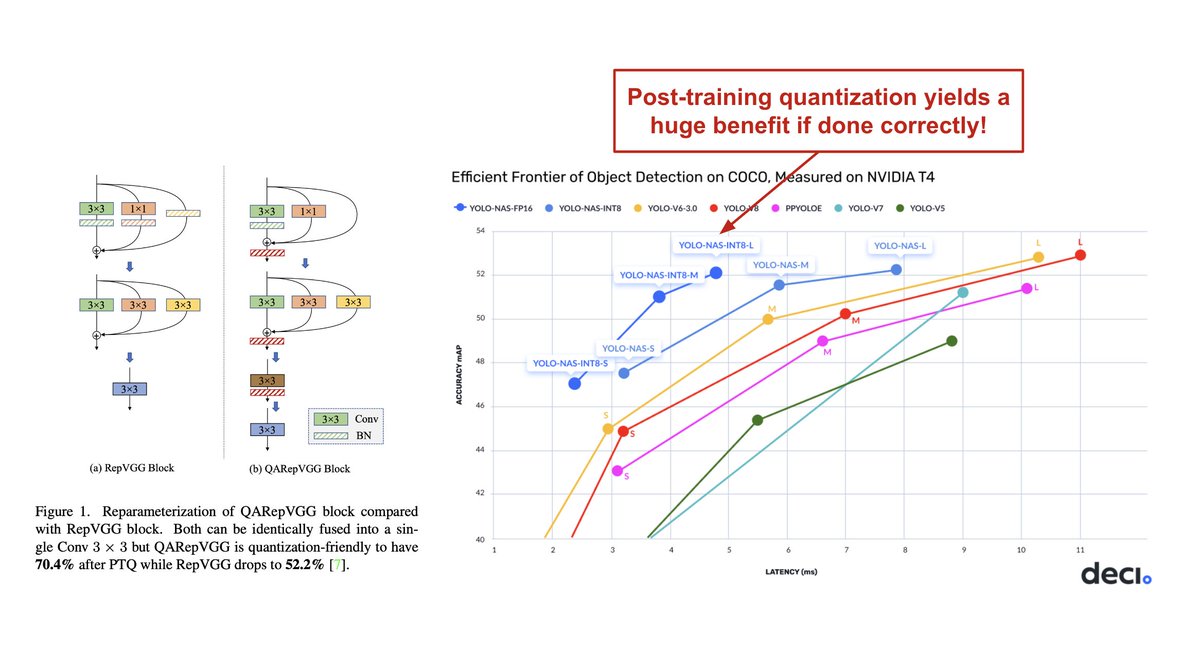
For an in-depth, recent analysis of post-training quantization, I would recommend the following paper. It provides a ton of awesome context and up-to-date material on the topic that is both useful and accessible.
🔗: arxiv.org/abs/2304.09785
[5/8]
🔗: arxiv.org/abs/2304.09785
[5/8]
3. Training Regime
YOLO-NAS is trained in three parts: pre-training over the Object365, training over pseudo/weakly-labeled data, and knowledge distillation from a larger model. These components allow the lightweight YOLO-NAS model to punch above its weight in performance. [6/8]
YOLO-NAS is trained in three parts: pre-training over the Object365, training over pseudo/weakly-labeled data, and knowledge distillation from a larger model. These components allow the lightweight YOLO-NAS model to punch above its weight in performance. [6/8]
TL;DR: YOLO-NAS achieves impressive latency (200 FPS even with the largest model!) and performs well relative to other lightweight object detectors. Thanks to my friend @DataScienceHarp for sharing this interesting research with me!
🔗: deci.ai/blog/YOLO-NAS-…
[7/8]
🔗: deci.ai/blog/YOLO-NAS-…
[7/8]
YOLO-NAS is completely open-source, so you can access the model, look at training or fine-tuning examples, and read more about how it works on the associated Github page.
🔗: github.com/Deci-AI/super-…
[8/8]
🔗: github.com/Deci-AI/super-…
[8/8]
• • •
Missing some Tweet in this thread? You can try to
force a refresh